Kemajuan model bahasa besar (LLM) sangat mengesankan, namun model tersebut menunjukkan kekurangan yang tidak terduga pada beberapa masalah sederhana. Andrej Karpathy dengan tajam mencontohkan fenomena “kecerdasan bergerigi”, yaitu LLM mampu melakukan tugas-tugas kompleks, namun sering melakukan kesalahan pada masalah-masalah sederhana. Hal ini telah memicu pemikiran mendalam tentang kelemahan penting LLM dan arah perbaikan di masa depan. Artikel ini akan menjelaskan hal ini secara rinci dan mengeksplorasi cara memanfaatkan LLM dengan lebih baik dan menghindari keterbatasannya.
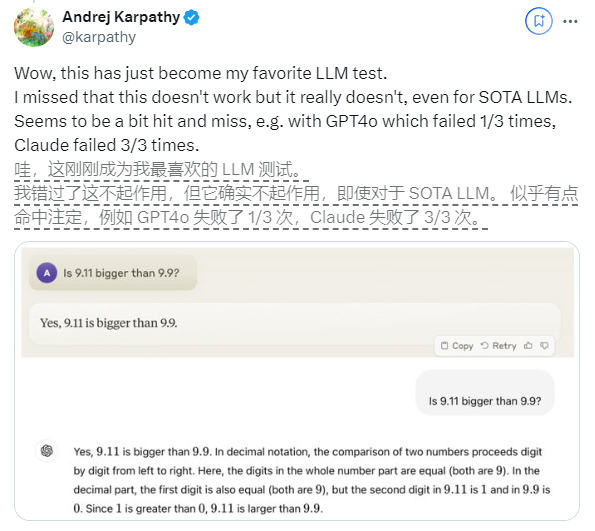
Baru-baru ini, pertanyaan sederhana "Apakah 9.11 lebih besar dari 9.9?" telah menarik perhatian luas di seluruh dunia. Hampir semua model bahasa besar (LLM) telah melakukan kesalahan dalam masalah ini. Fenomena ini menarik perhatian Andrej Karpathy, pakar di bidang AI. Berangkat dari isu tersebut, ia membahas secara mendalam kelemahan-kelemahan penting dan arah perbaikan di masa depan dari teknologi model besar saat ini.
Karpathy menyebut fenomena ini "kecerdasan bergerigi" atau "kecerdasan bergerigi", menunjukkan bahwa meskipun LLM yang canggih dapat melakukan berbagai tugas kompleks, seperti memecahkan masalah matematika yang sulit, mereka gagal dalam beberapa tugas yang tampaknya sederhana kinerjanya buruk dalam menyelesaikan masalah, dan ketidakseimbangan kecerdasan ini mirip dengan bentuk gigi gergaji.
Misalnya, peneliti OpenAI Noam Brown menemukan bahwa LLM berkinerja buruk dalam permainan Tic-Tac-Toe, karena model tersebut tidak dapat membuat keputusan yang tepat bahkan ketika pengguna akan menang. Karpathy yakin hal ini terjadi karena model tersebut membuat keputusan yang "tidak dapat dibenarkan", sementara Noam yakin hal ini mungkin disebabkan oleh kurangnya diskusi yang relevan mengenai strategi dalam data pelatihan.
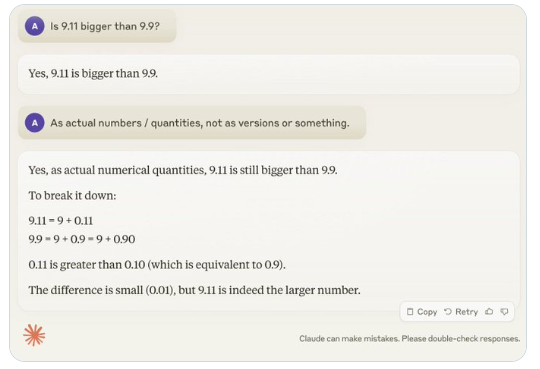
Contoh lainnya adalah kesalahan yang dilakukan LLM saat menghitung besaran alfanumerik. Bahkan rilis terbaru Llama 3.1 memberikan jawaban yang salah atas pertanyaan sederhana. Karpathy menjelaskan, hal ini bermula dari kurangnya “pengetahuan diri” LLM, yaitu model tidak bisa membedakan apa yang bisa dan tidak bisa dilakukan, sehingga model menjadi “percaya diri” dalam menghadapi tugas.
Untuk mengatasi masalah ini, Karpathy menyebutkan solusi yang diusulkan dalam makalah Llama3.1 yang diterbitkan oleh Meta. Makalah ini merekomendasikan pencapaian penyelarasan model pada tahap pasca-pelatihan sehingga model mengembangkan kesadaran diri dan mengetahui apa yang diketahuinya. Masalah ilusi tidak dapat dihilangkan hanya dengan menambahkan pengetahuan faktual. Tim Llama mengusulkan metode pelatihan yang disebut "deteksi pengetahuan", yang mendorong model untuk hanya menjawab pertanyaan yang dipahaminya dan menolak memberikan jawaban yang tidak pasti.
Karpathy percaya bahwa meskipun ada berbagai masalah dengan kemampuan AI saat ini, hal ini bukan merupakan kelemahan mendasar dan ada solusi yang dapat dilakukan. Dia mengusulkan bahwa ide pelatihan AI saat ini hanya untuk “meniru label manusia dan memperluas skalanya.” Untuk terus meningkatkan kecerdasan AI, lebih banyak pekerjaan yang perlu dilakukan di seluruh tahap pengembangan.
Sampai masalah terselesaikan sepenuhnya, jika LLM akan digunakan dalam produksi, LLM harus dibatasi pada tugas-tugas yang mereka kuasai, waspada terhadap "tepi bergerigi", dan tetap melibatkan manusia setiap saat. Dengan cara ini, kita dapat memanfaatkan potensi AI dengan lebih baik sambil menghindari risiko yang disebabkan oleh keterbatasannya.
Secara keseluruhan, “kecerdasan bergerigi” LLM merupakan tantangan yang saat ini dihadapi di bidang AI, namun hal ini bukannya tidak dapat diatasi. Dengan meningkatkan metode pelatihan, meningkatkan kesadaran diri model, dan menerapkannya secara hati-hati pada skenario aktual, kita dapat memanfaatkan keunggulan LLM dengan lebih baik dan mendorong pengembangan berkelanjutan teknologi kecerdasan buatan.