Baru-baru ini, MLCommons merilis hasil inferensi MLPerf v4.1. Beberapa produsen chip inferensi AI berpartisipasi, dan persaingannya sangat ketat. Untuk pertama kalinya, kompetisi ini menghadirkan chip dari AMD, Google, UntetherAI dan pabrikan lainnya, serta chip Blackwell terbaru dari Nvidia. Selain perbandingan kinerja, efisiensi energi juga menjadi dimensi kompetitif yang penting. Berbagai produsen telah menunjukkan keahlian khusus mereka dan menunjukkan keunggulan masing-masing dalam berbagai pengujian benchmark, membawa vitalitas baru ke pasar chip inferensi AI.
Di bidang pelatihan kecerdasan buatan, kartu grafis Nvidia hampir tak tertandingi, namun dalam hal inferensi AI, para pesaing tampaknya mulai mengejar ketertinggalan, terutama dalam hal efisiensi energi. Terlepas dari kinerja yang kuat dari chip Blackwell terbaru Nvidia, tidak jelas apakah chip tersebut dapat mempertahankan keunggulannya. Hari ini, ML Commons mengumumkan hasil kompetisi inferensi AI terbaru - MLPerf Inference v4.1. Untuk pertama kalinya, akselerator Instinct AMD, akselerator Trillium Google, chip startup Kanada UntetherAI, dan chip Blackwell Nvidia berpartisipasi. Dua perusahaan lainnya, Cerebras dan FuriosaAI, telah meluncurkan chip inferensi baru tetapi belum mengirimkan MLPerf untuk pengujian.
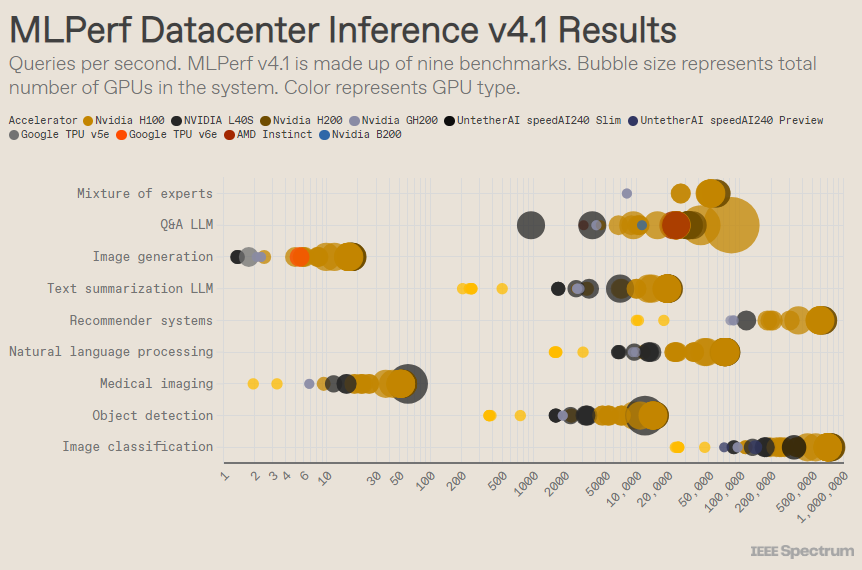
MLPerf disusun seperti kompetisi Olimpiade, dengan banyak acara dan sub-acara. Kategori “Data Center Enclosure” memiliki entri terbanyak. Berbeda dengan kategori terbuka, kategori tertutup mengharuskan peserta untuk melakukan inferensi secara langsung pada model tertentu tanpa memodifikasi perangkat lunak secara signifikan. Kategori pusat data terutama menguji kemampuan untuk memproses permintaan secara batch, sedangkan kategori edge berfokus pada pengurangan latensi.
Ada 9 tolok ukur berbeda di setiap kategori, yang mencakup berbagai tugas AI, termasuk pembuatan gambar populer (misalnya Midjourney) dan menjawab pertanyaan dengan model bahasa besar (seperti ChatGPT), serta beberapa tugas penting namun kurang dikenal, Seperti sebagai klasifikasi gambar, deteksi objek, dan mesin rekomendasi.
