Andrej Karpathy, pakar di bidang AI, baru-baru ini mempertanyakan pembelajaran penguatan berdasarkan umpan balik manusia (RLHF), percaya bahwa ini bukan satu-satunya cara untuk mencapai AI setingkat manusia, yang telah memicu kekhawatiran luas dan diskusi panas di industri. . Dia percaya bahwa RLHF lebih merupakan tindakan sementara daripada solusi akhir, dan mengambil AlphaGo sebagai contoh untuk membandingkan perbedaan dalam pemecahan masalah antara pembelajaran penguatan nyata dan RLHF. Pandangan Karpathy tidak diragukan lagi memberikan perspektif baru terhadap arah penelitian AI saat ini dan juga membawa tantangan baru bagi pengembangan AI di masa depan.
Baru-baru ini, Andrej Karpathy, seorang peneliti terkenal di industri AI, mengemukakan sudut pandang kontroversial. Dia percaya bahwa pembelajaran penguatan berdasarkan teknologi umpan balik manusia (RLHF) yang saat ini banyak dipuji mungkin bukan satu-satunya cara untuk mencapainya kemampuan pemecahan masalah tingkat manusia yang sebenarnya. Pernyataan ini tidak diragukan lagi memberikan dampak besar pada bidang penelitian AI saat ini.
RLHF pernah dianggap sebagai faktor kunci keberhasilan model bahasa skala besar (LLM) seperti ChatGPT, dan dipuji sebagai senjata rahasia yang memberikan pemahaman, kepatuhan, dan kemampuan interaksi alami kepada AI. Dalam proses pelatihan AI tradisional, RLHF biasanya digunakan sebagai penghubung terakhir setelah pra-pelatihan dan penyempurnaan yang diawasi (SFT). Namun, Karpathy membandingkan RLHF dengan sebuah hambatan dan upaya sementara, karena ia yakin bahwa hal ini bukanlah solusi akhir bagi evolusi AI.
Karpathy dengan cerdik membandingkan RLHF dengan AlphaGo milik DeepMind. AlphaGo menggunakan apa yang dia sebut sebagai teknologi RL (pembelajaran penguatan) yang sebenarnya, dan dengan terus-menerus bermain melawan dirinya sendiri dan memaksimalkan tingkat kemenangannya, ia akhirnya melampaui pemain catur manusia terbaik tanpa campur tangan manusia. Pendekatan ini mencapai tingkat kinerja manusia super dengan mengoptimalkan jaringan saraf untuk belajar langsung dari hasil permainan.
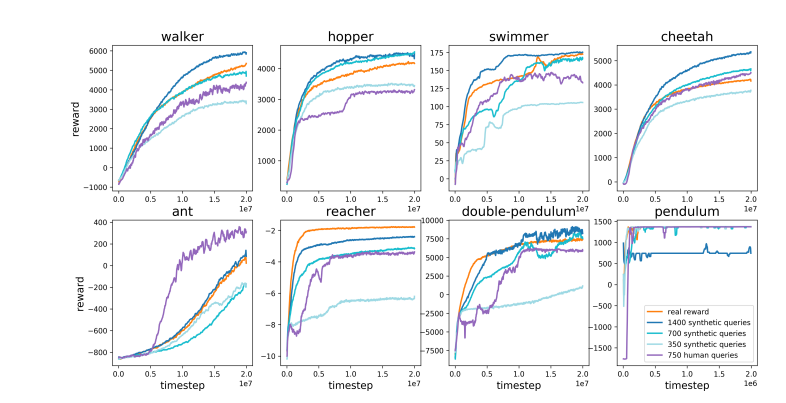
Sebaliknya, Karpathy berpendapat bahwa RLHF lebih cenderung meniru preferensi manusia daripada menyelesaikan masalah. Dia membayangkan jika AlphaGo mengadopsi metode RLHF, evaluator manusia perlu membandingkan sejumlah besar status permainan dan memilih preferensi. Proses ini mungkin memerlukan hingga 100.000 perbandingan untuk melatih model penghargaan yang meniru pemeriksaan atmosfer manusia. Namun, penilaian berdasarkan atmosfer seperti itu dapat memberikan hasil yang menyesatkan dalam permainan ketat seperti Go.
