Dalam beberapa tahun terakhir, inovasi dalam model bahasa besar (LLM) bermunculan satu demi satu, terus-menerus menantang batasan arsitektur yang ada. Editor Downcodes mengetahui bahwa para peneliti dari Stanford, UCSD, UC Berkeley dan Meta bersama-sama mengusulkan arsitektur baru yang disebut TTT (Test-Time-Training layer). Dengan desain terobosannya, diharapkan dapat sepenuhnya mengubah pemahaman kita tentang bahasa model dikenali dan diterapkan. Dengan menggabungkan keunggulan RNN dan Transformer secara cerdik, arsitektur TTT secara signifikan meningkatkan kemampuan ekspresif model sekaligus memastikan kompleksitas linier. Ia bekerja dengan sangat baik saat memproses teks panjang, memberikan wawasan baru pada bidang-bidang seperti kemungkinan pemodelan video panjang.
Dalam dunia AI, perubahan selalu datang secara tidak terduga. Baru-baru ini, sebuah arsitektur baru yang disebut TTT muncul. Arsitektur ini diusulkan bersama oleh para peneliti dari Stanford, UCSD, UC Berkeley dan Meta. Arsitektur ini menumbangkan Transformer dan Mamba dalam semalam dan membawa perubahan revolusioner pada model bahasa.
TTT, nama lengkap lapisan Test-Time-Training, adalah arsitektur baru yang mengompresi konteks melalui penurunan gradien dan secara langsung menggantikan mekanisme perhatian tradisional. Pendekatan ini tidak hanya meningkatkan efisiensi, namun juga membuka arsitektur kompleksitas linier dengan memori ekspresif, memungkinkan kami melatih LLM yang berisi jutaan atau bahkan miliaran token dalam konteksnya.

Usulan lapisan TTT didasarkan pada wawasan mendalam tentang arsitektur RNN dan Transformer yang ada. Meskipun RNN sangat efisien, namun dibatasi oleh kemampuan ekspresifnya; sedangkan Transformer memiliki kemampuan ekspresif yang kuat, namun biaya komputasinya meningkat secara linier seiring dengan panjangnya konteks. Lapisan TTT secara cerdik menggabungkan keunggulan keduanya, mempertahankan kompleksitas linier dan meningkatkan kemampuan ekspresif.
Dalam eksperimen, kedua varian, TTT-Linear dan TTT-MLP, menunjukkan performa luar biasa, mengungguli Transformer dan Mamba baik dalam konteks pendek maupun panjang. Terutama dalam skenario konteks panjang, keunggulan lapisan TTT lebih jelas, yang memberikan potensi besar untuk skenario aplikasi seperti pemodelan video panjang.
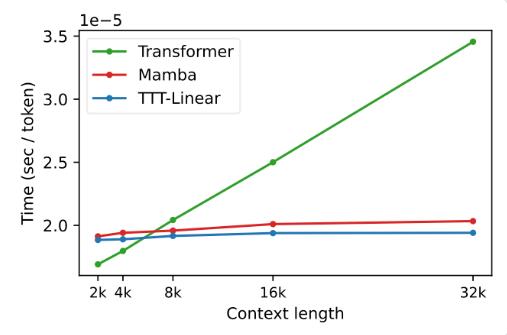
Usulan lapisan TTT tidak hanya inovatif secara teori, namun juga menunjukkan potensi besar dalam penerapan praktis. Di masa depan, lapisan TTT diharapkan dapat diterapkan pada pemodelan video panjang untuk memberikan informasi yang lebih kaya dengan pengambilan sampel yang padat. Hal ini merupakan beban bagi Transformer, namun merupakan berkah bagi lapisan TTT.
Penelitian ini merupakan hasil kerja keras tim selama lima tahun dan telah dikembangkan sejak masa pascadoktoral Dr. Yu Sun. Mereka terus mengeksplorasi dan mencoba, dan akhirnya mencapai hasil terobosan tersebut. Kesuksesan lapisan TTT merupakan hasil kerja keras dan semangat inovatif tim.
Munculnya lapisan TTT telah membawa vitalitas dan kemungkinan baru ke bidang AI. Hal ini tidak hanya mengubah pemahaman kita tentang model bahasa, namun juga membuka jalur baru untuk penerapan AI di masa depan. Mari kita nantikan penerapan dan pengembangan lapisan TTT di masa depan dan saksikan kemajuan dan terobosan teknologi AI.
Alamat makalah: https://arxiv.org/abs/2407.04620
Kemunculan arsitektur TTT tidak diragukan lagi telah memberikan dorongan pada bidang AI. Kemajuan terobosannya dalam pemrosesan teks panjang menunjukkan bahwa aplikasi AI di masa depan akan memiliki kemampuan pemrosesan yang lebih kuat dan prospek aplikasi yang lebih luas. Mari kita tunggu dan lihat bagaimana arsitektur TTT akan mengubah dunia kita lebih jauh.