Pengalaman Meta dalam melatih model bahasa skala besar Llama 3.1 telah menunjukkan kepada kita tantangan dan peluang yang belum pernah terjadi sebelumnya dalam pengembangan AI. Cluster besar yang terdiri dari 16.384 GPU mengalami kegagalan rata-rata setiap 3 jam selama periode pelatihan 54 hari. Hal ini tidak hanya menyoroti pertumbuhan pesat skala model AI, tetapi juga mengungkap hambatan besar dalam stabilitas superkomputer. sistem. Artikel ini akan menyelidiki tantangan yang dihadapi Meta selama proses pelatihan Llama 3.1, strategi yang mereka terapkan untuk menghadapi tantangan ini, dan menganalisis implikasinya terhadap industri AI secara keseluruhan.
Dalam dunia kecerdasan buatan, setiap terobosan disertai dengan data yang mencengangkan. Bayangkan 16.384 GPU berjalan pada saat yang bersamaan. Ini bukanlah adegan dalam film fiksi ilmiah, melainkan gambaran nyata Meta saat melatih model Llama3.1 terbaru. Namun di balik pesta teknologi ini terdapat kegagalan yang rata-rata terjadi setiap 3 jam. Angka yang mencengangkan ini tidak hanya menunjukkan kecepatan perkembangan AI, namun juga mengungkap tantangan besar yang dihadapi oleh teknologi saat ini.
Dari 2.028 GPU yang digunakan di Llama1 hingga 16.384 GPU yang digunakan di Llama3.1, pertumbuhan pesat ini tidak hanya merupakan perubahan kuantitas, namun juga merupakan tantangan ekstrem terhadap stabilitas sistem superkomputer yang ada. Data penelitian Meta menunjukkan bahwa selama siklus pelatihan 54 hari Llama3.1, terjadi total 419 kegagalan komponen yang tidak terduga, sekitar setengahnya terkait dengan GPU H100 dan memori HBM3-nya. Data ini membuat kita harus berpikir: sembari mengejar terobosan dalam performa AI, apakah keandalan sistem juga meningkat secara bersamaan?
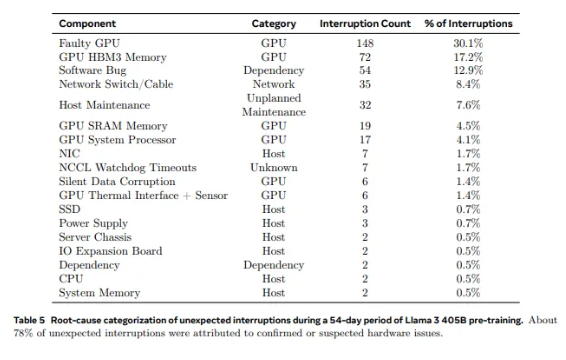
Faktanya, ada fakta yang tak terbantahkan di bidang superkomputer: semakin besar skalanya, semakin sulit menghindari kegagalan. Cluster pelatihan Llama 3.1 Meta terdiri dari puluhan ribu prosesor, ratusan ribu chip lainnya, dan ratusan mil kabel, tingkat kompleksitas yang sebanding dengan jaringan saraf kota kecil. Dalam raksasa seperti itu, kegagalan fungsi tampaknya merupakan kejadian biasa.
Menghadapi kegagalan yang sering terjadi, tim Meta pun tak berdaya. Mereka mengadopsi serangkaian strategi penanggulangan: mengurangi waktu mulai pekerjaan dan pos pemeriksaan, mengembangkan alat diagnostik eksklusif, memanfaatkan perekam penerbangan NCCL PyTorch, dll. Langkah-langkah ini tidak hanya meningkatkan toleransi kesalahan sistem, namun juga meningkatkan kemampuan pemrosesan otomatis. Insinyur Meta seperti petugas pemadam kebakaran modern, siap memadamkan api apa pun yang mungkin mengganggu proses pelatihan.
Namun tantangannya tidak hanya datang dari perangkat kerasnya saja. Faktor lingkungan dan fluktuasi konsumsi daya juga membawa tantangan tak terduga bagi klaster superkomputer. Tim Meta menemukan bahwa perubahan suhu siang dan malam serta fluktuasi drastis konsumsi daya GPU akan berdampak signifikan pada performa pelatihan. Penemuan ini mengingatkan kita bahwa dalam melakukan terobosan teknologi, kita tidak bisa mengabaikan pentingnya pengelolaan lingkungan dan konsumsi energi.
Proses pelatihan Llama3.1 dapat disebut sebagai ujian akhir terhadap stabilitas dan keandalan sistem superkomputer. Strategi yang diadopsi oleh tim Meta untuk menghadapi tantangan dan alat otomatis yang dikembangkan memberikan pengalaman dan inspirasi berharga bagi seluruh industri AI. Meskipun terdapat kesulitan, kami mempunyai alasan untuk percaya bahwa dengan kemajuan teknologi yang berkelanjutan, sistem superkomputer di masa depan akan lebih kuat dan stabil.
Di era pesatnya perkembangan teknologi AI ini, upaya Meta tidak diragukan lagi merupakan petualangan yang berani. Laporan ini tidak hanya mendorong batasan performa model AI, namun juga menunjukkan kepada kita tantangan nyata yang kita hadapi dalam mencapai batasan tersebut. Mari kita menantikan kemungkinan tak terbatas yang dibawa oleh teknologi AI, dan pada saat yang sama memuji para insinyur yang bekerja tanpa kenal lelah di garis depan teknologi. Setiap upaya, setiap kegagalan, dan setiap terobosan yang mereka lakukan membuka jalan bagi kemajuan teknologi manusia.
Referensi:
https://www.tomshardware.com/tech-industry/artificial-intelligence/faulty-nvidia-h100-gpus-and-hbm3-memory-caused-half-of-the-failures-during-llama-3-training- satu-kegagalan-setiap-tiga-jam-untuk-metas-16384-gpu-training-cluster
Kasus pelatihan Llama 3.1 telah memberi kita pelajaran berharga dan menunjukkan arah pengembangan sistem superkomputer di masa depan: dalam mengejar kinerja, kita harus mementingkan stabilitas dan keandalan sistem, dan secara aktif mengeksplorasi strategi untuk menghadapi berbagai kegagalan. Hanya dengan cara ini kita dapat memastikan perkembangan teknologi AI yang berkelanjutan dan stabil serta memberikan manfaat bagi umat manusia.