Proyek terbaru Meta AI, Llama3, telah menarik perhatian luas. Editor Downcodes akan memberi Anda pemahaman mendalam tentang teknologi inti dan arah pengembangan di masa depan. Peneliti Meta AI Thomas Scialom baru-baru ini diwawancarai, berbagi rincian pengembangan Llama3 dan memberikan wawasan unik tentang masalah yang ada dalam pelatihan model bahasa skala besar. Dia secara khusus menekankan peran penting data sintetis dalam pelatihan Llama3 dan cara menggunakan umpan balik manusia secara efektif untuk meningkatkan kinerja model. Artikel ini akan menjelaskan secara rinci metode pelatihan, area penerapan, dan rencana pengembangan Llama3 di masa depan, menghadirkan perspektif yang komprehensif dan mendalam kepada pembaca.
Thomas Scialom, peneliti di Meta AI, baru-baru ini berbagi beberapa wawasan tentang proyek terbaru mereka, Llama3, dalam sebuah wawancara. Dia secara blak-blakan menunjukkan bahwa sejumlah besar teks di web memiliki kualitas yang berbeda-beda, dan dia yakin bahwa pelatihan tentang data ini hanya membuang-buang sumber daya. Oleh karena itu, proses pelatihan Llama3 tidak bergantung pada jawaban tertulis manusia, tetapi sepenuhnya didasarkan pada data sintetik yang dihasilkan oleh Llama2.
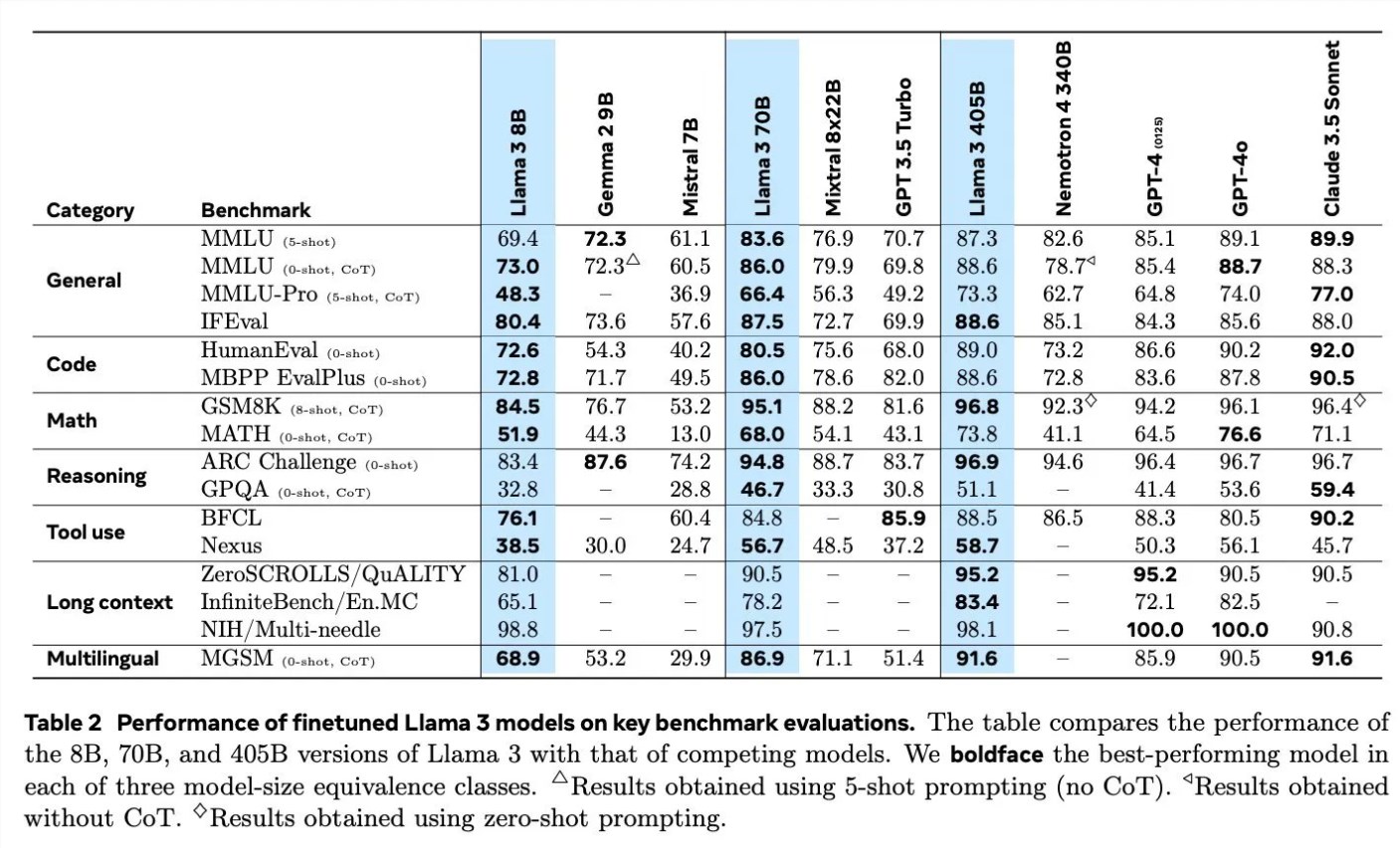
Saat membahas detail pelatihan Llama3, Scialom merinci penerapan data sintetis di berbagai bidang. Misalnya, dalam hal pembuatan kode, mereka menggunakan tiga metode berbeda untuk menghasilkan data sintetis, termasuk umpan balik dari eksekusi kode, terjemahan bahasa pemrograman, dan terjemahan balik dokumentasi. Dalam hal penalaran matematis, mereka menggunakan pendekatan penelitian “mari kita selangkah demi selangkah” dalam menghasilkan data. Selain itu, Llama3 terus dilatih sebelumnya dengan 90% token multibahasa untuk mengumpulkan anotasi manusia berkualitas tinggi, yang sangat penting dalam pemrosesan multibahasa.
