Editor Downcodes akan mengungkapkan kebenaran tentang model bahasa visual (VLM) kepada Anda! Apakah menurut Anda VLM dapat "memahami" gambar seperti manusia? Kenyataannya tidak sesederhana itu. Artikel ini akan mengeksplorasi secara mendalam keterbatasan VLM dalam pemahaman gambar, dan melalui serangkaian hasil eksperimen, menunjukkan kesenjangan besar antara VLM dan kemampuan visual manusia. Apakah Anda siap untuk mengubah pemahaman Anda tentang VLM?
Semua orang pasti pernah mendengar tentang model bahasa visual (VLM). Ahli cilik di bidang AI ini tidak hanya bisa membaca teks, tapi juga "melihat" gambar. Namun kenyataannya tidak demikian. Sekarang, mari kita lihat “celana dalam” mereka untuk melihat apakah mereka benar-benar dapat “melihat” dan memahami gambaran seperti kita manusia.
Pertama-tama, saya harus memberi Anda beberapa ilmu populer tentang apa itu VLM. Sederhananya, mereka adalah model bahasa besar, seperti GPT-4o dan Gemini-1.5Pro, yang berkinerja sangat baik dalam pemrosesan gambar dan teks, dan bahkan mencapai skor tinggi dalam banyak tes pemahaman visual. Namun jangan biarkan skor tinggi ini membodohi Anda, hari ini kita akan melihat apakah skor tersebut benar-benar luar biasa.
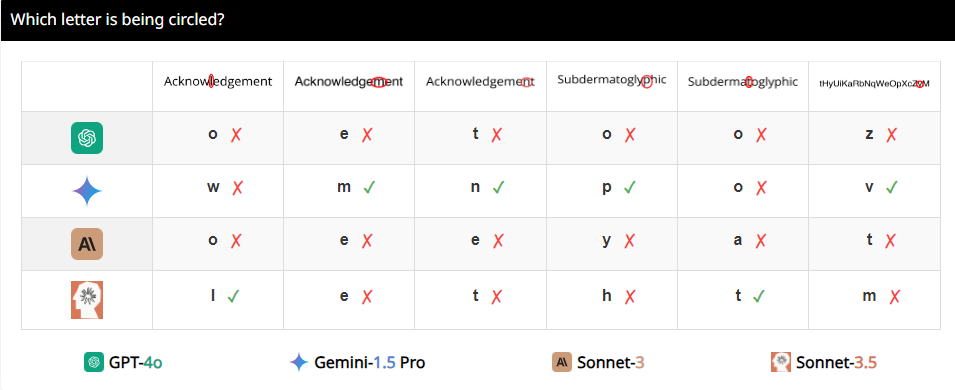
Para peneliti merancang serangkaian tes yang disebut BlindTest, yang berisi tujuh tugas yang sangat sederhana bagi manusia. Misalnya, menentukan apakah dua lingkaran saling tumpang tindih, apakah dua garis berpotongan, atau menghitung berapa banyak lingkaran yang ada pada logo Olimpiade. Apakah sepertinya tugas-tugas ini dapat dengan mudah ditangani oleh anak-anak taman kanak-kanak? Namun izinkan saya memberi tahu Anda, kinerja VLM ini tidak terlalu mengesankan.
Hasilnya mengejutkan. Rata-rata akurasi dari apa yang disebut model canggih di BlindTest hanya 56,20%, dan Sonnet-3.5 terbaik memiliki akurasi 73,77%. Ini seperti seorang siswa berprestasi yang mengaku bisa masuk ke Universitas Tsinghua dan Universitas Peking, namun ternyata dia bahkan tidak bisa mengerjakan soal matematika sekolah dasar dengan benar.

Mengapa hal ini terjadi? Peneliti menganalisis bahwa mungkin karena VLM seperti miopia ketika memproses gambar dan tidak dapat melihat detail dengan jelas. Meskipun secara kasar mereka dapat melihat tren gambar secara keseluruhan, namun jika menyangkut informasi spasial yang tepat, seperti apakah dua grafik berpotongan atau tumpang tindih, mereka merasa bingung.
