Bidang kecerdasan buatan telah berkomitmen untuk memungkinkan mesin memahami dunia fisik yang kompleks. Terobosan di bidang ini sangat penting di banyak bidang. Baru-baru ini, tim peneliti dari Universitas Renmin Tiongkok, Universitas Pos dan Telekomunikasi Beijing, Lab AI Shanghai, dan institusi lainnya telah mengembangkan teknologi Ref-AVS, yang memberikan solusi baru untuk masalah ini. Teknologi Ref-AVS mengintegrasikan berbagai informasi modal seperti segmentasi objek video, segmentasi referensi objek video, dan segmentasi audio-visual melalui metode fusi multi-modal yang cerdas, memungkinkan sistem AI untuk lebih akurat memahami instruksi bahasa alami dan melakukan audio yang kompleks. tugas visual. Penempatan objek target yang tepat dalam pemandangan mendobrak keterbatasan AI sebelumnya dalam pemahaman multi-modal.
Di bidang kecerdasan buatan, membuat mesin memahami dunia fisik yang kompleks seperti manusia selalu menjadi tantangan besar. Baru-baru ini, tim peneliti yang terdiri dari Universitas Renmin Tiongkok, Universitas Pos dan Telekomunikasi Beijing, Lab AI Shanghai, dan lembaga lainnya mengusulkan teknologi terobosan - Ref-AVS, yang membawa harapan baru untuk memecahkan masalah ini.
Inti dari teknologi Ref-AVS terletak pada metode fusi multimodalnya yang unik. Ini secara cerdik mengintegrasikan beberapa informasi modal seperti segmentasi objek video (VOS), segmentasi referensi objek video (Ref-VOS), dan segmentasi audio-visual (AVS). Penggabungan inovatif ini memungkinkan sistem AI tidak hanya memproses objek yang mengeluarkan suara, tetapi juga mengidentifikasi objek yang tidak bersuara tetapi sama pentingnya dalam pemandangan. Terobosan ini memungkinkan AI untuk lebih akurat memahami instruksi yang dijelaskan oleh pengguna melalui bahasa alami dan secara akurat menemukan lokasi objek tertentu dalam adegan audio-visual yang kompleks.
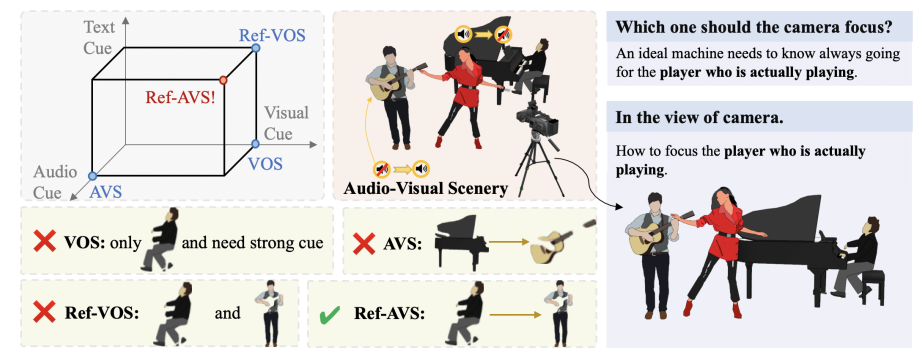
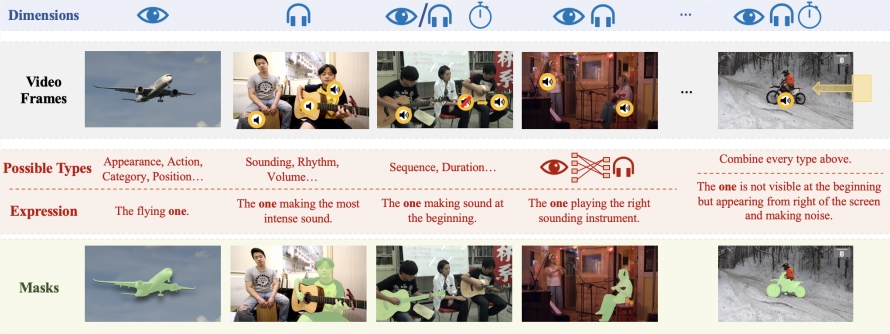
Untuk mendukung penelitian dan verifikasi teknologi Ref-AVS, tim peneliti membangun kumpulan data berskala besar yang disebut Ref-AVS Bench. Kumpulan data ini berisi 40.020 bingkai video yang mencakup 6.888 objek dan 20.261 ekspresi rujukan. Setiap frame video disertai dengan audio yang sesuai dan anotasi detail tingkat piksel. Kumpulan data yang kaya dan beragam ini memberikan landasan yang kuat untuk penelitian multimodal dan membuka kemungkinan baru untuk penelitian masa depan di bidang terkait.
