Kebangkitan arsitektur Transformer telah merevolusi bidang pemrosesan bahasa alami, namun biaya komputasi yang tinggi telah menjadi hambatan saat memproses teks yang panjang. Menanggapi masalah ini, artikel ini memperkenalkan metode baru yang disebut Tree Attention, yang secara efektif mengurangi kompleksitas komputasi perhatian mandiri model Transformer konteks panjang melalui pengurangan pohon, dan memanfaatkan sepenuhnya kekuatan cluster GPU modern sangat meningkatkan efisiensi komputasi.
Di era ledakan informasi ini, kecerdasan buatan ibarat bintang terang yang menerangi langit malam kebijaksanaan manusia. Di antara bintang-bintang ini, arsitektur Transformer tidak diragukan lagi adalah yang paling mempesona. Dengan mekanisme perhatian diri sebagai intinya, arsitektur ini memimpin era baru pemrosesan bahasa alami. Namun, bintang paling terang sekalipun memiliki sudut yang sulit dijangkau. Untuk model Transformer konteks panjang, tingginya konsumsi sumber daya untuk penghitungan perhatian mandiri menjadi masalah. Bayangkan Anda mencoba membuat AI memahami sebuah artikel yang panjangnya puluhan ribu kata. Setiap kata harus dibandingkan dengan setiap kata lain dalam artikel tersebut. Jumlah perhitungannya tidak diragukan lagi sangat besar.
Untuk mengatasi masalah ini, sekelompok ilmuwan dari Zyphra dan EleutherAI mengusulkan metode baru yang disebut Tree Attention.
Perhatian diri, sebagai inti dari model Transformer, kompleksitas komputasinya meningkat secara kuadrat seiring bertambahnya panjang urutan. Hal ini menjadi kendala yang tidak dapat diatasi ketika berhadapan dengan teks yang panjang, terutama untuk model bahasa besar (LLM).
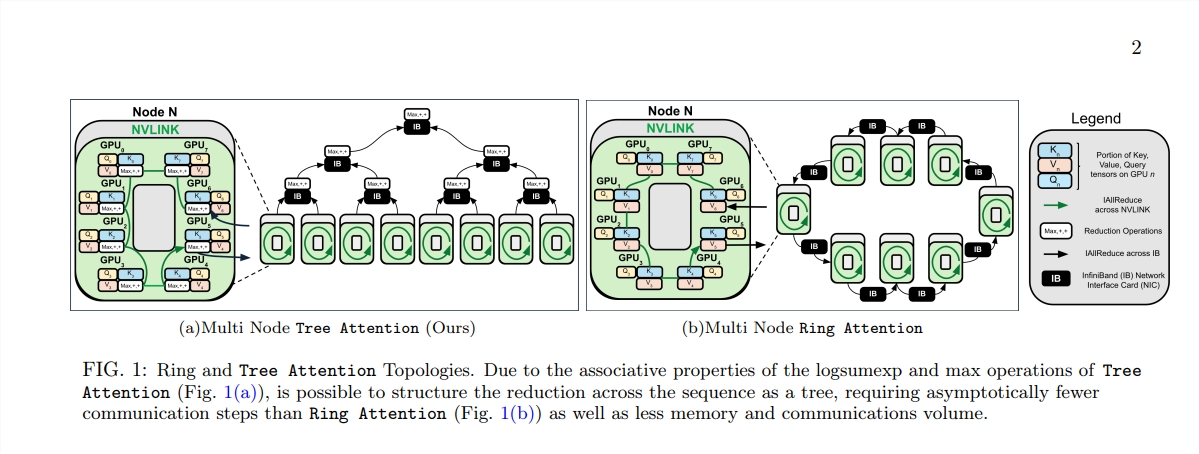
Lahirnya Tree Attention ibarat menanam pohon yang dapat melakukan perhitungan efisien di hutan komputasi ini. Ini menguraikan perhitungan perhatian diri menjadi beberapa tugas paralel melalui pengurangan pohon. Setiap tugas seperti daun di pohon, yang bersama-sama membentuk pohon yang lengkap.
Yang lebih menakjubkan lagi adalah para pengusul Tree Attention juga memperoleh fungsi energi dari self-attention, yang tidak hanya memberikan penjelasan Bayesian untuk self-attention, namun juga menghubungkannya secara erat dengan model energi seperti stand up jaringan Hopfield.
Tree Attention juga mempertimbangkan secara khusus topologi jaringan cluster GPU modern dan mengurangi kebutuhan komunikasi lintas node dengan secara cerdas memanfaatkan koneksi bandwidth tinggi dalam cluster, sehingga meningkatkan efisiensi komputasi.
Melalui serangkaian eksperimen, para ilmuwan memverifikasi kinerja Tree Attention pada panjang urutan dan jumlah GPU yang berbeda. Hasilnya menunjukkan bahwa Tree Attention hingga 8 kali lebih cepat dibandingkan metode Ring Attention yang ada saat mendekode pada beberapa GPU, sekaligus mengurangi volume komunikasi dan penggunaan memori puncak secara signifikan.
Usulan Tree Attention tidak hanya memberikan solusi efisien untuk penghitungan model perhatian konteks panjang, tetapi juga memberikan perspektif baru bagi kita untuk memahami mekanisme internal model Transformer. Seiring dengan kemajuan teknologi AI, kami memiliki alasan untuk percaya bahwa Tree Attention akan memainkan peran penting dalam penelitian dan penerapan AI di masa depan.
Alamat kertas: https://mp.weixin.qq.com/s/U9FaE6d-HJGsUs7u9EKKuQ
Kemunculan Tree Attention memberikan solusi yang efisien dan inovatif untuk mengatasi hambatan komputasi pada pemrosesan teks yang panjang. Hal ini memiliki arti yang luas bagi pemahaman dan pengembangan model Transformer di masa depan. Metode ini tidak hanya mencapai peningkatan kinerja yang signifikan, namun yang lebih penting, memberikan ide dan arahan baru untuk penelitian selanjutnya, yang layak untuk dikaji dan didiskusikan secara mendalam.