Pesatnya perkembangan model bahasa besar (LLM) telah menghadirkan kemampuan pemrosesan bahasa alami yang luar biasa, namun kebutuhan komputasi dan penyimpanannya yang besar membatasi popularitasnya. Menjalankan model dengan 176 miliar parameter memerlukan ratusan gigabyte ruang penyimpanan dan beberapa GPU kelas atas, sehingga mahal dan sulit untuk diukur. Untuk mengatasi masalah ini, para peneliti berfokus pada teknik kompresi model, seperti kuantisasi, untuk mengurangi ukuran model dan persyaratan pengoperasian, namun mereka juga menghadapi risiko hilangnya akurasi.
Kecerdasan buatan (AI) semakin pintar, terutama model bahasa besar (LLM), yang luar biasa dalam memproses bahasa alami. Namun tahukah Anda? Di balik otak AI yang cerdas ini, diperlukan daya komputasi dan ruang penyimpanan yang besar untuk mendukungnya.
Model multi-bahasa Bloom dengan 176 miliar parameter memerlukan setidaknya 350 GB ruang hanya untuk menyimpan bobot model, dan juga memerlukan beberapa GPU canggih untuk dijalankan. Hal ini tidak hanya mahal tetapi juga sulit untuk dipopulerkan.
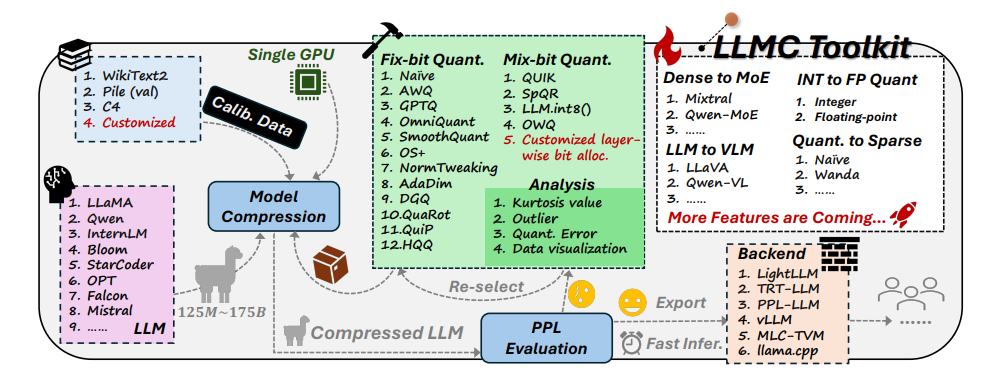
Untuk mengatasi masalah ini, peneliti telah mengusulkan teknik yang disebut “kuantifikasi”. Kuantifikasi seperti “memperkecil” otak AI. Dengan memetakan bobot dan aktivasi model ke format data digit lebih rendah, tidak hanya mengurangi ukuran model, tetapi juga mempercepat kecepatan lari model. Namun proses ini juga memiliki risiko, dan beberapa keakuratan mungkin hilang.
Menghadapi tantangan ini, para peneliti dari Universitas Beihang dan SenseTime Technology bersama-sama mengembangkan perangkat LLMC. LLMC seperti pelatih penurunan berat badan pribadi untuk AI. Ini dapat membantu peneliti dan pengembang menemukan rencana penurunan berat badan yang paling sesuai, yang dapat membuat model AI lebih ringan tanpa mempengaruhi tingkat kecerdasannya.
Toolkit LLMC memiliki tiga fitur utama:
Diversifikasi: LLMC menyediakan 16 metode kuantitatif berbeda, seperti menyiapkan 16 resep penurunan berat badan berbeda untuk AI. Baik AI Anda ingin menurunkan berat badan secara menyeluruh atau lokal, LLMC dapat memenuhi kebutuhan Anda.
Biaya rendah: LLMC sangat menghemat sumber daya dan hanya memerlukan sedikit dukungan perangkat keras bahkan untuk memproses model yang sangat besar. Misalnya, hanya dengan menggunakan GPU A100 40GB, model OPT-175B dengan 175 miliar parameter dapat disesuaikan dan dievaluasi. Ini sama efisiennya dengan menggunakan treadmill di rumah untuk melatih juara Olimpiade!
Kompatibilitas tinggi: LLMC mendukung berbagai pengaturan kuantisasi dan format model, dan juga kompatibel dengan berbagai backend dan platform perangkat keras. Ini seperti pelatih universal yang dapat membantu Anda mengembangkan rencana pelatihan yang sesuai, apa pun peralatan yang Anda gunakan.
Aplikasi praktis LLMC: menjadikan AI lebih cerdas dan hemat energi
Munculnya toolkit LLMC memberikan tes benchmark yang komprehensif dan adil untuk kuantifikasi model bahasa besar. Ini mempertimbangkan tiga faktor utama: data pelatihan, algoritme, dan format data untuk membantu pengguna menemukan solusi pengoptimalan kinerja terbaik.
Dalam aplikasi praktis, LLMC dapat membantu peneliti dan pengembang mengintegrasikan algoritma yang sesuai dan format bit rendah secara lebih efisien, mendorong mempopulerkan kompresi model bahasa besar. Artinya, kita mungkin melihat aplikasi AI yang lebih ringan namun sama kuatnya di masa depan.
Penulis makalah ini juga membagikan beberapa temuan dan saran menarik:
Saat memilih data pelatihan, Anda harus memilih kumpulan data yang lebih mirip dengan data pengujian dalam hal distribusi kosa kata, seperti halnya ketika manusia menurunkan berat badan, mereka perlu memilih resep yang sesuai berdasarkan keadaannya sendiri.
Dalam hal algoritme kuantifikasi, mereka mengeksplorasi dampak dari tiga teknik utama transformasi, cropping, dan rekonstruksi, seperti membandingkan efek berbagai metode olahraga terhadap penurunan berat badan.
Saat memilih antara kuantisasi integer dan floating-point, mereka menemukan bahwa kuantisasi floating-point memiliki lebih banyak keuntungan dalam menangani situasi kompleks, sedangkan kuantisasi integer mungkin lebih baik dalam beberapa kasus khusus. Sepertinya intensitas latihan yang berbeda diperlukan pada berbagai tahap penurunan berat badan.
Munculnya toolkit LLMC telah membawa tren baru di bidang AI. Ini tidak hanya memberikan asisten yang kuat bagi para peneliti dan pengembang, tetapi juga menunjukkan arah pengembangan AI di masa depan. Melalui LLMC, kita dapat melihat aplikasi AI yang lebih ringan dan berkinerja tinggi, sehingga memungkinkan AI untuk benar-benar memasuki kehidupan kita sehari-hari.
Alamat proyek: https://github.com/ModelTC/llmc
Alamat makalah: https://arxiv.org/pdf/2405.06001
Secara keseluruhan, toolkit LLMC memberikan solusi efektif untuk memecahkan masalah konsumsi sumber daya model bahasa besar. Ini tidak hanya mengurangi biaya dan ambang batas pengoperasian model, tetapi juga meningkatkan efisiensi dan kegunaan model, menyuntikkan suntikan ke dalam model. mempopulerkan dan mengembangkan vitalitas baru. Di masa depan, kita dapat menantikan munculnya aplikasi AI yang lebih ringan berdasarkan LLMC, yang memberikan lebih banyak kenyamanan dalam hidup kita.