Putaran ini menambahkan tolok ukur baru - "model hybrid ahli". Ini adalah metode penerapan model bahasa yang semakin populer yang membagi model bahasa menjadi beberapa model kecil yang independen, masing-masing disesuaikan untuk tugas tertentu, seperti percakapan sehari-hari, memecahkan masalah matematika, atau bantuan pemrograman. Dengan menugaskan setiap query ke model kecilnya yang sesuai, pemanfaatan sumber daya berkurang, menurunkan biaya dan meningkatkan hasil, kata Miroslav Hodak, anggota staf teknis senior di AMD.

Dalam tolok ukur "pusat data tertutup" yang populer, pemenang masih merupakan kiriman berdasarkan GPU Nvidia H200 dan superchip GH200, yang menggabungkan GPU dan CPU dalam satu paket. Namun, jika dilihat lebih dekat hasilnya mengungkapkan beberapa detail menarik. Beberapa pesaing menggunakan beberapa akselerator, sementara yang lain hanya menggunakan satu akselerator. Hasilnya bahkan lebih membingungkan jika kita menormalkan kueri per detik berdasarkan jumlah akselerator dan mempertahankan kiriman dengan kinerja terbaik untuk setiap jenis akselerator. Perlu dicatat bahwa pendekatan ini mengabaikan peran CPU dan interkoneksi.
Pada basis per-akselerator, Blackwell dari Nvidia unggul dalam tugas tanya jawab model bahasa besar, memberikan kecepatan 2,5x dibandingkan iterasi chip sebelumnya, satu-satunya tolok ukur yang diajukan. Chip pratinjau speedAI240 Untether AI berkinerja hampir sama baiknya dengan H200 pada satu-satunya tugas pengenalan gambar yang dikirimkan kepadanya. Trillium Google berkinerja sedikit lebih rendah daripada H100 dan H200 pada tugas pembuatan gambar, sedangkan AMD Instinct berkinerja setara dengan H100 pada tugas tanya jawab model bahasa besar.
Bagian dari kesuksesan Blackwell berasal dari kemampuannya menjalankan model bahasa besar menggunakan presisi floating point 4-bit. Nvidia dan pesaingnya telah berupaya mengurangi jumlah bit yang direpresentasikan dalam model transformasi seperti ChatGPT untuk mempercepat penghitungan. Nvidia memperkenalkan matematika 8-bit di H100, dan kiriman ini adalah demonstrasi pertama matematika 4-bit di benchmark MLPerf.
Tantangan terbesar dalam bekerja dengan angka berpresisi rendah adalah menjaga akurasi, kata Dave Salvator, direktur pemasaran produk Nvidia. Untuk menjaga akurasi tinggi dalam pengiriman MLPerf, tim Nvidia telah melakukan banyak inovasi pada perangkat lunaknya.
Selain itu, bandwidth memori Blackwell hampir dua kali lipat menjadi 8 terabyte per detik, dibandingkan dengan H200 yang sebesar 4,8 terabyte.
Pengajuan Nvidia Blackwell menggunakan satu chip, tetapi Salvator mengatakan itu dirancang untuk jaringan dan penskalaan, dan akan bekerja paling baik bila dikombinasikan dengan interkoneksi NVLink Nvidia. GPU Blackwell mendukung koneksi hingga 18 NVLink 100GB per detik, dengan total bandwidth 1,8 terabyte per detik, hampir dua kali lipat bandwidth interkoneksi H100.
Salvator percaya bahwa ketika model bahasa besar terus berkembang, bahkan inferensi akan memerlukan platform multi-GPU untuk memenuhi permintaan, dan Blackwell dirancang untuk situasi ini. “Havel adalah sebuah platform,” kata Salvator.
Nvidia menyerahkan sistem chip Blackwell-nya ke subkategori Pratinjau, artinya sistem tersebut belum tersedia, namun diperkirakan akan tersedia sebelum rilis MLPerf berikutnya, yaitu sekitar enam bulan dari sekarang.