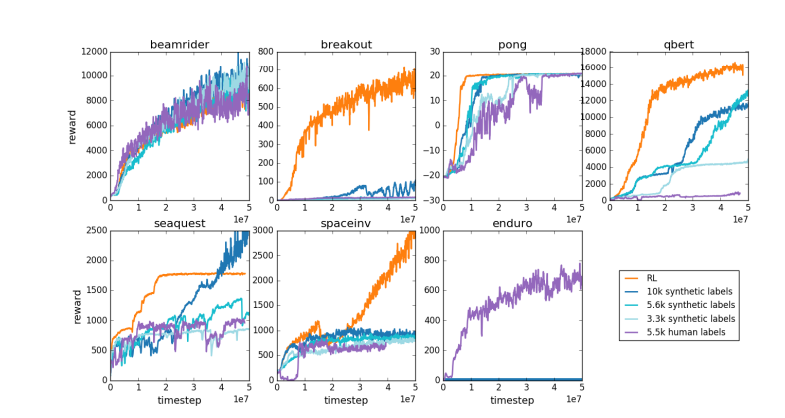
Untuk alasan yang sama, model penghargaan LLM saat ini bekerja dengan cara yang sama—model ini cenderung memberikan peringkat jawaban yang tinggi yang secara statistik tampaknya lebih disukai oleh penilai manusia. Ini lebih merupakan agen yang melayani preferensi manusia yang dangkal daripada cerminan kemampuan pemecahan masalah yang sebenarnya. Yang lebih mengkhawatirkan lagi, model mungkin dengan cepat belajar bagaimana memanfaatkan fungsi penghargaan ini dibandingkan benar-benar meningkatkan kemampuannya.
Karpathy menunjukkan bahwa meskipun pembelajaran penguatan bekerja dengan baik di lingkungan tertutup seperti Go, pembelajaran penguatan yang sebenarnya masih sulit dipahami untuk tugas-tugas bahasa terbuka. Hal ini terutama karena sulitnya menentukan tujuan yang jelas dan mekanisme penghargaan dalam tugas terbuka. Bagaimana cara memberikan imbalan obyektif untuk tugas-tugas seperti merangkum artikel, menjawab pertanyaan samar tentang instalasi pip, menceritakan lelucon, atau menulis ulang kode Java ke Python? Karpathy menanyakan pertanyaan mendalam ini, dan menuju ke arah ini bukanlah sebuah prinsip. namun hal ini juga tidak mudah dan membutuhkan pemikiran kreatif.

Namun, Karpathy percaya bahwa jika masalah sulit ini dapat diselesaikan, model bahasa mempunyai potensi untuk benar-benar menyamai atau bahkan melampaui kemampuan pemecahan masalah manusia. Pandangan ini sejalan dengan makalah terbaru yang diterbitkan oleh Google DeepMind, yang menunjukkan bahwa keterbukaan adalah dasar dari kecerdasan umum buatan (AGI).
Sebagai salah satu dari beberapa pakar AI senior yang meninggalkan OpenAI tahun ini, Karpathy saat ini sedang mengerjakan startup AI pendidikan miliknya sendiri. Ucapannya tentu saja memberikan dimensi pemikiran baru ke dalam bidang penelitian AI dan memberikan wawasan berharga tentang arah pengembangan AI di masa depan.
Pandangan Karpathy memicu diskusi luas di industri. Para pendukung percaya bahwa ia mengungkapkan isu utama dalam penelitian AI saat ini, yaitu bagaimana membuat AI benar-benar mampu memecahkan masalah yang kompleks, bukan hanya meniru perilaku manusia. Para penentang khawatir bahwa pengabaian RLHF secara dini dapat menyebabkan penyimpangan dalam arah pengembangan AI.
Alamat makalah: https://arxiv.org/pdf/1706.03741
Pandangan Karpathy memicu diskusi mendalam tentang arah pengembangan AI di masa depan. Keraguannya terhadap RLHF mendorong para peneliti untuk mengkaji ulang metode pelatihan AI saat ini dan mengeksplorasi jalur yang lebih efektif, dengan tujuan akhir untuk mencapai kecerdasan buatan yang sebenarnya.