Editor Downcodes akan mengajak Anda mempelajari penelitian terobosan Google DeepMind: Mixture of Experts (MoE). Penelitian ini telah membuat kemajuan revolusioner dalam arsitektur Transformer. Intinya terletak pada mekanisme pengambilan ahli yang efisien parameter yang menggunakan teknologi kunci produk untuk menyeimbangkan biaya komputasi dan jumlah parameter, sehingga sangat meningkatkan potensi model sambil mempertahankan efisiensi. Penelitian ini tidak hanya mengeksplorasi pengaturan MoE yang ekstrim, namun juga membuktikan untuk pertama kalinya bahwa struktur indeks pembelajaran dapat secara efektif diarahkan ke lebih dari satu juta ahli, sehingga membawa kemungkinan-kemungkinan baru di bidang AI.
Model Campuran sejuta ahli yang diusulkan oleh Google DeepMind adalah penelitian yang telah mengambil langkah revolusioner dalam arsitektur Transformer.
Bayangkan sebuah model yang dapat melakukan pengambilan data secara jarang dari satu juta pakar mikro. Apakah ini terdengar seperti alur cerita novel fiksi ilmiah? Tapi itulah yang ditunjukkan oleh penelitian terbaru DeepMind. Inti dari penelitian ini adalah mekanisme pengambilan ahli yang efisien terhadap parameter yang memanfaatkan teknologi kunci produk untuk memisahkan biaya komputasi dari jumlah parameter, sehingga melepaskan potensi yang lebih besar dari arsitektur Transformer sambil mempertahankan efisiensi komputasi.
Hal yang paling menarik dari penelitian ini adalah bahwa penelitian ini tidak hanya mengeksplorasi situasi MoE yang ekstrem, namun juga menunjukkan untuk pertama kalinya bahwa struktur indeks yang dipelajari dapat disalurkan secara efisien ke lebih dari satu juta pakar. Ini seperti menemukan dengan cepat beberapa ahli yang dapat memecahkan masalah dalam jumlah besar, dan semua ini dilakukan berdasarkan premis biaya komputasi yang terkendali.
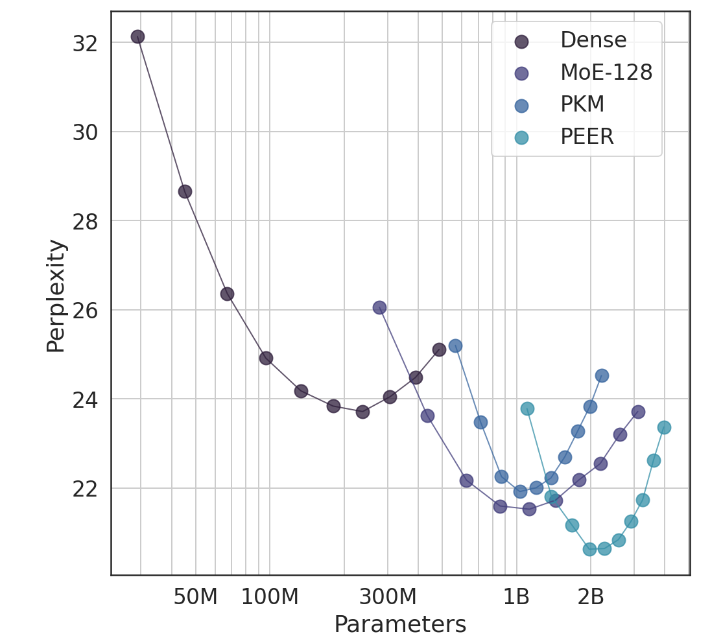
Dalam eksperimen, arsitektur PEER menunjukkan kinerja komputasi yang unggul dan lebih efisien dibandingkan lapisan FFW padat, MoE berbutir kasar, dan memori kunci produk (PKM). Ini bukan hanya kemenangan teoritis, namun juga lompatan besar dalam penerapan praktis. Melalui hasil empiris, kita dapat melihat kinerja PEER yang unggul dalam tugas pemodelan bahasa. Tidak hanya memiliki kompleksitas yang lebih rendah, tetapi juga dalam eksperimen ablasi, dengan menyesuaikan jumlah pakar dan jumlah pakar aktif, kinerja PEER model telah ditingkatkan secara signifikan.
Penulis studi ini, Xu He (Owen), adalah seorang ilmuwan riset di Google DeepMind. Eksplorasi sendirian tidak diragukan lagi telah membawa penemuan baru di bidang AI. Seperti yang ditunjukkannya, melalui metode yang dipersonalisasi dan cerdas, kami dapat meningkatkan tingkat konversi secara signifikan dan mempertahankan pengguna, yang mana hal ini sangat penting dalam bidang AIGC.
Alamat makalah: https://arxiv.org/abs/2407.04153
Secara keseluruhan, penelitian model hibrida jutaan pakar Google DeepMind memberikan ide-ide baru untuk pembangunan model bahasa berskala besar. Mekanisme pengambilan pakar yang efisien dan hasil eksperimen yang luar biasa menunjukkan potensi besar untuk pengembangan model AI di masa depan. Editor Downcodes menantikan hasil penelitian terobosan serupa lainnya!