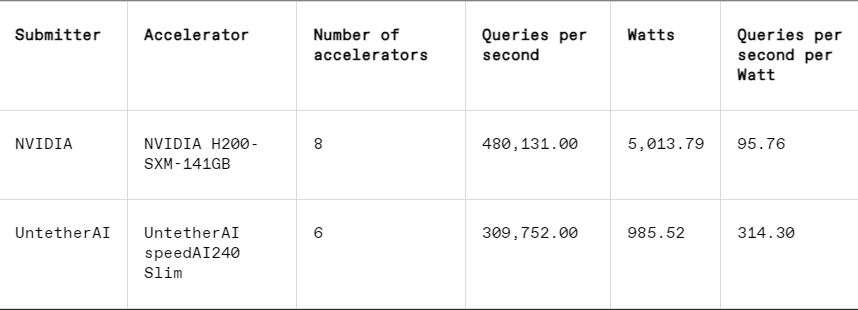
Di setiap benchmark, MLPerf juga menyertakan bagian pengukuran energi yang secara sistematis menguji konsumsi daya aktual setiap sistem saat menjalankan tugas. Kompetisi utama babak ini (Kategori Energi Tertutup Pusat Data) hanya diikuti oleh dua peserta, yaitu Nvidia dan Untether AI. Meskipun Nvidia berpartisipasi dalam semua benchmark, Untether hanya memberikan hasil pada tugas pengenalan gambar.
Untether AI unggul dalam hal ini, berhasil mencapai efisiensi energi yang sangat baik. Chip mereka menggunakan pendekatan yang disebut "komputasi dalam memori". Chip Untether AI terdiri dari kumpulan sel memori dengan prosesor kecil di dekatnya. Setiap prosesor bekerja secara paralel, memproses data secara bersamaan dengan unit memori yang berdekatan, sehingga secara signifikan mengurangi waktu dan energi yang dihabiskan untuk mentransfer data model antara memori dan inti komputasi.
“Kami menemukan bahwa saat menjalankan beban kerja AI, 90% konsumsi energi digunakan untuk memindahkan data dari DRAM ke unit pemrosesan cache,” kata Robert Beachler, wakil presiden produk di Untether AI. “Jadi yang dilakukan Untether adalah memindahkan komputasi lebih dekat ke data, dibandingkan memindahkan data ke unit komputasi.”
Pendekatan ini bekerja sangat baik di subkategori MLPerf lainnya: penutupan tepi. Kategori ini berfokus pada kasus penggunaan yang lebih praktis, seperti inspeksi mesin di pabrik, robot penglihatan terpandu, dan kendaraan otonom—aplikasi yang memiliki persyaratan ketat untuk efisiensi energi dan pemrosesan cepat, jelas Beachler.
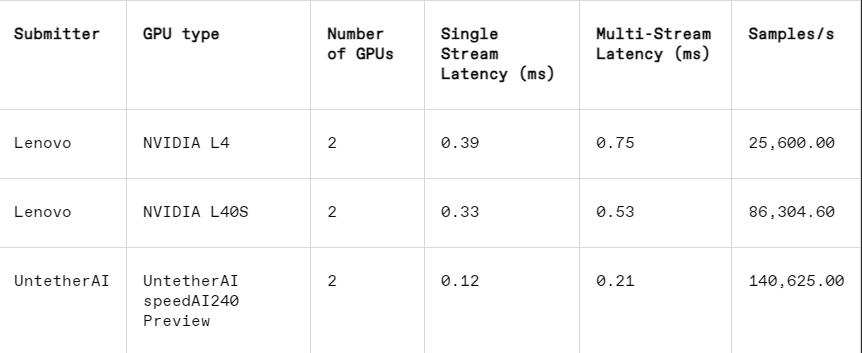
Dalam tugas pengenalan gambar, kinerja latensi chip pratinjau speedAI240 Untether AI 2,8 kali lebih cepat dibandingkan L40S Nvidia, dan throughput (jumlah sampel per detik) juga meningkat 1,6 kali lipat. Startup ini juga menyampaikan hasil konsumsi daya dalam kategori ini, namun pesaing Nvidia tidak melakukannya, sehingga membuat perbandingan langsung menjadi sulit. Namun, chip pratinjau speedAI240 Untether AI memiliki konsumsi daya nominal 150 watt, sedangkan L40S Nvidia memiliki 350 watt, menunjukkan keunggulan 2,3x dalam konsumsi daya dan kinerja latensi yang lebih baik.
