Editor downcode menghadirkan berita besar! Teknologi akselerasi Transformer revolusioner FlashAttention-3 secara resmi dirilis! Teknologi ini akan merevolusi kecepatan inferensi dan biaya model bahasa besar (LLM), sehingga mencapai peningkatan efisiensi yang belum pernah terjadi sebelumnya. Kecepatannya meningkat 1,5 hingga 2 kali lipat, pengoperasian presisi rendah (FP8) mempertahankan akurasi tinggi, dan kemampuan pemrosesan teks panjang ditingkatkan secara signifikan, yang akan menghadirkan kemungkinan baru untuk aplikasi AI! Mari kita lihat lebih dekat terobosan teknologi ini.
Teknologi akselerasi Transformer baru FlashAttention-3 telah dirilis! Ini bukan sekadar peningkatan, ini menandai peningkatan tajam dalam kecepatan inferensi dan penurunan biaya model bahasa besar (LLM) kami!
Mari kita bahas tentang FlashAttention-3 ini terlebih dahulu. Dibandingkan dengan versi sebelumnya, ini hanyalah perubahan kecil:
Pemanfaatan GPU telah meningkat pesat: menggunakan FlashAttention-3 untuk melatih dan menjalankan model bahasa besar, kecepatannya langsung berlipat ganda, 1,5 hingga 2 kali lebih cepat. Efisiensi ini luar biasa!
Presisi rendah, kinerja tinggi: Ini juga dapat berjalan dengan angka presisi rendah (FP8) dengan tetap menjaga akurasi. Apa artinya menurunkan biaya tanpa mengurangi kinerja!
Memproses teks panjang sangatlah mudah: FlashAttention-3 sangat meningkatkan kemampuan model AI untuk memproses teks panjang, yang tidak terbayangkan sebelumnya.
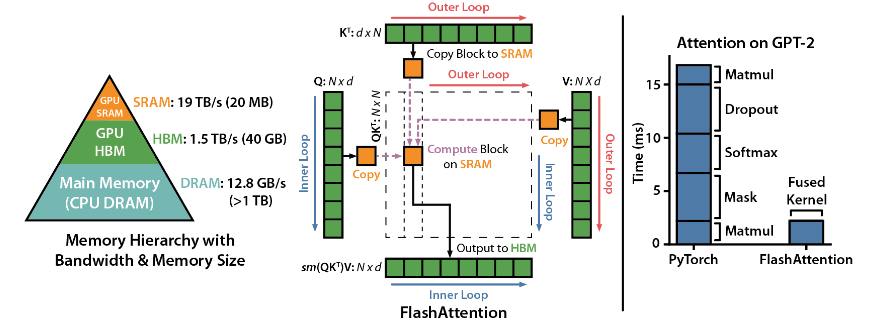
FlashAttention adalah perpustakaan sumber terbuka yang dikembangkan oleh Dao-AILab. Ini didasarkan pada dua makalah kelas berat dan menyediakan implementasi mekanisme perhatian yang dioptimalkan dalam model pembelajaran mendalam. Pustaka ini sangat cocok untuk memproses kumpulan data berskala besar dan urutan yang panjang. Terdapat hubungan linier antara konsumsi memori dan panjang urutan, yang jauh lebih efisien daripada hubungan kuadrat tradisional.
Sorotan Teknis:
Dukungan teknologi canggih: perhatian lokal, propagasi mundur deterministik, ALiBi, dll. Teknologi ini membawa kekuatan ekspresif dan fleksibilitas model ke tingkat yang lebih tinggi.
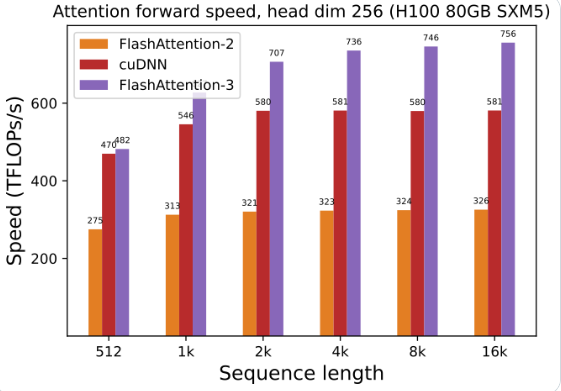
Pengoptimalan GPU Hopper: FlashAttention-3 telah secara khusus mengoptimalkan dukungannya untuk GPU Hopper, dan kinerjanya telah ditingkatkan lebih dari satu setengah poin.
Mudah dipasang dan digunakan: mendukung CUDA11.6 dan PyTorch1.12 atau lebih tinggi, mudah dipasang dengan perintah pip di sistem Linux. Meskipun pengguna Windows mungkin memerlukan lebih banyak pengujian, ini pasti patut untuk dicoba.
Fungsi inti:
Kinerja yang efisien: Algoritme yang dioptimalkan sangat mengurangi kebutuhan komputasi dan memori, terutama untuk pemrosesan data urutan panjang, dan peningkatan kinerja terlihat dengan mata telanjang.
Pengoptimalan memori: Dibandingkan dengan metode tradisional, FlashAttention mengonsumsi lebih sedikit memori, dan hubungan linier membuat penggunaan memori tidak lagi menjadi masalah.
Fitur lanjutan: Mengintegrasikan berbagai teknologi canggih sangat meningkatkan kinerja model dan cakupan aplikasi.
Kemudahan penggunaan dan kompatibilitas: Instalasi sederhana dan panduan penggunaan, ditambah dengan dukungan untuk beberapa arsitektur GPU, memungkinkan FlashAttention-3 dengan cepat diintegrasikan ke dalam berbagai proyek.
Alamat proyek: https://github.com/Dao-AILab/flash-attention
Kemunculan FlashAttention-3 tidak diragukan lagi akan mempercepat penerapan dan pengembangan model bahasa berskala besar serta membawa terobosan baru di bidang kecerdasan buatan. Kinerjanya yang efisien dan kemudahan penggunaannya menjadikannya pilihan ideal bagi pengembang. Cepat dan alami!