Rilisan besar Meta Company! Open source model bahasa besar terbaru Llama 3.1 405B, dengan volume parameter hingga 128 miliar, dan kinerjanya sebanding dengan GPT-4 dalam banyak tugas. Setelah setahun persiapan yang matang, mulai dari perencanaan proyek hingga tinjauan akhir, model seri Llama 3 akhirnya diperkenalkan ke publik. Sumber terbuka ini tidak hanya mencakup model itu sendiri, tetapi juga pemrosesan data pra-pelatihan yang dioptimalkan, jaminan kualitas data pasca-pelatihan, dan teknologi kuantifikasi yang efisien untuk mengurangi kebutuhan komputasi dan memudahkan pengembang dalam menggunakannya. Editor Downcodes akan menjelaskan secara rinci peningkatan dan sorotan Llama 3.1 405B.
Tadi malam, Meta mengumumkan open source model bahasa besar terbarunya Llama3.1 405B. Berita besar ini menandai bahwa setelah satu tahun persiapan yang matang, mulai dari perencanaan proyek hingga tinjauan akhir, model seri Llama3 akhirnya diperkenalkan ke publik.
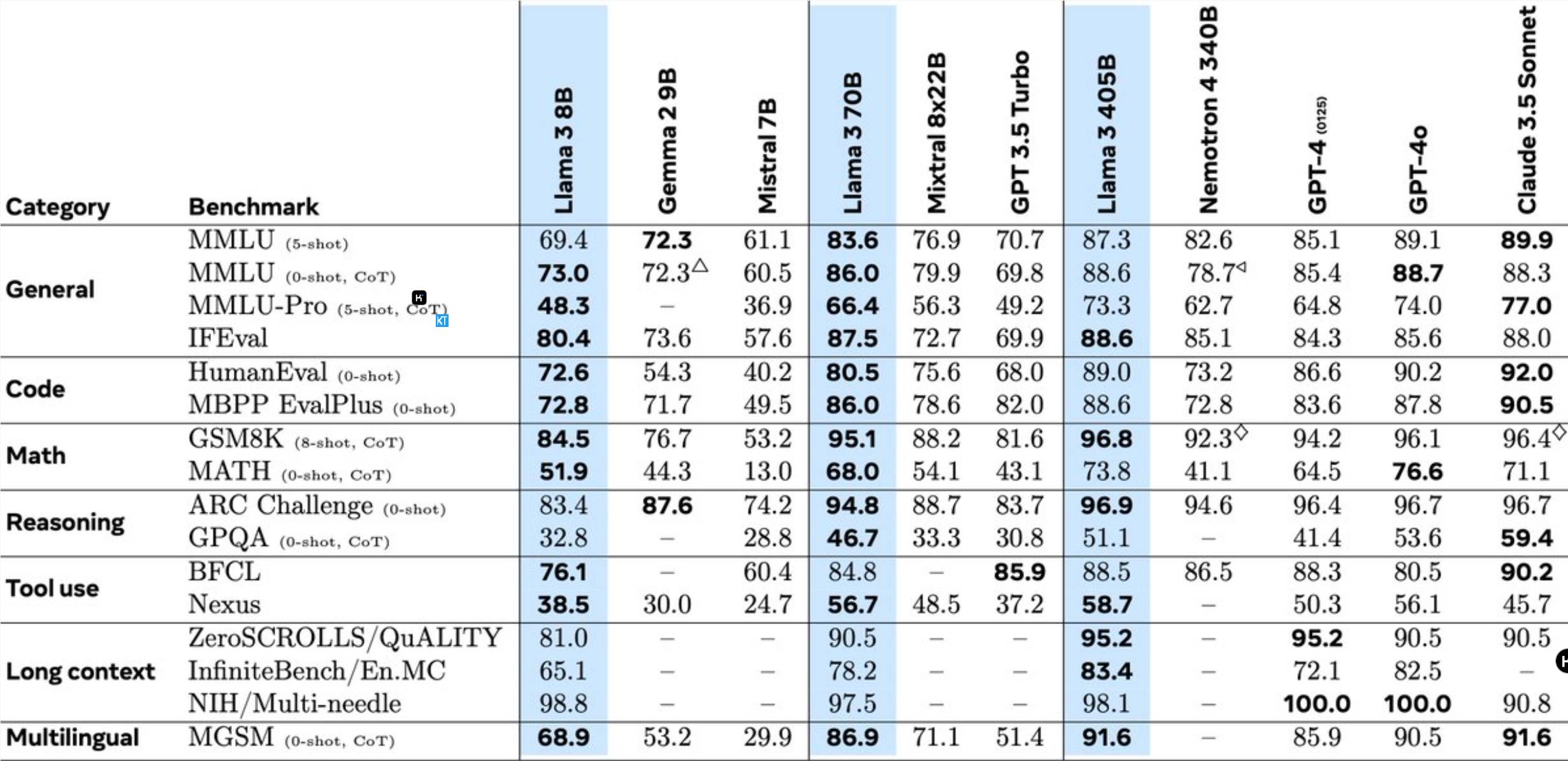
Llama3.1405B adalah model penggunaan alat multibahasa dengan 128 miliar parameter. Setelah pra-pelatihan dengan panjang konteks 8K, model dilatih lebih lanjut dengan panjang konteks 128K. Menurut Meta, performa model ini dalam berbagai tugas sebanding dengan GPT-4 yang terdepan di industri.
Dibandingkan dengan model Llama sebelumnya, Meta telah dioptimalkan dalam banyak aspek:
Pra-pelatihan model 405B merupakan tantangan besar, yang melibatkan 15,6 triliun token dan 3,8x10^25 operasi floating point. Untuk tujuan ini, Meta mengoptimalkan seluruh arsitektur pelatihan dan menggunakan lebih dari 16.000 GPU H100.
