Jina AI telah merilis Reader-LM, model bahasa ringan yang dirancang khusus untuk mengubah HTML menjadi Markdown yang bersih. Ini dapat secara efisien menghapus konten yang berantakan dari halaman web, seperti iklan dan skrip, untuk menghasilkan file Markdown yang terstruktur dengan jelas tanpa ekspresi reguler yang rumit atau operasi manual. Reader-LM tersedia dalam dua versi: Reader-LM-0.5B dan Reader-LM-1.5B, keduanya dioptimalkan untuk berjalan secara efisien bahkan di lingkungan dengan sumber daya terbatas dan mendukung konteks hingga 256 ribu token.
Jina AI telah meluncurkan dua model bahasa kecil yang dirancang khusus untuk mengubah konten HTML asli menjadi format Markdown yang bersih dan rapi, memungkinkan kita menghilangkan pemrosesan data halaman web yang membosankan.
Keunggulan terbesar dari model yang disebut Reader-LM ini adalah model ini dapat dengan cepat dan efisien mengonversi konten web menjadi file Markdown.
Keuntungan menggunakannya adalah Anda tidak perlu lagi bergantung pada aturan yang rumit atau ekspresi reguler yang melelahkan. Model ini secara cerdas dan otomatis menghapus konten yang berantakan dari halaman web, seperti iklan, skrip, dan bilah navigasi, dan pada akhirnya menyajikan format penurunan harga yang jelas dan terorganisir.
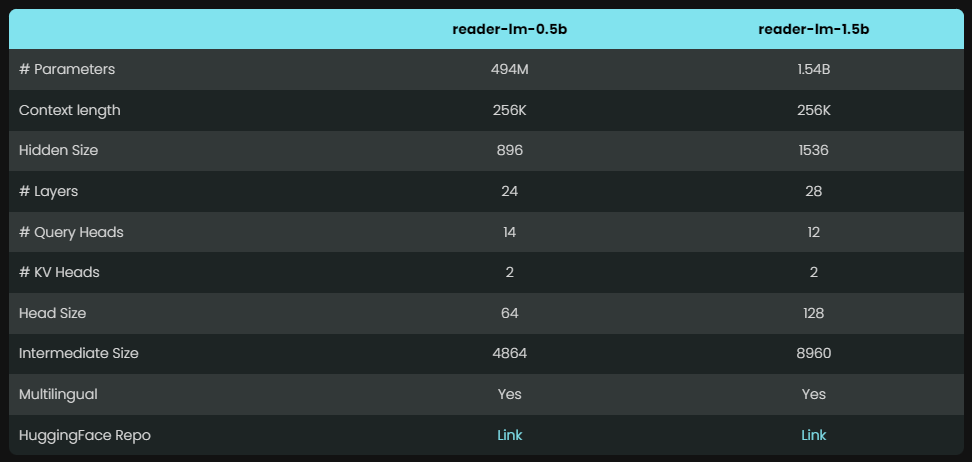
Reader-LM menyediakan dua model dengan parameter berbeda yaitu Reader-LM-0.5B dan Reader-LM-1.5B. Meskipun jumlah parameter kedua model ini tidak banyak, keduanya dioptimalkan untuk tugas mengonversi HTML ke Markdown. Hasilnya mengejutkan, dan kinerjanya melampaui banyak model bahasa besar.
Berkat desainnya yang ringkas, model ini dapat beroperasi secara efisien di lingkungan dengan sumber daya terbatas. Yang lebih terpuji lagi adalah Reader-LM tidak hanya mendukung banyak bahasa, namun juga dapat menangani data konteks hingga 256 ribu token, sehingga memungkinkan untuk menangani file HTML yang rumit sekalipun dengan mudah.
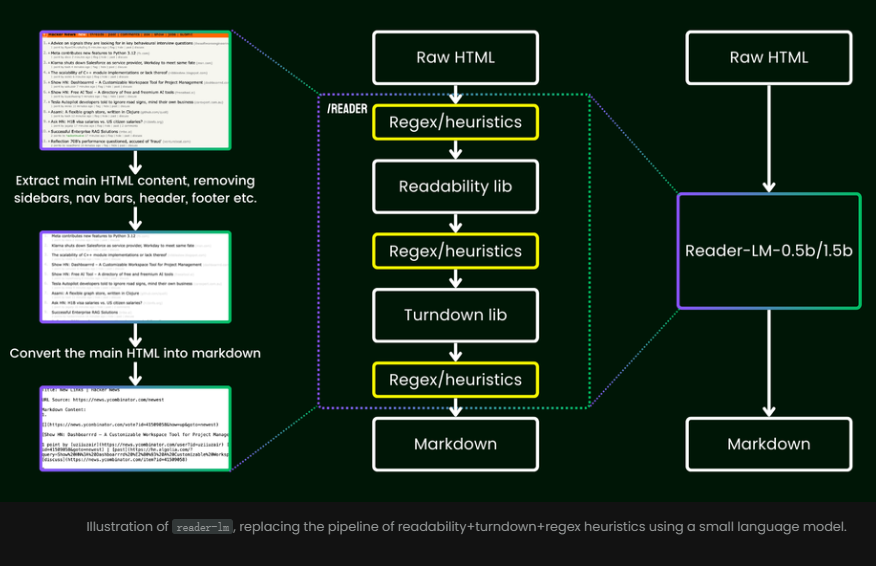
Tidak seperti metode tradisional yang mengandalkan ekspresi reguler atau pengaturan manual, Reader-LM menyediakan solusi end-to-end yang secara otomatis membersihkan data HTML dan mengekstrak informasi penting.
