Baru-baru ini, Laboratorium Kecerdasan Buatan Tencent meluncurkan model baru yang disebut VTA-LDM, yang dirancang untuk mengonversi konten video secara efisien menjadi audio yang konsisten secara semantik dan temporal. Teknologi inti model ini terletak pada "penyelarasan implisit", yang sangat cocok dengan konten audio dan video yang dihasilkan, sehingga sangat meningkatkan kualitas dan skenario penerapan pembuatan audio. Editor Downcodes akan membawa Anda untuk memiliki pemahaman mendalam tentang inovasi dan prospek penerapan model VTA-LDM.
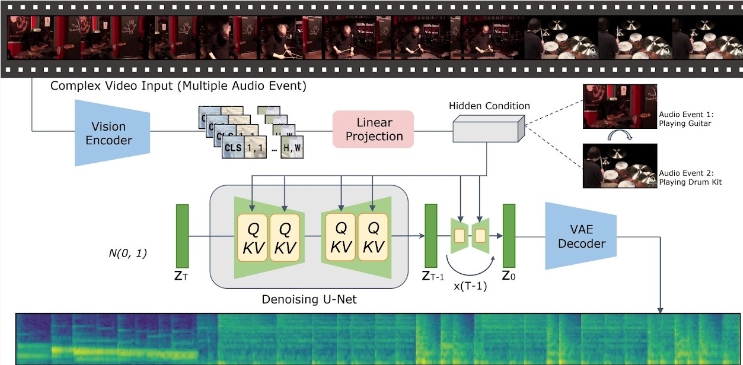
Dengan kemajuan signifikan dalam teknologi pembuatan teks-ke-video, cara menghasilkan konten audio yang konsisten secara semantik dan temporal dari masukan video telah menjadi topik hangat di kalangan peneliti. Baru-baru ini, tim peneliti dari Tencent Artificial Intelligence Laboratory meluncurkan model baru yang disebut "Pembuatan Video ke Audio yang Disejajarkan Secara Implisit" - VTA-LDM, yang bertujuan untuk memberikan solusi pembuatan audio yang efisien.
Pintu masuk proyek: https://top.aibase.com/tool/vta-ldm
Ide inti dari model VTA-LDM adalah untuk mencocokkan konten audio dan video yang dihasilkan secara semantik dan temporal melalui teknologi penyelarasan implisit. Metode ini tidak hanya meningkatkan kualitas pembuatan audio, namun juga memperluas skenario penerapan teknologi pembuatan video. Tim peneliti melakukan eksplorasi mendalam terhadap desain model dan menggabungkan berbagai cara teknis untuk memastikan keakuratan dan konsistensi audio yang dihasilkan.
Penelitian ini berfokus pada tiga aspek utama: encoder visual, penyematan tambahan, dan teknik augmentasi data. Tim peneliti pertama kali membuat model dasar dan melakukan sejumlah besar eksperimen ablasi atas dasar ini untuk mengevaluasi dampak berbagai encoder visual dan penyematan tambahan pada efek pembangkitan. Hasil eksperimen ini menunjukkan bahwa model ini memiliki kinerja yang baik dalam hal kualitas generasi dan penyelarasan video dan audio secara simultan, sehingga mencapai garis depan teknologi saat ini.
Dalam hal inferensi, pengguna hanya perlu memasukkan klip video ke direktori data yang ditentukan dan menjalankan skrip inferensi yang disediakan untuk menghasilkan konten audio yang sesuai. Tim peneliti juga menyediakan seperangkat alat untuk membantu pengguna menggabungkan audio yang dihasilkan dengan video asli, sehingga semakin meningkatkan kenyamanan aplikasi.
Model VTA-LDM saat ini menyediakan beberapa versi model berbeda untuk memenuhi kebutuhan penelitian yang berbeda. Model-model ini mencakup model dasar dan berbagai model yang disempurnakan, yang bertujuan untuk memberikan pilihan fleksibel kepada pengguna untuk beradaptasi dengan berbagai eksperimen dan skenario aplikasi.
Peluncuran model VTA-LDM menandai kemajuan penting dalam bidang pembuatan video ke audio. Para peneliti berharap dapat menggunakan model ini untuk mendorong pengembangan teknologi terkait dan menciptakan kemungkinan penerapan yang lebih kaya.
## Sorotan:
Kemunculan model VTA-LDM telah membawa terobosan baru dalam bidang pembuatan video dan audio. Metode pengoperasiannya yang efisien dan nyaman serta fungsinya yang kuat menunjukkan prospek penerapan yang lebih luas di masa depan. Dipercaya bahwa dengan terus berkembangnya teknologi, model VTA-LDM akan memainkan peran penting di lebih banyak bidang.