Model bahasa Zamba2-2.7B Zyphra yang baru dirilis membuat gebrakan di bidang model bahasa kecil. Model ini secara signifikan mengurangi kebutuhan sumber daya inferensi sekaligus mempertahankan performa yang sebanding dengan model 7B, sehingga ideal untuk aplikasi perangkat seluler. Zamba2-2.7B telah meningkatkan kecepatan respons, penggunaan memori, dan latensi secara signifikan, yang sangat penting untuk aplikasi yang memerlukan interaksi real-time, seperti asisten virtual dan chatbots. Mekanisme perhatian bersama interleaved yang ditingkatkan dan proyektor LoRA memastikan pemrosesan tugas-tugas kompleks yang efisien.
Baru-baru ini, Zyphra merilis model bahasa Zamba2-2.7B yang baru. Rilis ini sangat penting dalam sejarah pengembangan model bahasa kecil. Model baru ini mencapai peningkatan signifikan dalam kinerja dan efisiensi, dengan kumpulan data pelatihannya mencapai sekitar 3 triliun token, sehingga kinerjanya sebanding dengan Zamba1-7B dan model 7B terkemuka lainnya.
Hal yang paling mengejutkan adalah kebutuhan sumber daya Zamba2-2.7B selama inferensi berkurang secara signifikan, menjadikannya solusi efisien untuk aplikasi perangkat seluler.
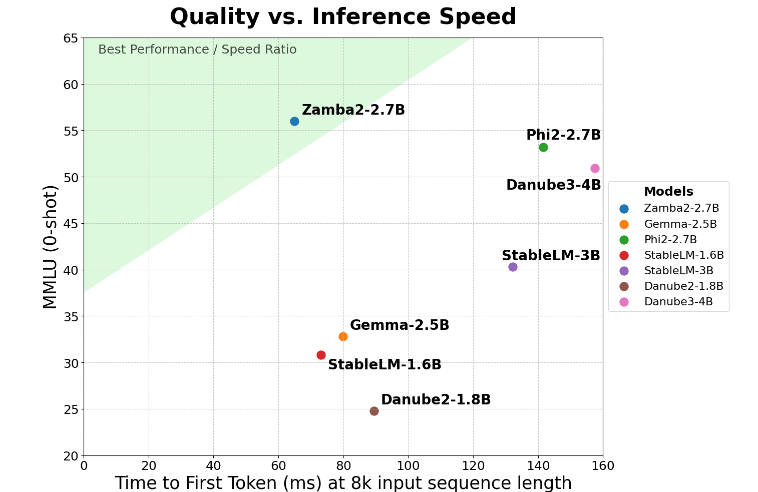
Zamba2-2.7B mencapai peningkatan dua kali lipat dalam metrik utama “waktu respons generasi pertama”, yang berarti Zamba2-2.7B dapat menghasilkan respons awal lebih cepat dibandingkan kompetitor. Hal ini penting untuk aplikasi seperti asisten virtual dan chatbot yang memerlukan interaksi real-time.
Selain peningkatan kecepatan, Zamba2-2.7B juga melakukan pekerjaan yang sangat baik dalam penggunaan memori. Ini mengurangi overhead memori sebesar 27%, sehingga ideal untuk diterapkan pada perangkat dengan sumber daya memori terbatas. Manajemen memori cerdas tersebut memastikan bahwa model dapat berjalan secara efektif di lingkungan dengan sumber daya komputasi terbatas, sehingga memperluas cakupan aplikasinya di berbagai perangkat dan platform.
Zamba2-2.7B juga memiliki keunggulan signifikan yaitu latensi build yang lebih rendah. Dibandingkan dengan Phi3-3.8B, latensinya berkurang 1,29 kali lipat, sehingga interaksi menjadi lebih lancar. Latensi rendah sangat penting dalam aplikasi yang memerlukan komunikasi berkelanjutan dan lancar, seperti bot layanan pelanggan dan alat pendidikan interaktif. Oleh karena itu, Zamba2-2.7B tidak diragukan lagi menjadi pilihan pertama bagi pengembang dalam hal meningkatkan pengalaman pengguna.
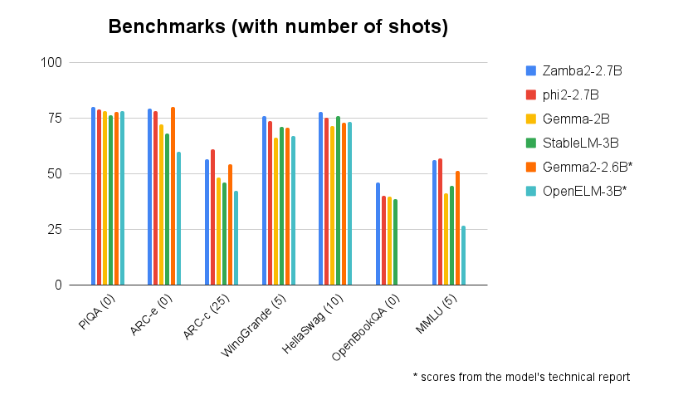
Zamba2-2.7B secara konsisten mengungguli kinerjanya dalam perbandingan benchmark dengan model berukuran serupa lainnya. Performanya yang unggul membuktikan inovasi dan upaya Zyphra dalam mendorong perkembangan teknologi kecerdasan buatan. Model ini menggunakan mekanisme perhatian bersama interleaved yang ditingkatkan dan dilengkapi dengan proyektor LoRA pada modul MLP bersama untuk memastikan keluaran kinerja tinggi saat memproses tugas yang kompleks.
Pintu masuk model: https://huggingface.co/Zyphra/Zamba2-2.7B
Highlight:
Model Zamba2-27B menggandakan waktu respons pertama, sehingga cocok untuk aplikasi interaktif waktu nyata.
? Model ini mengurangi overhead memori sebesar 27% dan cocok untuk perangkat dengan sumber daya terbatas.
Dalam hal penundaan pembangkitan, Zamba2-2.7B mengungguli model serupa, sehingga meningkatkan pengalaman pengguna.
Singkatnya, Zamba2-2.7B telah menetapkan tolok ukur baru untuk model bahasa kecil dengan kinerja dan efisiensi luar biasa, menyediakan alat AI yang lebih kuat dan fleksibel bagi pengembang, dan diharapkan memainkan peran penting dalam aplikasi seluler. Pemanfaatan sumber dayanya yang efisien dan pengalaman pengguna yang lancar menjadikannya kekuatan pendorong utama bagi pengembangan aplikasi AI di masa depan.