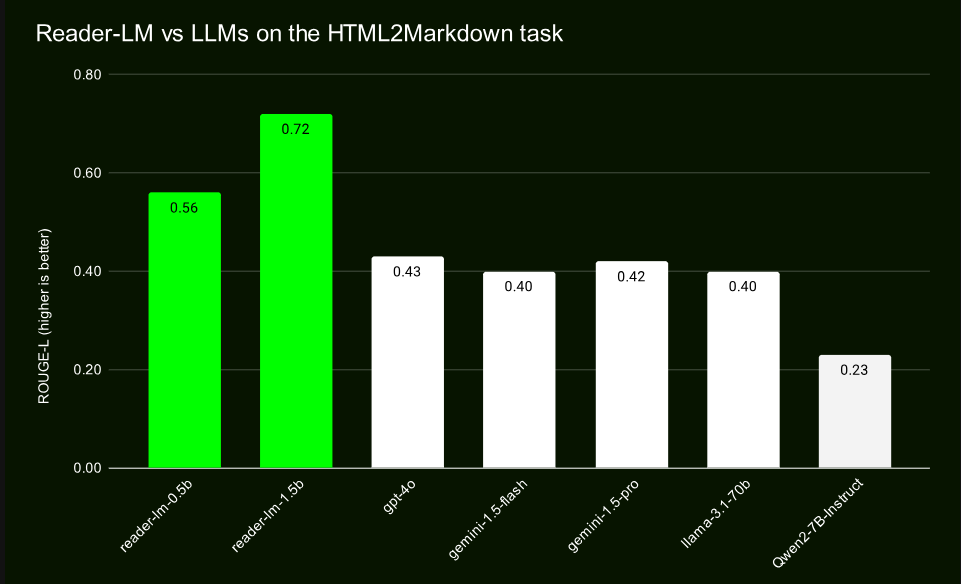
Melalui pengujian komparatif dengan model skala besar seperti GPT-4 dan Gemini, Reader-LM telah menunjukkan kinerja yang sangat baik, terutama dalam hal pelestarian struktur dan penggunaan sintaksis Markdown. Reader-LM-1.5B berkinerja sangat baik dalam berbagai indikator, dengan skor ROUGE-L sebesar 0,72, menunjukkan akurasi yang tinggi dalam menghasilkan konten, dan tingkat kesalahannya juga jauh lebih rendah dibandingkan produk serupa.
Karena desain Reader-LM yang ringkas, penggunaan sumber daya perangkat kerasnya lebih ringan, terutama model 0,5B, yang dapat berjalan dengan lancar di lingkungan konfigurasi rendah seperti Google Colab. Meskipun ukurannya kecil, Reader-LM masih memiliki kemampuan pemrosesan konteks panjang yang kuat dan dapat memproses konten web yang besar dan kompleks secara efisien tanpa memengaruhi kinerja.
Dalam hal pelatihan, Reader-LM mengadopsi proses multi-tahap dan berfokus pada ekstraksi konten Markdown dari HTML asli dan berisik.
Proses pelatihan mencakup pemasangan sejumlah besar halaman web asli dan data sintetis, untuk memastikan efisiensi dan keakuratan model. Setelah pelatihan dua tahap yang dirancang dengan cermat, Reader-LM secara bertahap meningkatkan kemampuannya untuk memproses file HTML yang kompleks dan secara efektif menghindari masalah pembuatan berulang.
Pengenalan resmi: https://jina.ai/news/reader-lm-small-bahasa-models-for-cleaning-and-converting-html-to-markdown/
Secara keseluruhan, Reader-LM memberikan solusi yang efisien, nyaman dan akurat untuk konversi HTML ke Markdown. Desainnya yang ringan membuatnya mudah dijalankan di berbagai lingkungan, menjadikannya pilihan ideal untuk memproses data halaman web. Untuk informasi lebih lanjut, silakan kunjungi tautan pengenalan resmi.