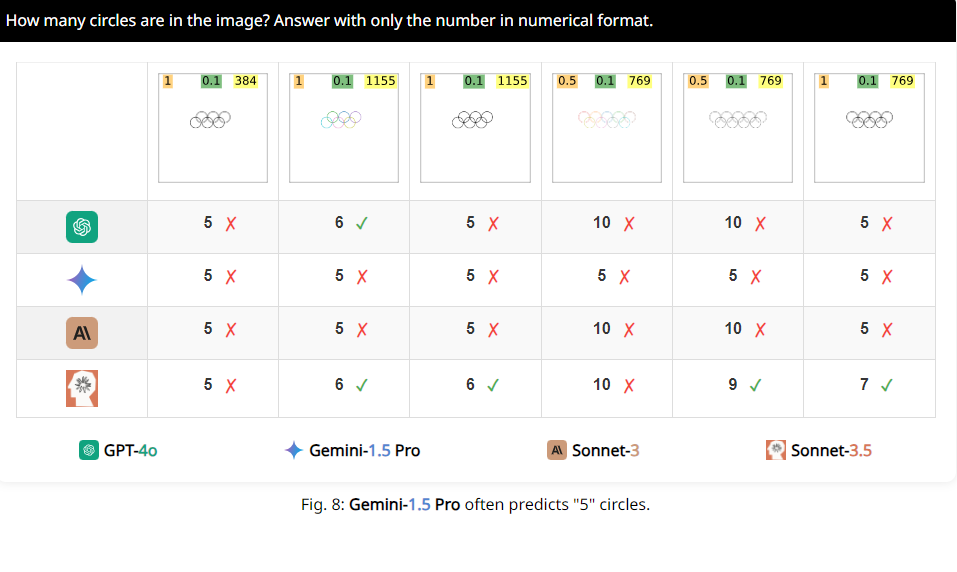
Misalnya, para peneliti meminta VLM untuk menentukan apakah dua lingkaran saling tumpang tindih, dan menemukan bahwa meskipun kedua lingkaran tersebut sebesar semangka, model ini tetap tidak dapat menjawab pertanyaan dengan 100% akurat. Selain itu, ketika diminta menghitung jumlah lingkaran pada logo Olimpiade, performa mereka sulit digambarkan.
Menariknya lagi, para peneliti juga menemukan bahwa VLM ini tampaknya memiliki preferensi khusus terhadap angka 5 saat menghitung. Misalnya, ketika jumlah lingkaran di logo Olimpiade melebihi 5, mereka cenderung menjawab "5". Hal ini mungkin karena ada 5 lingkaran di logo Olimpiade dan mereka sangat familiar dengan nomor ini.
Oke, setelah mengatakan semua itu, apakah kalian memiliki pemahaman baru tentang VLM yang tampak tinggi ini? Faktanya, mereka masih memiliki banyak keterbatasan dalam pemahaman visual, jauh dari jangkauan manusia. Jadi, lain kali Anda mendengar seseorang mengatakan bahwa AI dapat sepenuhnya menggantikan manusia, Anda mungkin tertawa.
Alamat makalah: https://arxiv.org/pdf/2407.06581
Halaman proyek: https://vlmsareblind.github.io/
Singkatnya, meskipun VLM telah membuat kemajuan yang signifikan dalam bidang pengenalan gambar, kemampuan mereka dalam penalaran spasial yang tepat masih memiliki kekurangan yang besar. Studi ini mengingatkan kita bahwa penilaian terhadap teknologi AI tidak bisa hanya mengandalkan skor tinggi, namun juga memerlukan pemahaman mendalam mengenai keterbatasannya untuk menghindari optimisme buta. Kami menantikan VLM membuat terobosan dalam pemahaman visual di masa depan!