Baru-baru ini, sebuah penelitian yang diterbitkan di majalah Cureus menunjukkan bahwa model GPT-4 OpenAI berhasil lulus Ujian Terapi Fisik Nasional Jepang tanpa pelatihan tambahan. Para peneliti menguji GPT-4 menggunakan 1.000 soal yang meliputi memori, pemahaman, penerapan, analisis, dan evaluasi. Hasilnya menunjukkan tingkat akurasi sebesar 73,4% dan lulus kelima bagian tes. Penelitian ini menimbulkan kekhawatiran tentang potensi GPT-4 untuk aplikasi medis, sekaligus mengungkapkan keterbatasannya dalam menangani jenis masalah tertentu, seperti masalah praktis dan masalah yang berisi tabel bergambar.
Sebuah studi tinjauan sejawat baru-baru ini yang diterbitkan dalam jurnal Cureus menunjukkan bahwa model bahasa GPT-4 OpenAI berhasil lulus Ujian Terapi Fisik Nasional Jepang tanpa pelatihan tambahan apa pun.
Para peneliti memasukkan 1.000 pertanyaan ke dalam GPT-4, yang mencakup berbagai bidang seperti memori, pemahaman, penerapan, analisis, dan evaluasi. Hasilnya menunjukkan bahwa GPT-4 menjawab 73,4% pertanyaan dengan benar secara keseluruhan, dan lulus kelima bagian tes. Namun, penelitian juga mengungkapkan keterbatasan AI di beberapa bidang.

GPT-4 bekerja dengan baik pada soal umum, dengan akurasi 80,1%, tetapi hanya 46,6% pada soal praktis. Demikian pula, ia jauh lebih baik dalam menangani pertanyaan teks saja (80,5% benar) dibandingkan pertanyaan dengan gambar dan tabel (35,4% benar). Temuan ini konsisten dengan penelitian sebelumnya tentang keterbatasan pemahaman visual GPT-4.
Perlu diperhatikan bahwa tingkat kesulitan pertanyaan dan panjang teks memiliki pengaruh yang kecil terhadap performa GPT-4. Meskipun model ini terutama dilatih menggunakan data bahasa Inggris, model ini juga memiliki performa yang baik saat menangani masukan bahasa Jepang.
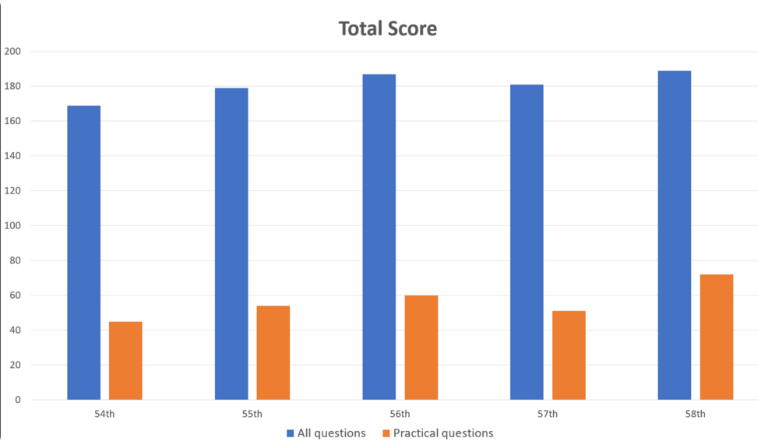
Para peneliti mencatat bahwa meskipun penelitian ini menunjukkan potensi GPT-4 dalam rehabilitasi klinis dan pendidikan kedokteran, penelitian ini harus dilihat dengan hati-hati. Mereka menekankan bahwa GPT-4 tidak menjawab semua pertanyaan dengan benar dan bahwa evaluasi versi baru serta kemampuan model dalam tes tertulis dan penalaran akan diperlukan di masa mendatang.
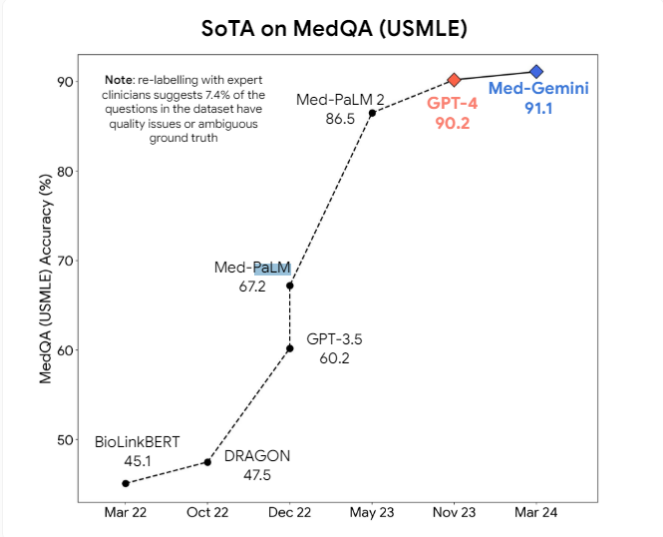
Selain itu, para peneliti mengusulkan bahwa model multi-modal seperti GPT-4v dapat membawa peningkatan lebih lanjut dalam pemahaman visual. Saat ini, model AI medis profesional seperti Med-PaLM2 dan Med-Gemini Google, serta model medis Meta berdasarkan Llama3, sedang dikembangkan secara aktif, dengan tujuan untuk melampaui model tujuan umum dalam tugas medis.
Namun, para ahli percaya bahwa mungkin diperlukan waktu yang lama sebelum model AI medis dapat digunakan secara luas dalam praktik. Ruang kesalahan model saat ini masih terlalu besar dalam lingkungan medis, dan diperlukan kemajuan signifikan dalam kemampuan inferensi untuk mengintegrasikan model ini dengan aman ke dalam praktik medis sehari-hari.
Meskipun penelitian ini menunjukkan potensi GPT-4 di bidang medis, penelitian ini juga mengingatkan kita bahwa teknologi AI masih perlu terus ditingkatkan sebelum benar-benar dapat diterapkan pada skenario medis yang kompleks. Di masa depan, model multi-modal dan kemampuan penalaran yang lebih kuat akan menjadi perbaikan utama untuk menjamin keamanan dan keandalan AI dalam perawatan medis.