Pemrosesan teks panjang juga merupakan fokus Llama3, dan mereka mengandalkan data sintetis untuk menangani jawaban pertanyaan teks panjang, peringkasan dokumen panjang, dan inferensi basis kode. Dalam hal penggunaan alat, Llama3 dilatih tentang penelusuran Brave, Wolfram Alpha, dan interpreter Python untuk mengimplementasikan pemanggilan fungsi tunggal, bersarang, paralel, dan multi-putaran.
Scialom juga menyebutkan pentingnya pembelajaran penguatan dengan umpan balik manusia (RLHF) dalam pelatihan Llama3. Mereka banyak menggunakan data preferensi manusia untuk melatih model tersebut, menekankan kemampuan manusia untuk membuat pilihan (seperti memilih salah satu dari dua puisi yang disukai) daripada memulai dari awal.
Meta telah memulai pelatihan Llama4 pada bulan Juni, dan Scialom mengungkapkan bahwa fokus utama Llama4 adalah seputar agen cerdas. Selain itu, ia juga menyebutkan Llama versi multi-modal yang akan memiliki lebih banyak parameter dan rencananya akan dirilis dalam waktu dekat.
Wawancara Scialom mengungkapkan kemajuan terbaru Meta AI dan arah pengembangan masa depan di bidang kecerdasan buatan, terutama dalam cara menggunakan data sintetis dan umpan balik manusia untuk meningkatkan kinerja model.
Melalui wawancara Scialom, kami mengetahui tentang inovasi Llama3 dalam pemanfaatan data dan pelatihan model, serta eksplorasi lanjutan Meta AI di bidang model bahasa skala besar. Pengalaman sukses Llama3 memberikan referensi berharga bagi pengembangan model kecerdasan buatan di masa depan, dan juga menunjukkan bahwa teknologi kecerdasan buatan akan berkembang ke arah yang lebih akurat dan efisien. Editor Downcodes menantikan rilis Llama4 dan multi-modal Llama, dan terus memperhatikan kemajuan terobosan Meta AI di bidang kecerdasan buatan.