Nous Research meluncurkan pengoptimal pelatihan AI yang revolusioner, DisTrO, yang memecahkan situasi di mana pelatihan model AI skala besar terbatas pada perusahaan raksasa besar. DisTrO dapat secara signifikan mengurangi jumlah transmisi data antara beberapa GPU dan secara efisien dapat melatih model AI bahkan dalam lingkungan jaringan biasa. Hal ini akan sangat menurunkan ambang batas untuk pelatihan model AI dan memungkinkan lebih banyak individu dan institusi untuk berpartisipasi dalam pengembangan teknologi AI dan pembangunan yang sedang berlangsung. Teknologi inovatif ini diharapkan dapat sepenuhnya mengubah model penelitian dan pengembangan di bidang AI serta mendorong pemasyarakatan dan pengembangan teknologi AI.
Baru-baru ini, tim peneliti di Nous Research membawa berita menarik ke dunia teknologi. Mereka meluncurkan pengoptimal baru yang disebut DisTrO (Distributed Internet Training). Lahirnya teknologi ini berarti bahwa model AI yang kuat tidak hanya menjadi hak paten perusahaan besar, tetapi masyarakat awam juga memiliki kesempatan untuk menggunakan komputer mereka sendiri untuk pelatihan yang efisien di rumah.
Keajaiban DisTrO adalah ia dapat secara signifikan mengurangi jumlah informasi yang perlu ditransfer antara beberapa unit pemrosesan grafis (GPU) saat melatih model AI. Melalui inovasi ini, model AI yang kuat dapat dilatih dalam kondisi jaringan biasa, dan bahkan memungkinkan individu atau institusi di seluruh dunia bergabung untuk bersama-sama mengembangkan teknologi AI.
Menurut makalah teknis oleh Nous Research, peningkatan efisiensi DisTrO sangat mencengangkan. Efisiensi pelatihan yang menggunakannya adalah 857 kali lebih tinggi dibandingkan dengan algoritma umum-All-Reduce langkahnya juga dikurangi dari 74,4GB menjadi 74,4GB. Peningkatan tersebut tidak hanya menjadikan pelatihan lebih cepat dan lebih murah, namun juga berarti lebih banyak orang mempunyai kesempatan untuk berpartisipasi dalam bidang ini.
Nous Research menyatakan di platform sosialnya bahwa melalui DisTrO, para peneliti dan institusi tidak perlu lagi bergantung pada perusahaan tertentu untuk mengelola dan mengendalikan proses pelatihan, sehingga memberi mereka lebih banyak kebebasan untuk berinovasi dan bereksperimen. Lingkungan kompetitif terbuka ini membantu mendorong kemajuan teknologi dan pada akhirnya memberi manfaat bagi seluruh masyarakat.
Dalam pelatihan AI, persyaratan perangkat keras seringkali menjadi penghalang. Khususnya, GPU Nvidia berperforma tinggi menjadi semakin langka dan mahal di era ini, dan hanya beberapa perusahaan yang mempunyai dana besar yang mampu menanggung beban pelatihan tersebut. Namun, filosofi Nous Research justru sebaliknya. Mereka berkomitmen untuk membuka pelatihan model AI kepada publik dengan biaya lebih rendah dan berupaya untuk memungkinkan lebih banyak orang untuk berpartisipasi.
DisTrO bekerja dengan mengurangi overhead komunikasi sebanyak empat hingga lima kali lipat dengan mengurangi kebutuhan sinkronisasi gradien penuh antar GPU. Inovasi ini memungkinkan model AI untuk dilatih pada koneksi internet yang lebih lambat, dengan kecepatan unduh 100Mbps dan kecepatan unggah 10Mbps yang mudah diakses oleh banyak rumah tangga saat ini sudah mencukupi.
Dalam pengujian pendahuluan pada model bahasa besar Llama2 Meta, DisTrO menunjukkan hasil pelatihan yang sebanding dengan metode tradisional sekaligus mengurangi jumlah komunikasi yang diperlukan secara signifikan. Para peneliti juga mengatakan bahwa meskipun sejauh ini mereka baru diuji pada model yang lebih kecil, mereka secara tentatif berspekulasi bahwa seiring bertambahnya ukuran model, pengurangan kebutuhan komunikasi mungkin akan lebih signifikan, bahkan mencapai 1.000 hingga 3.000 kali lipat.
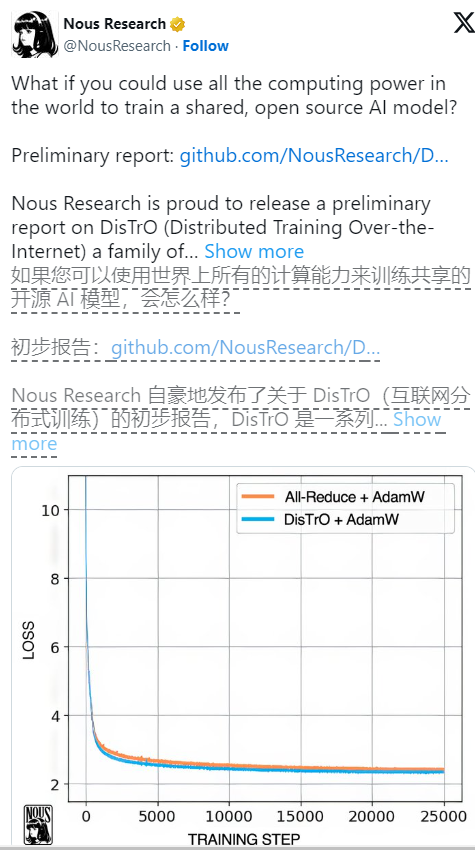
Perlu dicatat bahwa meskipun DisTrO membuat pelatihan lebih fleksibel dan tetap mengandalkan dukungan GPU, namun kini GPU tersebut tidak perlu dikumpulkan di satu tempat, tetapi dapat tersebar di seluruh dunia dan berkolaborasi melalui Internet biasa. Kami melihat bahwa DisTrO mampu menandingi metode tradisional AdamW+All-Reduce dalam hal kecepatan konvergensi ketika diuji secara ketat menggunakan 32 GPU H100, namun hal ini secara signifikan mengurangi kebutuhan komunikasi.
DisTrO tidak hanya cocok untuk model bahasa besar, tetapi juga dapat digunakan untuk melatih jenis AI lain seperti model pembuatan gambar. Prospek penerapannya di masa depan sangat menarik. Selain itu, dengan meningkatkan efisiensi pelatihan, DisTrO juga dapat mengurangi dampak pelatihan AI terhadap lingkungan karena mengoptimalkan penggunaan infrastruktur yang ada dan mengurangi kebutuhan akan pusat data yang besar.
Melalui DisTrO, Nous Research tidak hanya mempromosikan kemajuan teknologi dalam pelatihan AI, namun juga mempromosikan ekosistem penelitian yang lebih terbuka dan fleksibel, yang membuka kemungkinan tak terbatas untuk pengembangan AI di masa depan.
Referensi: https://venturebeat.com/ai/this-could-change-everything-nous-research-unveils-new-tool-to-train-powerful-ai-models-with-10000x-efficiency/
Munculnya DisTrO menandai proses demokratisasi pelatihan AI, menurunkan ambang partisipasi, mendorong perkembangan pesat dan penerapan teknologi AI secara luas, serta membawa vitalitas baru dan kemungkinan tak terbatas ke bidang AI. Di masa depan, kami berharap DisTrO dapat menghadirkan lebih banyak kejutan dalam pengembangan AI.