Google DeepMind bekerja sama dengan sejumlah universitas untuk mengembangkan metode baru yang disebut Generative Reward Model (GenRM), yang bertujuan untuk memecahkan masalah kurangnya akurasi dan keandalan AI generatif dalam tugas-tugas penalaran. Meskipun model AI generatif yang ada saat ini banyak digunakan dalam bidang-bidang seperti pemrosesan bahasa alami, model-model tersebut sering kali secara meyakinkan menghasilkan informasi yang salah, terutama dalam bidang-bidang yang memerlukan akurasi sangat tinggi, sehingga membatasi cakupan penerapannya. Inovasi GenRM adalah mendefinisikan ulang proses verifikasi sebagai tugas prediksi kata berikutnya, mengintegrasikan kemampuan pembuatan teks model bahasa besar (LLM) ke dalam proses verifikasi, dan mendukung penalaran rantai, sehingga mencapai verifikasi yang lebih komprehensif dan sistematis.
Baru-baru ini, tim peneliti Google DeepMind bekerja sama dengan sejumlah universitas untuk mengusulkan metode baru yang disebut Generative Reward Model (GenRM), yang bertujuan untuk meningkatkan akurasi dan keandalan AI generatif dalam tugas-tugas penalaran.
AI generatif banyak digunakan di banyak bidang seperti pemrosesan bahasa alami. AI ini terutama menghasilkan teks yang koheren dengan memprediksi kata berikutnya dari serangkaian kata. Namun, model-model ini kadang-kadang menghasilkan informasi yang salah, yang merupakan masalah besar terutama di bidang-bidang di mana akurasi sangat penting, seperti pendidikan, keuangan, dan layanan kesehatan.
Saat ini, para peneliti telah mencoba berbagai solusi terhadap kesulitan yang dihadapi model AI generatif dalam akurasi keluaran. Diantaranya, model penghargaan diskriminatif (RM) digunakan untuk menentukan apakah jawaban potensial benar berdasarkan skor, namun metode ini gagal memanfaatkan sepenuhnya kemampuan generatif model bahasa besar (LLM). Metode lain yang umum digunakan adalah "LLM sebagai hakim", namun metode ini seringkali tidak seefektif verifikator profesional ketika menyelesaikan tugas penalaran yang kompleks.
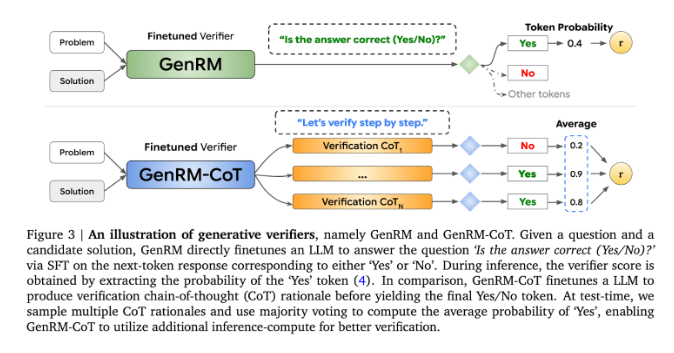
Inovasi GenRM adalah mendefinisikan ulang proses verifikasi sebagai tugas prediksi kata berikutnya. Artinya, tidak seperti model penghargaan diskriminatif tradisional, GenRM menggabungkan kemampuan pembuatan teks LLM ke dalam proses verifikasi, sehingga memungkinkan model tersebut secara bersamaan menghasilkan dan mengevaluasi solusi potensial. Selain itu, GenRM juga mendukung chained Reasoning (CoT), yaitu model dapat menghasilkan langkah-langkah penalaran perantara sebelum mencapai kesimpulan akhir, sehingga membuat proses verifikasi menjadi lebih komprehensif dan sistematis.
Dengan menggabungkan pembangkitan dan validasi, pendekatan GenRM mengadopsi strategi pelatihan terpadu yang memungkinkan model meningkatkan kemampuan pembangkitan dan validasi secara bersamaan selama pelatihan. Dalam aplikasi nyata, model menghasilkan langkah-langkah inferensi perantara yang digunakan untuk memverifikasi jawaban akhir.
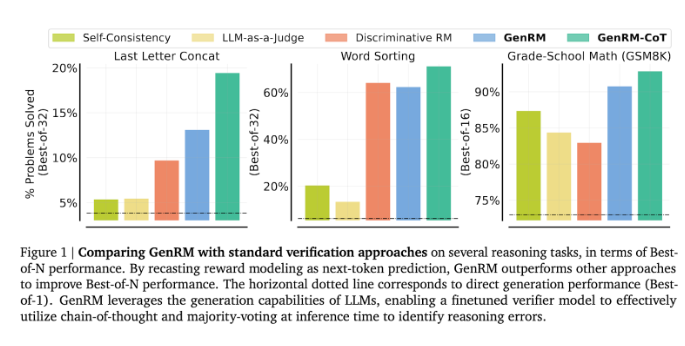
Para peneliti menemukan bahwa model GenRM berkinerja baik pada beberapa pengujian yang ketat, seperti meningkatkan akurasi matematika prasekolah dan tugas pemecahan masalah algoritmik secara signifikan. Dibandingkan dengan model penghargaan diskriminatif dan metode LLM sebagai juri, tingkat keberhasilan pemecahan masalah GenRM meningkat sebesar 16% menjadi 64%.
Misalnya, saat memverifikasi keluaran model Gemini1.0Pro, GenRM meningkatkan tingkat keberhasilan pemecahan masalah dari 73% menjadi 92,8%.
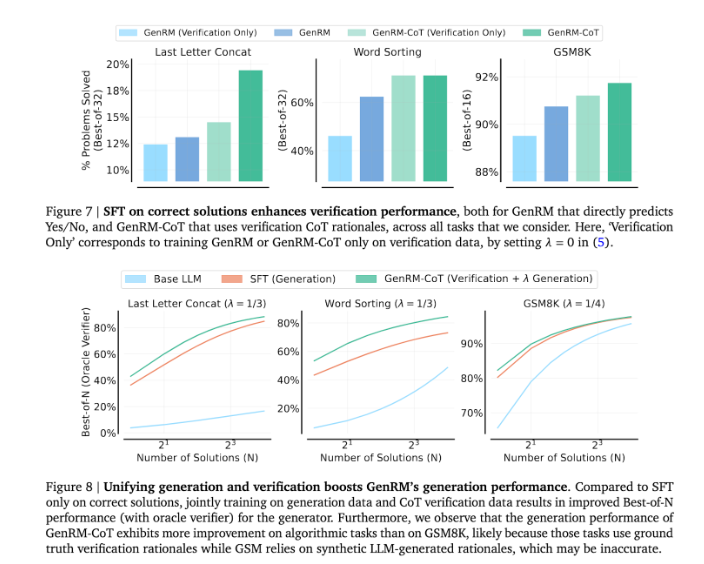
Pengenalan metode GenRM menandai kemajuan besar di bidang AI generatif, yang secara signifikan meningkatkan akurasi dan kepercayaan solusi yang dihasilkan AI dengan menyatukan pembuatan solusi dan verifikasi ke dalam satu proses.
Secara keseluruhan, kemunculan GenRM memberikan ide-ide baru untuk meningkatkan keandalan AI generatif. Peningkatan signifikan dalam memecahkan masalah penalaran yang kompleks menunjukkan kemungkinan penerapan AI generatif di lebih banyak bidang, sehingga layak untuk diteliti dan dieksplorasi lebih lanjut.