NVIDIA baru-baru ini merilis seri model bahasa kecil Minitron, termasuk versi 4B dan 8B. Langkah ini bertujuan untuk mengurangi biaya pelatihan dan penerapan model bahasa besar dan memungkinkan lebih banyak pengembang menggunakan teknologi canggih ini dengan mudah. Melalui teknologi "pemangkasan" dan "penyulingan pengetahuan", model Minitron secara signifikan mengurangi ukuran model sambil mempertahankan kinerja yang sebanding dengan model besar, dan bahkan melampaui model terkenal lainnya dalam beberapa indikator. Hal ini sangat penting untuk mendorong mempopulerkan teknologi kecerdasan buatan.
Baru-baru ini, NVIDIA telah membuat langkah baru di bidang kecerdasan buatan. Mereka telah meluncurkan seri model bahasa kecil Minitron, termasuk versi 4B dan 8B. Model ini tidak hanya meningkatkan kecepatan pelatihan hingga 40 kali lipat, tetapi juga memudahkan pengembang menggunakannya untuk berbagai aplikasi, seperti terjemahan, analisis sentimen, dan AI percakapan.
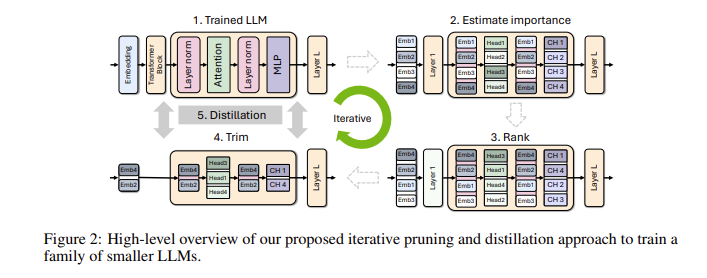
Anda mungkin bertanya, mengapa model bahasa kecil begitu penting? Faktanya, meskipun model bahasa besar tradisional memiliki kinerja yang kuat, biaya pelatihan dan penerapannya sangat tinggi, dan seringkali memerlukan sumber daya komputasi dan data dalam jumlah besar. Untuk membuat teknologi canggih ini terjangkau oleh lebih banyak orang, tim peneliti NVIDIA menemukan cara yang brilian: menggabungkan dua teknologi: "pemangkasan" dan "penyulingan pengetahuan" untuk mengurangi ukuran model secara efisien.
Secara khusus, peneliti pertama-tama akan memulai dari model besar yang sudah ada dan memangkasnya. Mereka mengevaluasi pentingnya setiap neuron, lapisan, atau kepala perhatian dalam model dan membuang yang kurang penting. Dengan cara ini, model menjadi jauh lebih kecil, dan sumber daya serta waktu yang dibutuhkan untuk pelatihan juga berkurang secara signifikan. Selanjutnya, mereka juga akan menggunakan kumpulan data skala kecil untuk melakukan pelatihan penyulingan pengetahuan pada model yang dipangkas guna memulihkan keakuratan model. Anehnya, proses ini tidak hanya menghemat uang, tetapi juga meningkatkan kinerja model!
Dalam pengujian sebenarnya, tim peneliti NVIDIA mencapai hasil yang baik pada keluarga model Nemotron-4. Mereka berhasil mengurangi ukuran model sebanyak 2 hingga 4 kali lipat dengan tetap mempertahankan performa serupa. Yang lebih menarik lagi adalah model 8B mengungguli model terkenal lainnya seperti Mistral7B dan LLaMa-38B dalam berbagai indikator, dan memerlukan data pelatihan 40 kali lebih sedikit selama proses pelatihan, sehingga menghemat biaya komputasi 1,8 kali lipat. Bayangkan apa artinya ini? Semakin banyak pengembang yang dapat merasakan kemampuan AI yang kuat dengan sumber daya dan biaya yang lebih sedikit!
NVIDIA menjadikan model Minitron yang dioptimalkan ini sebagai sumber terbuka di Huggingface agar semua orang dapat menggunakannya secara bebas.
Pintu masuk demo: https://huggingface.co/collections/nvidia/minitron-669ac727dc9c86e6ab7f0f3e
Highlight:
** Peningkatan kecepatan pelatihan **: Kecepatan pelatihan model Minitron 40 kali lebih cepat dibandingkan model tradisional, memungkinkan pengembang menghemat waktu dan tenaga.
**Penghematan Biaya**: Melalui teknologi pemangkasan dan penyulingan pengetahuan, sumber daya komputasi dan volume data yang diperlukan untuk pelatihan berkurang secara signifikan.
? **Berbagi sumber terbuka**: Model Minitron telah menjadi sumber terbuka di Huggingface, sehingga lebih banyak orang dapat mengakses dan menggunakannya dengan mudah, sehingga mendorong mempopulerkan teknologi AI.
Model Minitron yang bersifat open source menandai terobosan penting dalam penerapan praktis model bahasa kecil. Hal ini juga menunjukkan bahwa teknologi kecerdasan buatan akan menjadi lebih populer dan lebih mudah digunakan, memberdayakan lebih banyak pengembang dan skenario aplikasi. Di masa depan, kita dapat mengharapkan lebih banyak inovasi serupa untuk mendorong pengembangan berkelanjutan dari teknologi kecerdasan buatan.