Meningkatkan efisiensi model bahasa besar selalu menjadi fokus penelitian di bidang kecerdasan buatan. Baru-baru ini, tim peneliti dari Aleph Alpha, Universitas Teknik Darmstadt, dan institusi lain telah mengembangkan metode baru yang disebut T-FREE, yang secara signifikan meningkatkan efisiensi pengoperasian model bahasa besar. Metode ini mengurangi jumlah parameter lapisan yang disematkan dengan menggunakan karakter tiga kali lipat untuk aktivasi yang jarang, dan secara efektif memodelkan kesamaan morfologi antar kata. Metode ini sangat mengurangi konsumsi sumber daya komputasi sekaligus memastikan kinerja model. Terobosan teknologi ini membawa kemungkinan baru untuk penerapan model bahasa besar.
Tim peneliti baru-baru ini memperkenalkan metode baru yang menarik yang disebut T-FREE, yang memungkinkan efisiensi pengoperasian model bahasa besar meroket. Para ilmuwan dari Aleph Alpha, TU Darmstadt, hessian.AI dan Pusat Penelitian Kecerdasan Buatan Jerman (DFKI) telah bersama-sama meluncurkan teknologi luar biasa ini, yang nama lengkapnya adalah "Representasi Jarang Bebas Tagger, Penyematan yang Hemat Memori adalah Mungkin".
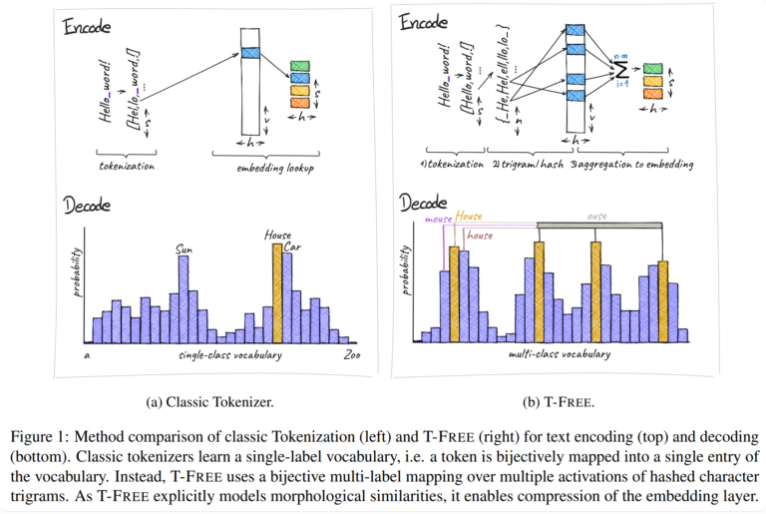
Secara tradisional, kami menggunakan tokenizer untuk mengubah teks menjadi bentuk numerik yang dapat dipahami komputer, namun T-FREE telah memilih jalur yang berbeda. Ia menggunakan karakter rangkap tiga, yang kami sebut "tiga kali lipat", untuk menyematkan kata secara langsung ke dalam model melalui aktivasi renggang. Sebagai hasil dari langkah inovatif ini, jumlah parameter di lapisan penyematan berkurang sebanyak 85% atau lebih, sementara performa model tidak terpengaruh sama sekali saat menangani tugas seperti klasifikasi teks dan menjawab pertanyaan.
Sorotan lain dari T-FREE adalah ia dengan cerdik memodelkan kesamaan morfologi antar kata. Sama seperti kata "rumah", "rumah", dan "domestik" yang sering kita jumpai dalam kehidupan sehari-hari, T-FREE dapat lebih efektif merepresentasikan kata-kata serupa tersebut dalam model. Para peneliti percaya bahwa kata-kata serupa harus disisipkan lebih dekat satu sama lain untuk mencapai tingkat kompresi yang lebih tinggi. Oleh karena itu, T-FREE tidak hanya mengurangi ukuran lapisan penyematan, tetapi juga mengurangi rata-rata panjang pengkodean teks sebesar 56%.
Yang lebih penting lagi adalah T-FREE berkinerja sangat baik dalam pembelajaran transfer antar bahasa yang berbeda. Dalam satu percobaan, para peneliti menggunakan model dengan 3 miliar parameter, dilatih terlebih dahulu dalam bahasa Inggris dan kemudian dalam bahasa Jerman, dan menemukan bahwa T-FREE jauh lebih mudah beradaptasi dibandingkan metode tradisional berbasis tagger.
Namun, para peneliti tetap merendah mengenai hasil mereka saat ini. Mereka mengakui bahwa eksperimen sejauh ini terbatas pada model dengan hingga 3 miliar parameter, dan evaluasi lebih lanjut terhadap model yang lebih besar dan kumpulan data yang lebih besar direncanakan di masa depan.
Kemunculan metode T-FREE memberikan ide-ide baru untuk meningkatkan efisiensi model bahasa besar. Keunggulannya dalam mengurangi biaya komputasi dan meningkatkan kinerja model patut mendapat perhatian. Arah penelitian di masa depan akan fokus pada verifikasi model dan kumpulan data berskala lebih besar untuk lebih memperluas cakupan penerapan T-FREE dan mendorong pengembangan berkelanjutan teknologi model bahasa berskala besar. T-FREE diyakini akan memainkan peran penting di lebih banyak bidang dalam waktu dekat.