Komunitas ModelScope telah membuat versi open source yang ditingkatkan dari model pembuatan video Sora open source domestiknya CogVideoX - CogVideoX-5B, yang merupakan model pembuatan teks-ke-video berdasarkan model DiT skala besar. Dibandingkan dengan CogVideoX-2B sebelumnya, model baru ini telah meningkatkan kualitas video dan efek visual secara signifikan. CogVideoX-5B menggunakan autoencoder variasi kausal 3D (VAE kausal 3D) dan teknologi Transformer ahli, serta menggunakan 3D-RoPE sebagai pengkodean posisi dan mekanisme perhatian penuh 3D untuk pemodelan sendi spatio-temporal , video dengan kualitas lebih tinggi dan lebih banyak fitur gerakan.
Dibandingkan dengan CogVideoX-2B sebelumnya, model baru ini telah meningkatkan kualitas dan efek visual pembuatan video secara signifikan.
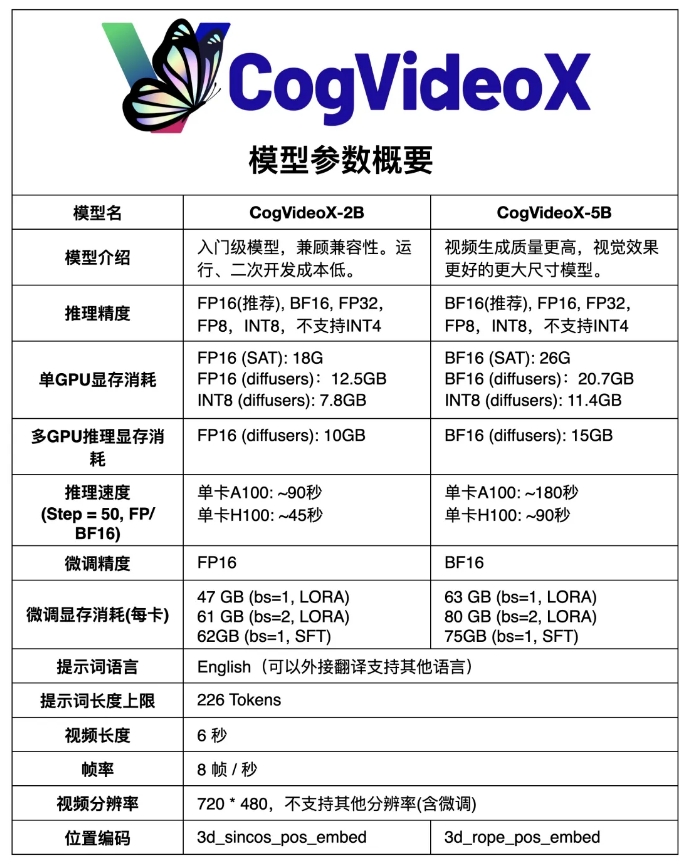
CogVideoX-5B didasarkan pada model DiT (transformator difusi) skala besar, yang dirancang khusus untuk tugas pembuatan teks-ke-video. Model ini mengadopsi autoencoder variasi kausal 3D (VAE kausal 3D) dan teknologi Transformer ahli, menggabungkan penyematan teks dan video, menggunakan 3D-RoPE sebagai pengkodean posisi, dan menggunakan mekanisme perhatian penuh 3D untuk pemodelan gabungan spatio-temporal.
Selain itu, model ini mengadopsi teknologi pelatihan progresif dan mampu menghasilkan video berkualitas tinggi yang koheren dan berjangka panjang dengan fitur gerakan yang signifikan.
Tautan model:
https://modelscope.cn/models/ZhipuAI/CogVideoX-5b
Sumber terbuka CogVideoX-5B telah membawa terobosan teknologi baru dan peluang pengembangan di bidang pembuatan video AI dalam negeri, dan juga menyediakan alat dan sumber daya yang ampuh bagi para peneliti dan pengembang. Dipercaya bahwa lebih banyak aplikasi inovatif berdasarkan CogVideoX-5B akan muncul di masa depan, mendorong kemajuan berkelanjutan dalam teknologi pembuatan video AI. Akses yang mudah terhadap model ini juga menurunkan ambang batas untuk penelitian dan penerapan, sehingga mendorong penyebaran dan penerapan teknologi yang lebih luas.