Persaingan di bidang kecerdasan buatan sangat ketat, dan munculnya model open source menantang dominasi raksasa teknologi. Baru-baru ini, startup perangkat keras kecerdasan buatan Groq merilis dua model bahasa sumber terbuka-Llama-3-Groq-70B-Tool-Use dan Llama3Groq Tool Use 8B, dan mencapai hasil yang mengesankan pada Berkeley Function Call Ranking (BFCL) Diantaranya, parameter 70B versi melampaui model kepemilikan OpenAI, Google, Anthropic, dan perusahaan lain. Keberhasilan model ini tidak hanya terletak pada kinerjanya yang kuat, namun juga pada penggunaan data sintetis yang dihasilkan secara etis selama proses pelatihan, yang secara efektif memecahkan masalah seperti privasi data dan overfitting, serta memberikan peluang baru untuk pengembangan berkelanjutan di lapangan. contoh kecerdasan buatan.
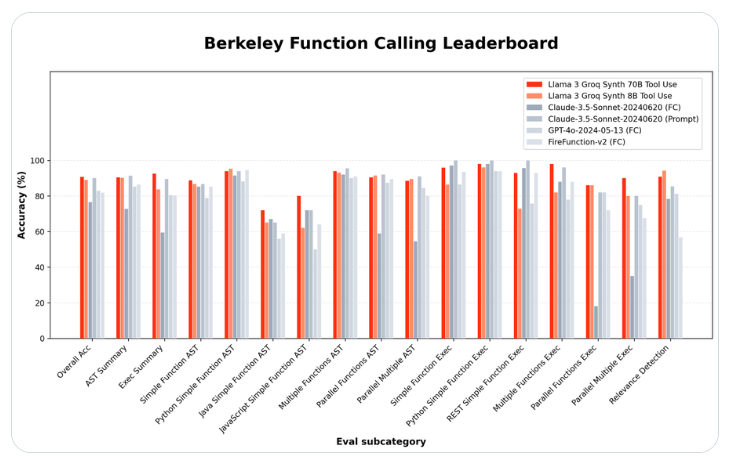
Startup perangkat keras kecerdasan buatan, Groq, telah merilis dua model bahasa sumber terbuka yang mengungguli raksasa teknologi dalam kemampuan mereka menggunakan alat khusus. Model Llama-3-Groq-70B-Tool-Use yang baru telah menduduki posisi teratas di Berkeley Function Call Ranking (BFCL), melampaui produk berpemilik seperti OpenAI, Google, dan Anthropic.
Pemimpin proyek Groq Rick Lamers mengumumkan terobosan ini dalam artikel X.com. Dia berkata: “Saya dengan bangga mengumumkan Alat Llama3Groq Gunakan model 8B dan 70B. Ini adalah versi alat sumber terbuka Llama3 yang telah disempurnakan dan telah mencapai posisi #1 di BFCL, mengalahkan semua model lainnya termasuk model berpemilik. Seperti Claude Sonnet3.5, GPT-4Turbo, GPT-4o dan Gemini1.5Pro.”
Data sintetis dan AI etis: paradigma baru dalam pelatihan model
Versi parameter 70B yang lebih besar mencapai akurasi keseluruhan sebesar 90,76% pada BFCL, sedangkan model 8B yang lebih kecil memperoleh skor 89,06%, dan menempati peringkat ketiga secara keseluruhan. Hasil ini menunjukkan bahwa model sumber terbuka dapat menyamai atau bahkan melampaui kinerja alternatif sumber tertutup pada tugas tertentu.
Groq mengembangkan model tersebut dalam kemitraan dengan perusahaan riset kecerdasan buatan Glaive, menggunakan penyesuaian penuh dan pengoptimalan preferensi langsung (DPO) pada model dasar Llama-3 Meta. Tim menekankan bahwa mereka hanya menggunakan data sintetis yang dihasilkan secara etis untuk pelatihan, mengatasi kekhawatiran umum tentang privasi data dan overfitting.
Model-model ini sekarang tersedia melalui Groq API dan platform Hugging Face. Aksesibilitas ini dapat mempercepat inovasi di bidang yang memerlukan penggunaan alat dan pemanggilan fungsi yang kompleks, seperti pengkodean otomatis, analisis data, dan asisten AI interaktif.
Groq juga telah meluncurkan demo publik tentang Hugging Face Spaces, yang memungkinkan pengguna berinteraksi dengan model dan menguji kemampuan perkakasnya secara langsung. Seperti Gradio, yang diperoleh Hugging Face pada Desember 2021, banyak demo di Hugging Face Spaces dibuat dengan cara ini. Komunitas AI merespons dengan antusias, dengan banyak peneliti dan pengembang yang bersemangat mengeksplorasi kemampuan model ini.
Highlight:
⭐ Model AI sumber terbuka yang dirilis oleh Groq mengungguli model milik raksasa teknologi dalam tugas tertentu
⭐ Dengan menggunakan data sintetis untuk pelatihan, Groq menantang masalah privasi data umum dan penyesuaian berlebihan dalam pengembangan model AI
⭐ Peluncuran model sumber terbuka dapat mengubah jalur pengembangan bidang AI dan mendorong aksesibilitas AI yang lebih luas serta pengembangan ekosistem inovatif
Keberhasilan model sumber terbuka Groq telah memberikan vitalitas baru ke dalam pengembangan bidang kecerdasan buatan, dan juga menunjukkan bahwa model sumber terbuka akan memainkan peran yang semakin penting di masa depan. Penerapan data sintetisnya memberikan ide-ide baru dalam memecahkan masalah seperti privasi data dan bias model, yang layak untuk dipelajari dan dijadikan referensi mendalam oleh industri. Kami menantikan munculnya model sumber terbuka yang lebih baik di masa depan untuk mendorong kemajuan teknologi kecerdasan buatan yang berkelanjutan.