Dalam beberapa tahun terakhir, kinerja model bahasa besar (LLM) telah menarik banyak perhatian. Artikel ini memperkenalkan penelitian yang menarik. Penelitian ini menantang konsep "model yang lebih besar dan lebih baik" tradisional, memberikan ide dan arahan baru untuk pengembangan LLM di masa depan, dan juga memberikan lebih banyak kemungkinan bagi para peneliti dan pengembang sumber daya yang terbatas. Ini mengungkapkan potensi besar dari strategi pencarian dalam meningkatkan kemampuan penalaran model dan pemicu dalam pemikiran -yang lebih baik tentang hubungan antara sumber daya komputasi dan parameter model.
Baru -baru ini, sebuah studi baru telah menarik dan membuktikan bahwa model bahasa besar (LLM) dapat secara signifikan meningkatkan kinerja melalui fungsi pencarian. Secara khusus, model LLAMA3.1 dengan volume parameter hanya 800 juta yang dilewati melalui 100 pencarian, dan itu tidak sebanding dengan GPT-4O dalam kode Python.
Gagasan ini tampaknya mengingatkan orang -orang tentang The Pioneer of Learning, posting blog klasik Rich Sutton "The Bitter Lesson" pada tahun 2019. Dia menyebutkan bahwa dengan peningkatan daya komputasi, kita perlu mengenali kekuatan metode umum. Secara khusus, dua metode "pencarian" dan "belajar" tampaknya menjadi pilihan yang sangat baik yang dapat terus berkembang.
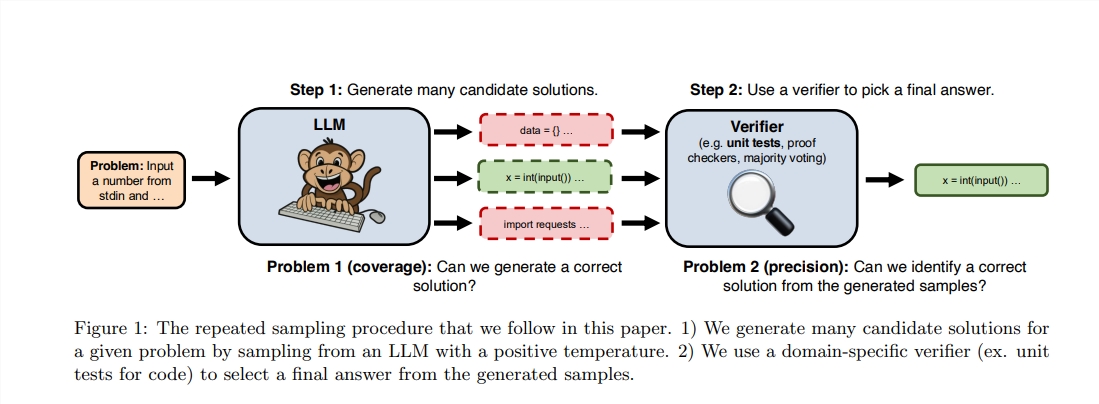
Meskipun Sutton menekankan pentingnya belajar, yaitu, model yang lebih besar biasanya dapat mempelajari lebih banyak pengetahuan, tetapi kita sering mengabaikan potensi pencarian dalam proses penalaran. Baru -baru ini, para peneliti dari Stanford, Oxford dan Deepmind menemukan bahwa meningkatkan jumlah waktu pengambilan sampel yang berulang selama tahap penalaran dapat secara signifikan meningkatkan kinerja model di bidang matematika, penalaran dan pembuatan kode.
Setelah terinspirasi oleh studi ini, kedua insinyur memutuskan untuk melakukan eksperimen. Mereka menemukan bahwa menggunakan 100 model Llama kecil untuk pencarian dapat melampaui dan bahkan mengikat GPT-4O dalam tugas pemrograman Python. Mereka menggunakan metafora yang jelas untuk menggambarkan: "Di masa lalu, Malaysia Malaysia dapat mencapai beberapa kemampuan. Sekarang, hanya 100 bebek yang dapat menyelesaikan hal yang sama."
Untuk mencapai kinerja yang lebih tinggi, mereka menggunakan perpustakaan VLLM untuk melakukan penalaran batch dan berjalan pada 10 A100-40GB GPU. Penulis memilih tes benchmark humaneval karena dapat menjalankan kode yang dihasilkan dengan menjalankan evaluasi uji, yang lebih objektif dan akurat.
