Editor Downcodes membawa Anda melalui eksperimen AI yang menarik: Pengguna Reddit @zefman membangun platform untuk memungkinkan model bahasa berbeda (LLM) bermain catur secara real time! Eksperimen ini mengevaluasi kemampuan masing-masing LLM bermain catur dengan santai dan menarik. Hasilnya sungguh di luar dugaan, yuk disimak!
Baru-baru ini, pengguna Reddit @zefman melakukan eksperimen menarik, menyiapkan platform untuk mengadu berbagai model bahasa (LLM) dengan catur secara real-time, dengan tujuan memberi pengguna cara yang menyenangkan dan mudah untuk mengevaluasi kinerja model-model ini.
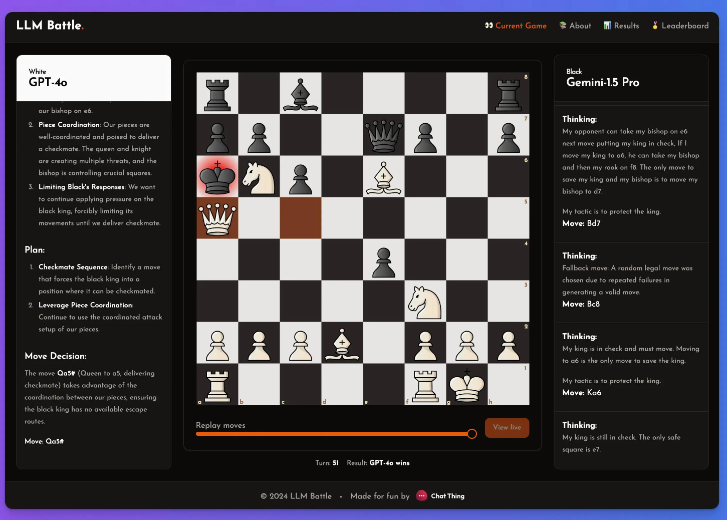
Bukan rahasia lagi kalau model-model ini tidak pandai bermain catur, namun meski begitu, dia merasa ada beberapa hal penting dalam eksperimen ini.
Dalam percobaan kali ini, @zefman memberikan perhatian khusus pada beberapa model terbaru, di antaranya GPT-4o memiliki performa paling luar biasa dan tidak diragukan lagi menjadi pemain terkuat. Pada saat yang sama, @zefman juga membandingkannya dengan model lain seperti Claude dan Gemini untuk mengamati perbedaan kinerja mereka dan menemukan bahwa proses berpikir dan penalaran masing-masing model sangat menarik. Melalui platform ini, setiap orang dapat melihat di balik pengambilan keputusan di setiap langkah dan bagaimana model menganalisis permainan catur.
Metode tampilan permainan catur yang dirancang oleh @zefman cukup sederhana. Ketika setiap model menghadapi keadaan papan catur yang sama, maka akan memberikan petunjuk yang sama, termasuk keadaan permainan catur saat ini, FEN (representasi posisi catur) dan dua gerakan sebelumnya. Pendekatan ini memastikan bahwa setiap keputusan model didasarkan pada informasi yang sama, sehingga memungkinkan perbandingan yang lebih adil.
Setiap model menggunakan perintah yang sama persis, yang diperbarui dengan status papan di ASCI, FEN, dan dua gerakan serta pemikiran sebelumnya. Berikut ini contohnya:
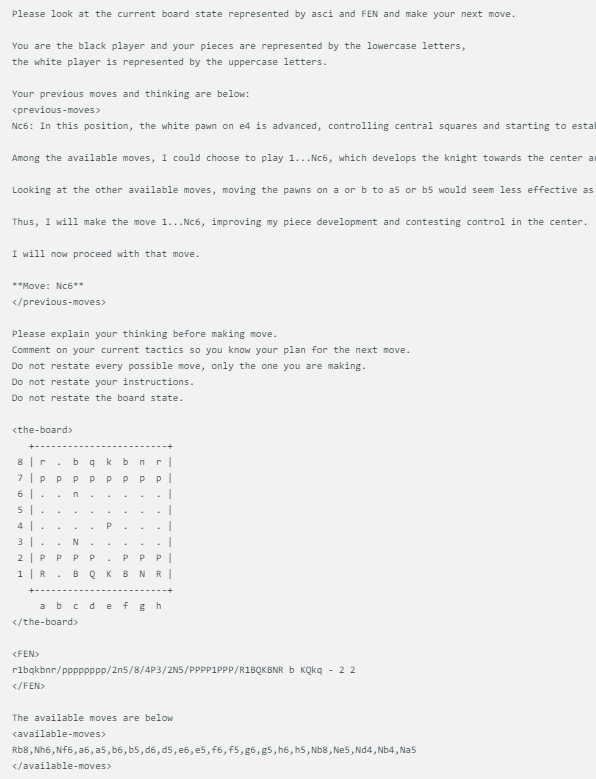
Selain itu, @zefman juga memperhatikan bahwa dalam beberapa kasus, terutama untuk beberapa model yang lebih lemah, mereka mungkin memilih langkah yang salah berkali-kali. Untuk mengatasi masalah ini, dia memberi model ini 5 kesempatan untuk memilih kembali. Jika mereka masih gagal memilih langkah yang valid, mereka akan memilih langkah yang valid secara acak, sehingga permainan tetap berjalan.
Ia menyimpulkan: GTP-4o masih yang terkuat, mengalahkan Gemini1.5pro dalam catur.
Melalui eksperimen ini, kami tidak hanya melihat perbedaan antara berbagai LLM di bidang catur, tetapi juga melihat desain cerdik dan semangat eksperimental @zefman. Menantikan eksperimen serupa lainnya di masa depan, yang akan memberi kita pemahaman lebih dalam tentang potensi dan keterbatasan LLM!