Teknologi Kunlun baru-baru ini mengumumkan bahwa dua model penghargaan yang dikembangkannya, Skywork-Reward-Gemma-2-27B dan Skywork-Reward-Llama-3.1-8B, meraih hasil luar biasa di RewardBench, dengan model 27B berada di puncak daftar. Hal ini menandai bahwa Kunlun Wanwei telah membuat terobosan besar di bidang kecerdasan buatan, khususnya dalam penelitian dan pengembangan model penghargaan, serta memberikan dukungan teknis baru untuk pelatihan model bahasa skala besar. Model penghargaan sangat penting dalam pembelajaran penguatan, karena model tersebut dapat memandu pembelajaran model dan menghasilkan konten yang lebih sesuai dengan preferensi manusia. Model Kunlun Wanwei memiliki keunggulan unik dalam pemilihan data dan pelatihan model, yang membuatnya bekerja dengan baik dalam berbagai aspek seperti dialog dan keamanan, dan terutama menunjukkan kemampuan yang kuat saat memproses sampel yang sulit.
baru-baru ini mengumumkan bahwa dua model penghargaan baru yang dikembangkan oleh perusahaan, Skywork-Reward-Gemma-2-27B dan Skywork-Reward-Llama-3.1-8B, berkinerja baik di RewardBench, model penghargaan resmi internasional tolok ukur evaluasi. Diantaranya, model Skywork-Reward-Gemma-2-27B memenangkan posisi teratas dan sangat diakui oleh pejabat RewardBench.
Model penghargaan menempati posisi inti dalam pembelajaran penguatan, mengevaluasi kinerja agen di berbagai negara bagian, dan memberikan sinyal penghargaan untuk memandu proses pembelajaran agen, sehingga dapat membuat pilihan optimal dalam lingkungan tertentu. Dalam pelatihan model bahasa besar, model penghargaan memainkan peran yang sangat penting, membantu model untuk memahami dan menghasilkan konten yang sesuai dengan preferensi manusia dengan lebih akurat.
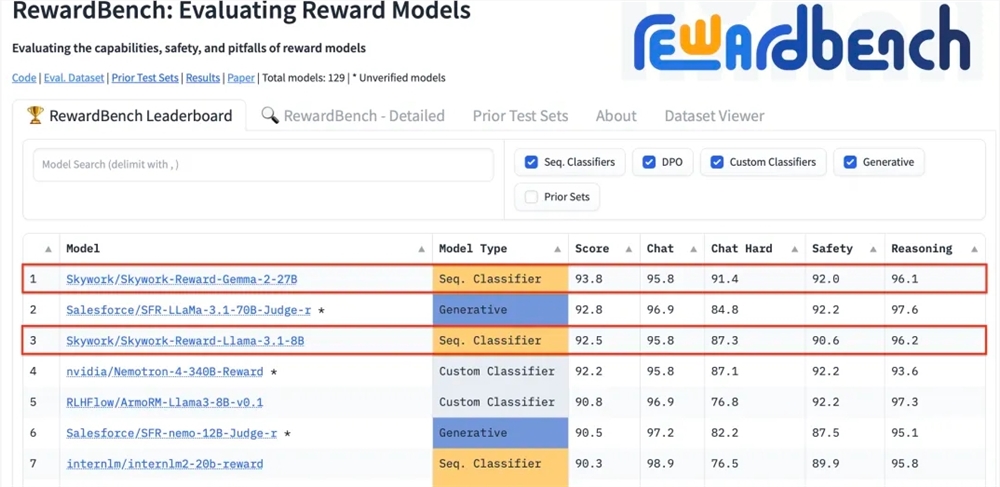
RewardBench adalah daftar tolok ukur yang secara khusus mengevaluasi efektivitas model penghargaan dalam model bahasa besar. Daftar ini mengevaluasi model secara komprehensif melalui berbagai tugas, termasuk dialog, penalaran, dan keamanan. Kumpulan data pengujian dari daftar ini terdiri dari tiga kali lipat yang terdiri dari kata-kata cepat, tanggapan yang dipilih, dan tanggapan yang ditolak. Hal ini digunakan untuk menguji apakah model penghargaan dapat memberi peringkat dengan benar pada tanggapan yang dipilih di antara tanggapan yang ditolak yang diberi kata-kata cepat sebelum menolak tanggapan tersebut .
Model Skywork-Reward Kunlun Wanwei dikembangkan melalui kumpulan data yang diurutkan sebagian dan model dasar yang relatif kecil yang dipilih dengan cermat. Dibandingkan dengan model penghargaan yang ada, data yang diurutkan sebagian hanya berasal dari data publik di Internet dan disaring melalui filter tertentu untuk mendapatkan yang tinggi -kumpulan data preferensi kualitas. Data tersebut mencakup berbagai topik, termasuk keamanan, matematika, dan kode, dan diverifikasi secara manual untuk memastikan objektivitas data dan pentingnya kesenjangan penghargaan.
Setelah pengujian, model reward Kunlun Wanwei menunjukkan kinerja luar biasa di berbagai bidang seperti dialog dan keamanan. Terutama saat menghadapi sampel yang sulit, hanya model Skywork-Reward-Gemma-2-27B yang memberikan prediksi yang benar. Pencapaian ini menandai kekuatan teknis dan kemampuan inovasi Kunlun Wanwei di bidang AI global, dan juga memberikan kemungkinan baru dalam pengembangan dan penerapan teknologi AI.
Alamat model 27B:
https://huggingface.co/Skywork/Skywork-Reward-Gemma-2-27B
Alamat model 8B:
https://huggingface.co/Skywork/Skywork-Reward-Llama-3.1-8B
Kinerja luar biasa yang ditunjukkan oleh Kunlun Wanwei di RewardBench menunjukkan kemampuan teknologi dan inovasi terdepannya di bidang kecerdasan buatan. Hal ini juga memberikan arahan dan kemungkinan baru untuk pengembangan model bahasa besar di masa depan. Kami berharap dapat membawa lebih banyak terobosan di masa depan.