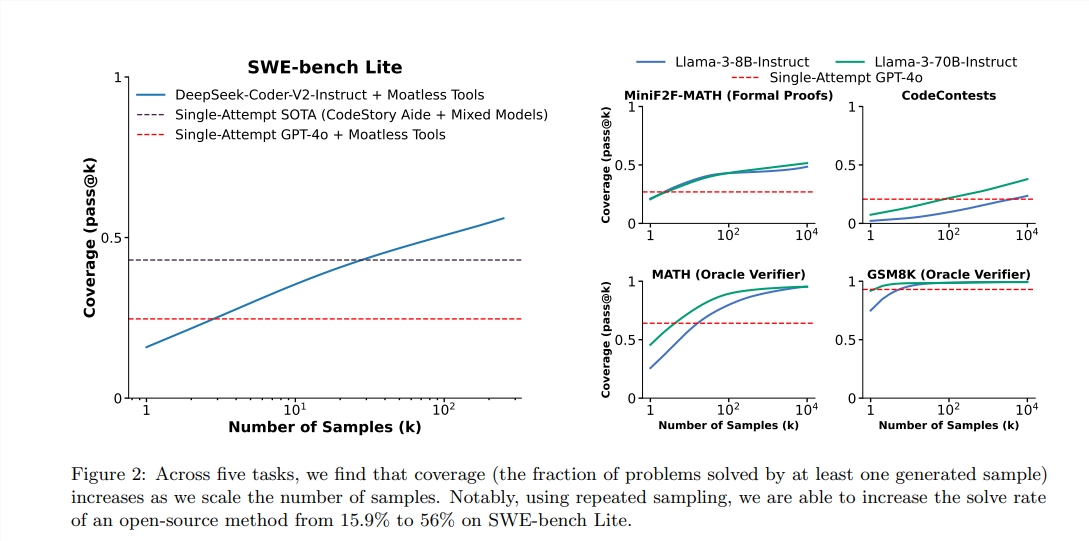
Menurut laporan itu, skor pass@1 dari GPT-4O adalah 90,2%dalam penalaran sampel nol. Melalui metode di atas, skor lulus@K dari LLAMA3.18B juga telah meningkat secara signifikan. Ketika jumlah pengambilan sampel yang diulang adalah 100, skor Llama mencapai 90,5%; ketika jumlah pengambilan sampel yang diulang meningkat menjadi 1.000, hasilnya lebih lanjut meningkat menjadi 95,1%, yang secara signifikan lebih baik daripada GPT-4O.
Perlu disebutkan bahwa meskipun percobaan ini bukan reproduksi ketat dari penelitian asli, ia menekankan bahwa ketika metode pencarian meningkatkan tahap penalaran, model yang lebih kecil juga dapat melampaui kemungkinan model besar dalam kisaran yang dapat diperkirakan.
Pencarian kuat karena dapat "secara transparan" berkembang dengan peningkatan perhitungan dan mentransfer sumber daya dari memori ke perhitungan, dengan demikian mencapai keseimbangan sumber daya. Baru -baru ini, DeepMind telah membuat kemajuan penting di bidang matematika, membuktikan kekuatan pencarian.
Namun, keberhasilan pencarian pertama -tama perlu melakukan penilaian hasil berkualitas tinggi. Model DeepMind telah mencapai pengawasan yang efektif dengan mengubah masalah matematika dalam bahasa alami untuk membentuk ekspresi formal. Di daerah lain, tugas NLP terbuka seperti "Ringkasan Email" jauh lebih sulit untuk melakukan pencarian yang efektif.
Studi ini menunjukkan bahwa peningkatan kinerja model pembangkit di bidang tertentu terkait dengan evaluasi dan kemampuan pencariannya, dan penelitian di masa depan dapat mengeksplorasi cara meningkatkan kemampuan ini melalui lingkungan digital yang berulang.
Alamat tesis: https: //arxiv.org/pdf/2407.21787
Secara keseluruhan, penelitian ini memberikan perspektif baru untuk peningkatan kinerja model bahasa besar. Di masa depan, cara menggabungkan strategi pembelajaran dan pencarian secara efektif akan menjadi arah yang penting untuk pengembangan LLM. Tautan tertaut dari penelitian ini juga telah disediakan, dan pembaca yang tertarik dapat lebih memahaminya.