Model ChatQA2 terbaru yang dirilis oleh Nvidia AI telah mencapai terobosan signifikan di bidang pemahaman konteks teks panjang dan generasi yang ditingkatkan pengambilan (RAG). Hal ini didasarkan pada model Llama3 yang kuat, yang secara signifikan meningkatkan kemampuan mengikuti instruksi, kinerja RAG dan kemampuan pemahaman teks yang panjang dengan memperluas jendela konteks ke 128 ribu token dan mengadopsi penyempurnaan instruksi tiga tahap. ChatQA2 mampu mempertahankan koherensi kontekstual dan daya ingat yang tinggi saat memproses data teks berukuran besar, dan telah menunjukkan kinerja yang sebanding dengan GPT-4-Turbo dalam beberapa pengujian benchmark, dan bahkan melampauinya dalam beberapa aspek. Hal ini menandai kemajuan signifikan dalam kemampuan model bahasa besar untuk menangani teks yang panjang.
Terobosan kinerja: ChatQA2 secara signifikan meningkatkan kemampuan mengikuti instruksi, kinerja RAG, dan pemahaman teks panjang dengan memperluas jendela konteks hingga 128 ribu token dan mengadopsi proses penyesuaian instruksi tiga tahap. Terobosan teknologi ini memungkinkan model untuk mempertahankan koherensi kontekstual dan daya ingat yang tinggi ketika memproses kumpulan data hingga 1 miliar token.
Detail teknis: ChatQA2 dikembangkan menggunakan solusi teknis yang terperinci dan dapat direproduksi. Model ini pertama-tama memperluas jendela konteks Llama3-70B dari 8K menjadi 128K token melalui pra-pelatihan berkelanjutan. Selanjutnya, proses penyetelan instruksi tiga tahap diterapkan untuk memastikan bahwa model dapat menangani berbagai tugas secara efektif.
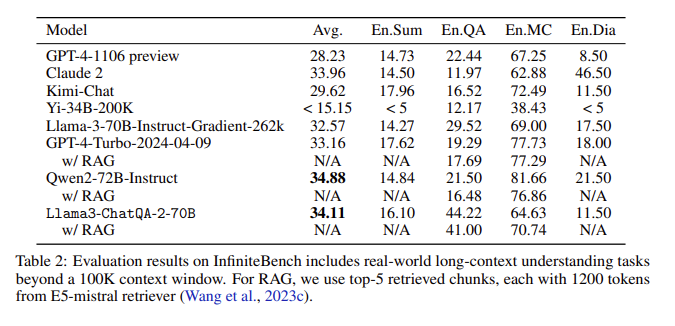
Hasil evaluasi: Dalam evaluasi InfiniteBench, ChatQA2 mencapai akurasi yang sebanding dengan GPT-4-Turbo-2024-0409 pada tugas-tugas seperti ringkasan teks panjang, tanya jawab, pilihan ganda, dan dialog, dan melampauinya pada benchmark RAG. Pencapaian ini menyoroti kemampuan komprehensif ChatQA2 dalam berbagai konteks dan fitur.
Mengatasi masalah utama: ChatQA2 menargetkan masalah utama dalam proses RAG, seperti fragmentasi konteks dan rendahnya daya ingat, dengan menggunakan pengambilan teks panjang yang canggih untuk meningkatkan akurasi dan efisiensi pengambilan.
Dengan memperluas jendela konteks dan menerapkan proses penyetelan instruksi tiga tahap, ChatQA2 mencapai pemahaman teks yang panjang dan performa RAG yang sebanding dengan GPT-4-Turbo. Model ini memberikan solusi fleksibel untuk berbagai tugas hilir, menyeimbangkan akurasi dan efisiensi melalui teks panjang yang canggih dan teknik pengambilan yang ditingkatkan.
Pintu masuk makalah: https://arxiv.org/abs/2407.14482
Kemunculan ChatQA2 membawa kemungkinan baru untuk pemrosesan teks panjang dan aplikasi RAG. Efisiensi dan akurasinya memberikan nilai referensi penting untuk pengembangan kecerdasan buatan di masa depan. Penelitian terbuka pada model ini juga mendorong kolaborasi antara akademisi dan industri, sehingga mendorong kemajuan berkelanjutan di bidang ini. Nantikan untuk melihat lebih banyak aplikasi inovatif berdasarkan model ini di masa depan.