Apache Kylin 分析データ ウェアハウス v4.0.3 正式版
4.0.3
Apache Kylin: 非常に大規模なデータに対する 1 秒未満のクエリ ツール
ダウンコードエディター
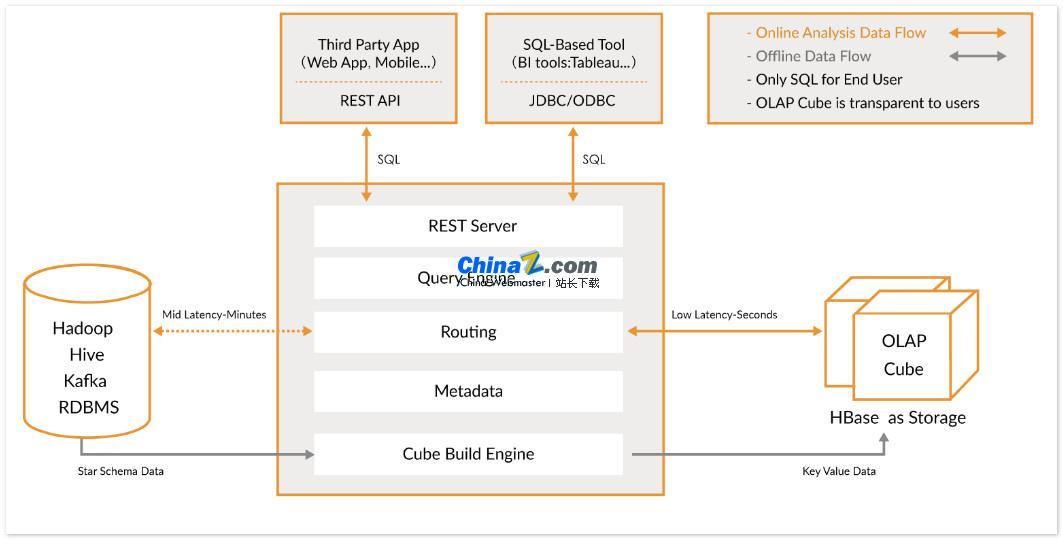
Apache Kylin は、Hadoop/Spark 上で SQL クエリ インターフェイスと多次元分析 (OLAP) 機能を提供するオープン ソースの分散分析データ ウェアハウスであり、非常に大規模なデータを効率的に処理できます。もともと eBay によって開発され、オープン ソース コミュニティに貢献したこのツールは、大量のデータに対するクエリを 1 秒未満で完了します。
Kylin の 3 つの主要なステップ
Kylin を使用すると、ユーザーはわずか 3 つのステップで非常に大規模なデータセットに対して 1 秒未満のクエリを実装できます。
1. データ セット上でスターまたはスノーフレーク モデルを定義します。まず、データ セットを記述するためにスターまたはスノーフレーク モデルを定義する必要があります。これは、Kylin がデータ間の関係を理解し、クエリのパフォーマンスを最適化するのに役立ちます。
2. キューブの構築: 定義されたデータ テーブル上にキューブを構築します。キューブは、Kylin がデータを事前計算して保存するための単位であり、クエリ速度を大幅に向上させることができます。
3. 標準 SQL クエリを使用する: 標準 SQL 構文を使用して、ODBC、JDBC、または RESTFUL API を通じて Cube にクエリを実行すると、Kylin は 1 秒未満でクエリ結果を返すことができます。
Kylin の統合機能
Kylin は、Tableau、Power BI などのさまざまなデータ視覚化ツールと統合します。ユーザーはこれらの BI ツールを使用して Hadoop データを分析し、データの洞察を視覚的に表示できます。
要約する
Apache Kylin は、ユーザーが非常に大規模なデータに対するクエリを 1 秒未満で完了できるようにする強力なツールです。使いやすさ、拡張性、効率性により、大規模なデータ分析の処理に最適です。