Untuk mendukung inferensi produksi massal model 405B, Meta mengkuantisasinya dari 16-bit (BF16) menjadi 8-bit (FP8), sehingga secara signifikan mengurangi kebutuhan komputasi dan memungkinkan satu node server untuk menjalankan model.
Selain itu, Meta menggunakan model 405B untuk meningkatkan kualitas pasca pelatihan model 70B dan 8B. Pada fase pasca-pelatihan, tim menyempurnakan model obrolan melalui beberapa putaran proses penyelarasan, termasuk penyempurnaan yang diawasi (SFT), pengambilan sampel penolakan, dan pengoptimalan preferensi langsung. Perlu dicatat bahwa sebagian besar sampel SFT dihasilkan menggunakan data sintetis.
Llama3 juga mengintegrasikan fungsi gambar, video, dan suara, menggunakan pendekatan gabungan untuk memungkinkan model mengenali gambar dan video, serta mendukung interaksi suara. Namun fitur-fitur tersebut masih dalam pengembangan dan belum dirilis secara resmi.
Meta juga telah memperbarui perjanjian lisensinya untuk memungkinkan pengembang menggunakan keluaran model Llama untuk menyempurnakan model lainnya.
Para peneliti di Meta mengatakan: Sangat menyenangkan untuk bekerja di garis depan AI dengan talenta terbaik di industri dan mempublikasikan hasil penelitian secara terbuka dan transparan. Kami menantikan inovasi yang dibawa oleh model sumber terbuka, dan potensi model seri Llama di masa depan!
Inisiatif sumber terbuka ini tidak diragukan lagi akan membawa peluang dan tantangan baru di bidang AI dan mendorong pengembangan lebih lanjut teknologi model bahasa besar.
Sumber terbuka Llama 3.1 405B akan sangat mendorong kemajuan teknologi model bahasa besar dan membawa lebih banyak kemungkinan ke bidang AI. Kami menantikan pengembang menciptakan aplikasi yang lebih menakjubkan berdasarkan model ini!