Dalam serangkaian eksperimen kuantitatif dan kualitatif yang ketat, teknologi Ref-AVS menunjukkan kinerja yang sangat baik. Khususnya pada subset Seen, Ref-AVS mengungguli metode lain yang sudah ada, membuktikan sepenuhnya kemampuan segmentasinya yang kuat. Yang lebih penting adalah bahwa hasil pengujian pada subset Unseen dan Null semakin memverifikasi kemampuan generalisasi yang sangat baik dan ketahanan teknologi Ref-AVS terhadap referensi null, yang sangat penting untuk skenario aplikasi praktis.
Keberhasilan teknologi Ref-AVS tidak hanya menarik perhatian luas di dunia akademis, namun juga membuka jalur baru untuk penerapan praktis di masa depan. Kita dapat memperkirakan bahwa teknologi ini akan memainkan peran penting dalam banyak bidang seperti analisis video, pemrosesan gambar medis, mengemudi otonom, dan navigasi robot. Misalnya, di bidang medis, Ref-AVS dapat membantu dokter menafsirkan gambar medis yang kompleks dengan lebih akurat; di bidang mengemudi otonom, hal ini dapat meningkatkan persepsi kendaraan terhadap lingkungan sekitar; dalam bidang robotika, hal ini memungkinkan robot untuk lebih memahami dan melaksanakan instruksi verbal manusia.
Hasil penelitian ini telah dipresentasikan di ECCV2024, dan makalah serta informasi proyek yang relevan juga telah dipublikasikan, sehingga memberikan sumber pembelajaran dan eksplorasi yang berharga bagi para peneliti dan pengembang di seluruh dunia yang tertarik pada bidang ini. Sikap terbuka dan berbagi ini tidak hanya mencerminkan semangat akademis tim peneliti ilmiah Tiongkok, namun juga akan mendorong perkembangan pesat seluruh bidang AI.
Munculnya teknologi Ref-AVS menandai langkah penting dalam pemahaman multimodal kecerdasan buatan. Hal ini tidak hanya menunjukkan kemampuan inovatif tim peneliti ilmiah Tiongkok di bidang AI, namun juga memberikan cetak biru yang lebih cerdas dan alami untuk masa depan interaksi manusia-komputer. Seiring dengan penyempurnaan dan penerapan teknologi ini, kami memiliki alasan untuk berharap bahwa sistem AI di masa depan akan mampu memahami dan beradaptasi dengan lebih baik terhadap dunia manusia yang kompleks dan membawa perubahan revolusioner pada semua lapisan masyarakat.
Alamat makalah: https://arxiv.org/abs/2407.10957
Halaman beranda proyek:
https://gewu-lab.github.io/Ref-AVS/
Singkatnya, kemunculan teknologi Ref-AVS telah membawa terobosan baru di bidang pemahaman multi-modal kecerdasan buatan. Performanya yang kuat dan prospek penerapannya yang luas patut dinantikan. Teknologi ini akan mendorong pengembangan kecerdasan buatan menuju interaksi yang lebih cerdas dan alami, sehingga memberikan lebih banyak kenyamanan bagi masyarakat manusia.