Penelitian tim Mamba telah membuat terobosan, mereka berhasil "menyalingkan" model Transformer besar Llama menjadi model Mamba yang lebih efisien. Penelitian ini secara cerdik menggabungkan teknologi seperti distilasi progresif, penyesuaian yang diawasi, dan optimalisasi preferensi arah, serta merancang algoritme decoding inferensi baru berdasarkan struktur unik model Mamba, yang secara signifikan meningkatkan kecepatan inferensi model tanpa memastikan peningkatan yang substansial efisiensi telah dicapai tanpa kerugian. Penelitian ini tidak hanya mengurangi biaya pelatihan model skala besar, tetapi juga memberikan ide-ide baru untuk optimasi model masa depan, yang memiliki signifikansi akademis dan nilai penerapan yang penting.
Baru-baru ini, penelitian tim Mamba sangat menarik: peneliti dari universitas seperti Cornell dan Princeton telah berhasil "menyaring" Llama, model Transformer besar, menjadi Mamba, dan merancang algoritma decoding inferensi baru yang secara signifikan meningkatkan kecepatan inferensi model.
Tujuan para peneliti adalah mengubah Llama menjadi Mamba. Mengapa melakukan hal ini? Karena melatih model besar dari awal itu mahal, dan Mamba telah mendapat perhatian luas sejak awal, namun hanya sedikit tim yang benar-benar melatih sendiri model Mamba skala besar. Meskipun ada beberapa varian terkemuka di pasaran, seperti Jamba AI21 dan Hybrid Mamba2 NVIDIA, ada banyak pengetahuan yang tertanam dalam banyak model Transformer yang sukses. Jika kita dapat mengunci pengetahuan ini dan menyempurnakan Transformer ke Mamba, maka masalahnya akan terpecahkan.
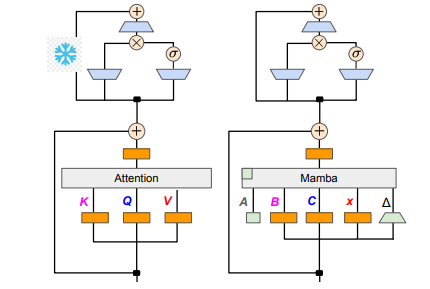
Tim peneliti berhasil mencapai tujuan ini dengan menggabungkan berbagai metode seperti distilasi progresif, penyesuaian yang diawasi, dan optimalisasi preferensi terarah. Perlu dicatat bahwa kecepatan juga penting tanpa mengurangi kinerja. Mamba memiliki keunggulan yang jelas dalam penalaran urutan panjang, dan Transformer juga memiliki solusi percepatan penalaran, seperti decoding spekulatif. Karena struktur unik Mamba tidak dapat menerapkan solusi ini secara langsung, para peneliti secara khusus merancang algoritma baru dan menggabungkannya dengan fitur perangkat keras untuk mengimplementasikan decoding spekulatif berbasis Mamba.
Terakhir, para peneliti berhasil mengubah Zephyr-7B dan Llama-38B menjadi model RNN linier, dan kinerjanya sebanding dengan model standar sebelum distilasi. Seluruh proses pelatihan hanya menggunakan 20 miliar token, dan hasilnya sebanding dengan model Mamba7B yang dilatih dari awal menggunakan 1,2T token dan model NVIDIA Hybrid Mamba2 yang dilatih dengan 3,5T token.
Dari segi detail teknis, RNN linier dan perhatian linier saling terhubung, sehingga peneliti dapat langsung menggunakan kembali matriks proyeksi dalam mekanisme perhatian dan menyelesaikan konstruksi model melalui inisialisasi parameter. Selain itu, tim peneliti membekukan parameter lapisan MLP di Transformer, secara bertahap mengganti kepala perhatian dengan lapisan RNN linier (yaitu Mamba), dan memproses perhatian kueri grup untuk kunci dan nilai bersama di seluruh kepala.
Selama proses penyulingan, strategi penggantian lapisan perhatian diterapkan secara bertahap. Penyempurnaan yang diawasi mencakup dua metode utama: satu didasarkan pada divergensi KL tingkat kata, dan yang lainnya adalah penyulingan pengetahuan tingkat urutan. Dalam fase penyesuaian preferensi pengguna, tim menggunakan metode Direct Preference Optimization (DPO) untuk memastikan bahwa model tersebut dapat lebih memenuhi harapan pengguna saat membuat konten dengan membandingkannya dengan keluaran model guru.
Selanjutnya, para peneliti mulai menerapkan decoding spekulatif Transformer pada model Mamba. Penguraian kode spekulatif secara sederhana dapat dipahami sebagai menggunakan model kecil untuk menghasilkan banyak keluaran, dan kemudian menggunakan model besar untuk memverifikasi keluaran tersebut. Model kecil berjalan dengan cepat dan dapat dengan cepat menghasilkan beberapa vektor keluaran, sedangkan model besar bertanggung jawab untuk mengevaluasi keakuratan keluaran ini, sehingga meningkatkan kecepatan inferensi secara keseluruhan.
Untuk mengimplementasikan proses ini, para peneliti merancang serangkaian algoritme yang menggunakan model kecil untuk menghasilkan keluaran K draft setiap kali, dan kemudian model besar mengembalikan keluaran akhir dan cache status perantara melalui verifikasi. Metode ini telah mencapai hasil yang baik pada GPU. Mamba2.8B mencapai akselerasi inferensi 1,5 kali lipat, dan tingkat penerimaan mencapai 60%. Meskipun efeknya bervariasi pada GPU dengan arsitektur berbeda, tim peneliti melakukan optimasi lebih lanjut dengan mengintegrasikan kernel dan menyesuaikan metode implementasi, dan akhirnya mencapai efek akselerasi yang ideal.
Pada tahap percobaan, para peneliti menggunakan Zephyr-7B dan Llama-3Instruct8B untuk melakukan pelatihan distilasi tiga tahap. Pada akhirnya, hanya membutuhkan waktu 3 hingga 4 hari untuk menjalankan 8 kartu 80G A100 agar berhasil mereproduksi hasil penelitian. Penelitian ini tidak hanya menunjukkan transformasi antara Mamba dan Llama, tetapi juga memberikan ide-ide baru untuk meningkatkan kecepatan inferensi dan kinerja model masa depan.
Alamat makalah: https://arxiv.org/pdf/2408.15237
Penelitian ini memberikan pengalaman berharga dan solusi teknis untuk meningkatkan efisiensi model bahasa skala besar. Hasilnya diharapkan dapat diterapkan di lebih banyak bidang dan mendorong pengembangan lebih lanjut teknologi kecerdasan buatan. Pemberian alamat makalah memudahkan pembaca untuk memahami lebih dalam mengenai detail penelitian.