Meski Cerebras dan Furiosa tidak mengikuti MLPerf, mereka juga merilis chip baru masing-masing. Cerebras meluncurkan layanan inferensinya pada konferensi IEEE Hot Chips di Universitas Stanford. Cerebras yang berbasis di Sunny Valley, California memproduksi chip raksasa sebesar yang dimungkinkan oleh wafer silikon, sehingga menghindari interkoneksi antar chip dan meningkatkan bandwidth memori perangkat secara signifikan. Chip tersebut terutama digunakan untuk melatih jaringan saraf raksasa. Kini, mereka telah mengupgrade komputer terbaru mereka, CS3, untuk mendukung inferensi.
Meskipun Cerebras tidak mengirimkan MLPerf, perusahaan mengklaim bahwa platformnya mengungguli H100 sebesar 7x dan chip Groq pesaingnya sebesar 2x dalam jumlah token LLM yang dihasilkan per detik. “Saat ini, kita berada di era AI generatif dial-up,” kata Andrew Feldman, CEO dan salah satu pendiri Cerebras. “Ini semua karena ada hambatan bandwidth memori. Baik itu Nvidia H100, AMD MI300, atau TPU, semuanya menggunakan memori eksternal yang sama, sehingga menghasilkan batasan yang sama. Kami mendobrak penghalang itu karena kami melakukannya pada desain tingkat wafer. "
Pada konferensi Hot Chips, Furiosa dari Seoul juga mendemonstrasikan chip generasi kedua RNGD (diucapkan "pemberontak"). Chip baru Furiosa menampilkan arsitektur Tensor Contraction Processor (TCP). Dalam beban kerja AI, fungsi matematika dasar adalah perkalian matriks, yang sering kali diimplementasikan dalam perangkat keras sebagai primitif. Namun, ukuran dan bentuk matriks, yaitu tensor yang lebih lebar, dapat sangat bervariasi. RNGD mengimplementasikan perkalian tensor yang lebih umum ini sebagai perkalian primitif. “Selama inferensi, ukuran batch sangat bervariasi, jadi sangat penting untuk memanfaatkan sepenuhnya paralelisme yang melekat dan penggunaan kembali data dari bentuk tensor tertentu,” kata June Paik, pendiri dan CEO Furiosa, di Hot Chips.
Meskipun Furiosa tidak memiliki MLPerf, mereka membandingkan chip RNGD dengan tolok ukur ringkasan LLM MLPerf dalam pengujian internal, dan hasilnya sebanding dengan chip L40S Nvidia, tetapi hanya mengonsumsi 185 watt dibandingkan dengan L40S yang 320 watt. Paik mengatakan kinerja akan meningkat dengan optimalisasi perangkat lunak lebih lanjut.
IBM juga mengumumkan peluncuran chip Spyre barunya, yang dirancang bagi perusahaan untuk menghasilkan beban kerja AI dan diharapkan akan tersedia pada kuartal pertama tahun 2025.
Jelas, pasar chip inferensi AI akan ramai di masa mendatang.
Referensi: https://spectrum.ieee.org/new-inference-chips
Secara keseluruhan, hasil MLPerf v4.1 menunjukkan persaingan pasar chip inferensi AI semakin ketat. Meski Nvidia masih tetap memimpin, kebangkitan pabrikan seperti AMD, Google, dan Untether AI tidak bisa diabaikan. Di masa depan, efisiensi energi akan menjadi faktor kompetitif utama, dan teknologi baru seperti komputasi dalam memori juga akan memainkan peran penting. Inovasi teknologi dari berbagai produsen akan terus mendorong peningkatan kemampuan penalaran AI dan memberikan dorongan kuat untuk mempopulerkan dan mengembangkan aplikasi AI.