system design 101
1.0.0
【 ?? YouTube | ?ニュースレター】
複雑なシステムをビジュアルと簡単な用語を使って説明します。
システム設計面接の準備をしている場合でも、システムが水面下でどのように機能するかを単に理解したい場合でも、このリポジトリがそれを達成するのに役立つことを願っています。
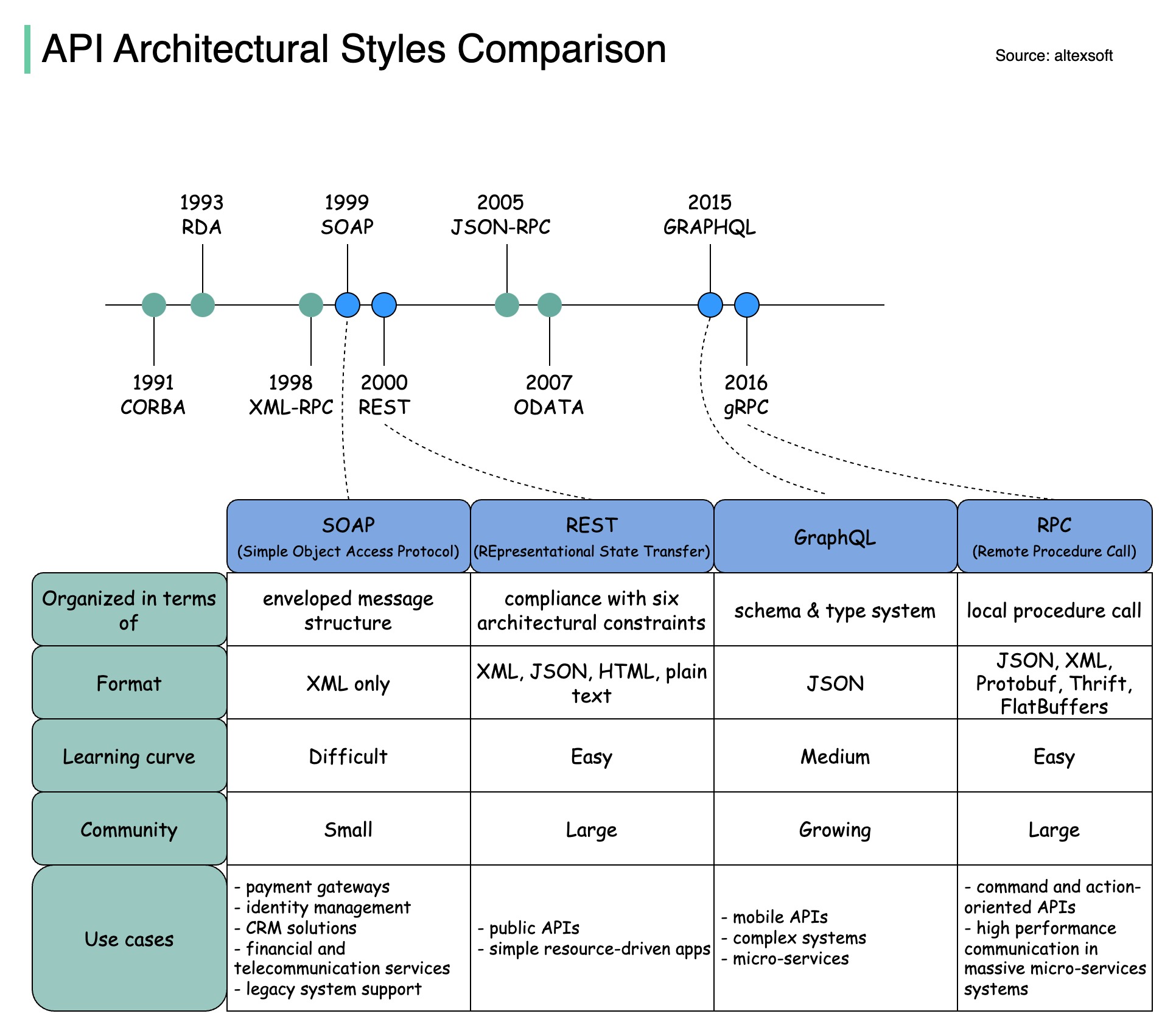
アーキテクチャ スタイルは、アプリケーション プログラミング インターフェイス (API) のさまざまなコンポーネントがどのように相互作用するかを定義します。その結果、API の設計と構築に対する標準的なアプローチを提供することで、効率性、信頼性、および他のシステムとの統合の容易さが確保されます。最もよく使用されるスタイルは次のとおりです。
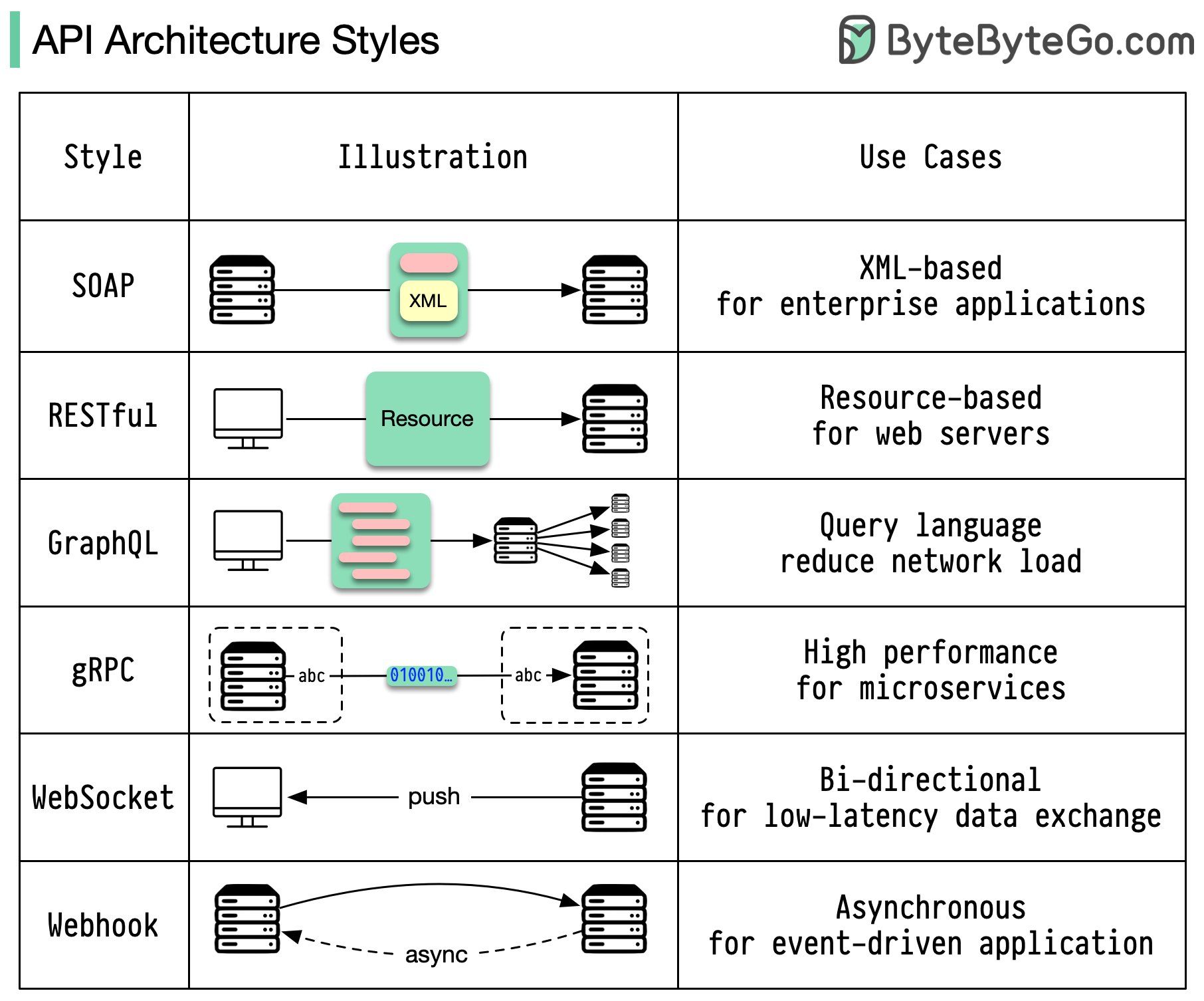
石鹸:
成熟した包括的な XML ベース
エンタープライズアプリケーションに最適
RESTful:
人気があり、実装が簡単な HTTP メソッド
Webサービスに最適
グラフQL:
クエリ言語、特定のデータのリクエスト
ネットワークのオーバーヘッドを削減し、応答を高速化します
gRPC:
最新の高性能プロトコル バッファ
マイクロサービスアーキテクチャに適しています
ウェブソケット:
リアルタイム、双方向、永続的な接続
低遅延のデータ交換に最適
Webhook:
イベント駆動型、HTTP コールバック、非同期
イベントが発生したときにシステムに通知します
API 設計に関しては、REST と GraphQL にはそれぞれ独自の長所と短所があります。
以下の図は、REST と GraphQL の簡単な比較を示しています。
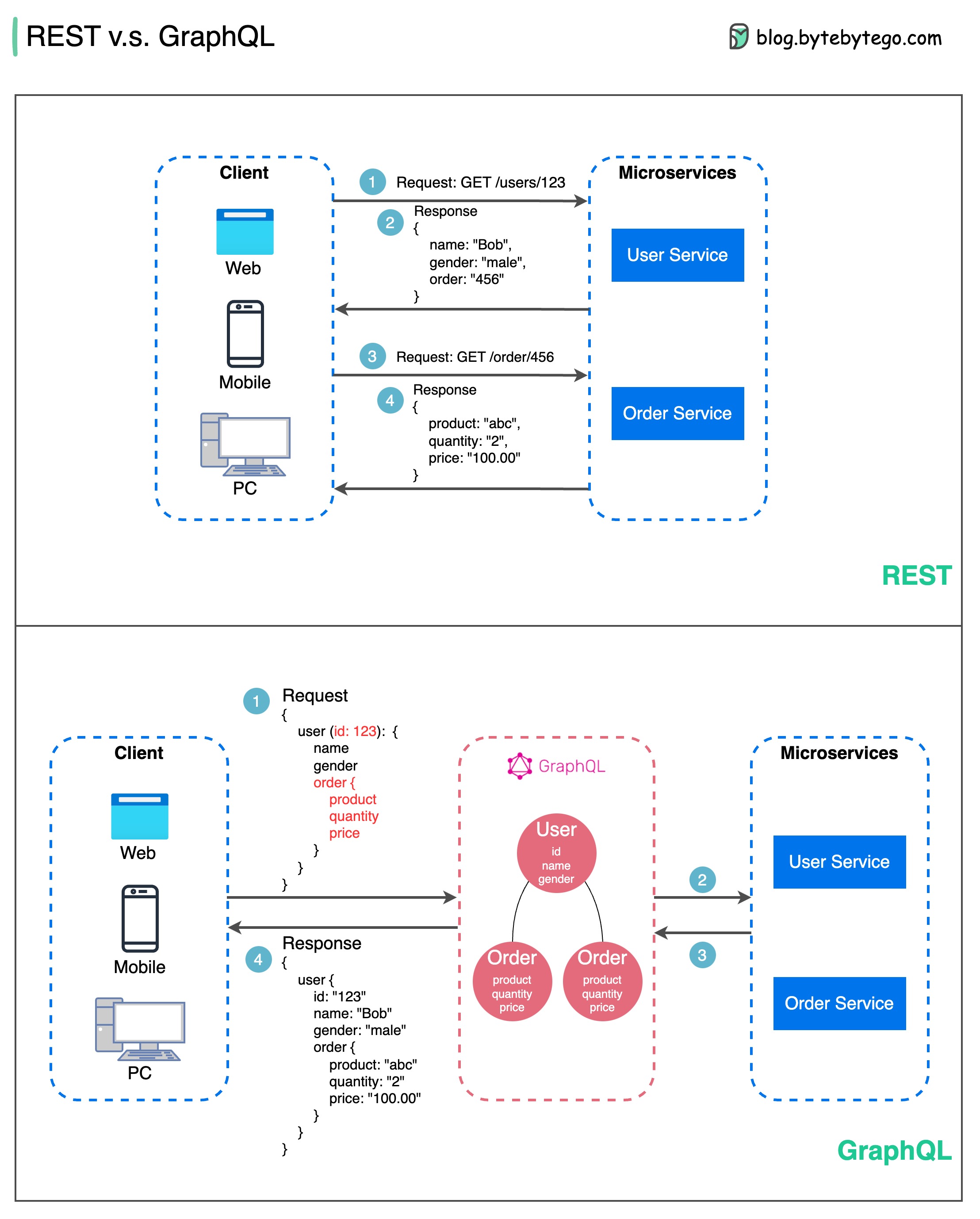
休む
グラフQL
REST と GraphQL のどちらを選択するのが最適かは、アプリケーションと開発チームの特定の要件によって異なります。 GraphQL は複雑なフロントエンドのニーズや頻繁に変化するフロントエンドのニーズに適していますが、REST はシンプルで一貫したコントラクトが好まれるアプリケーションに適しています。
どちらの API アプローチも特効薬ではありません。適切なスタイルを選択するには、要件とトレードオフを慎重に評価することが重要です。 REST と GraphQL はどちらも、データを公開して最新のアプリケーションを強化するための有効なオプションです。
RPC (Remote Procedure Call) は、マイクロサービス アーキテクチャの下でサービスが異なるサーバーにデプロイされる場合に、リモート サービス間の通信を可能にするため、「リモート」と呼ばれます。ユーザーの観点からは、ローカル関数呼び出しのように機能します。
以下の図は、 gRPCの全体的なデータ フローを示しています。
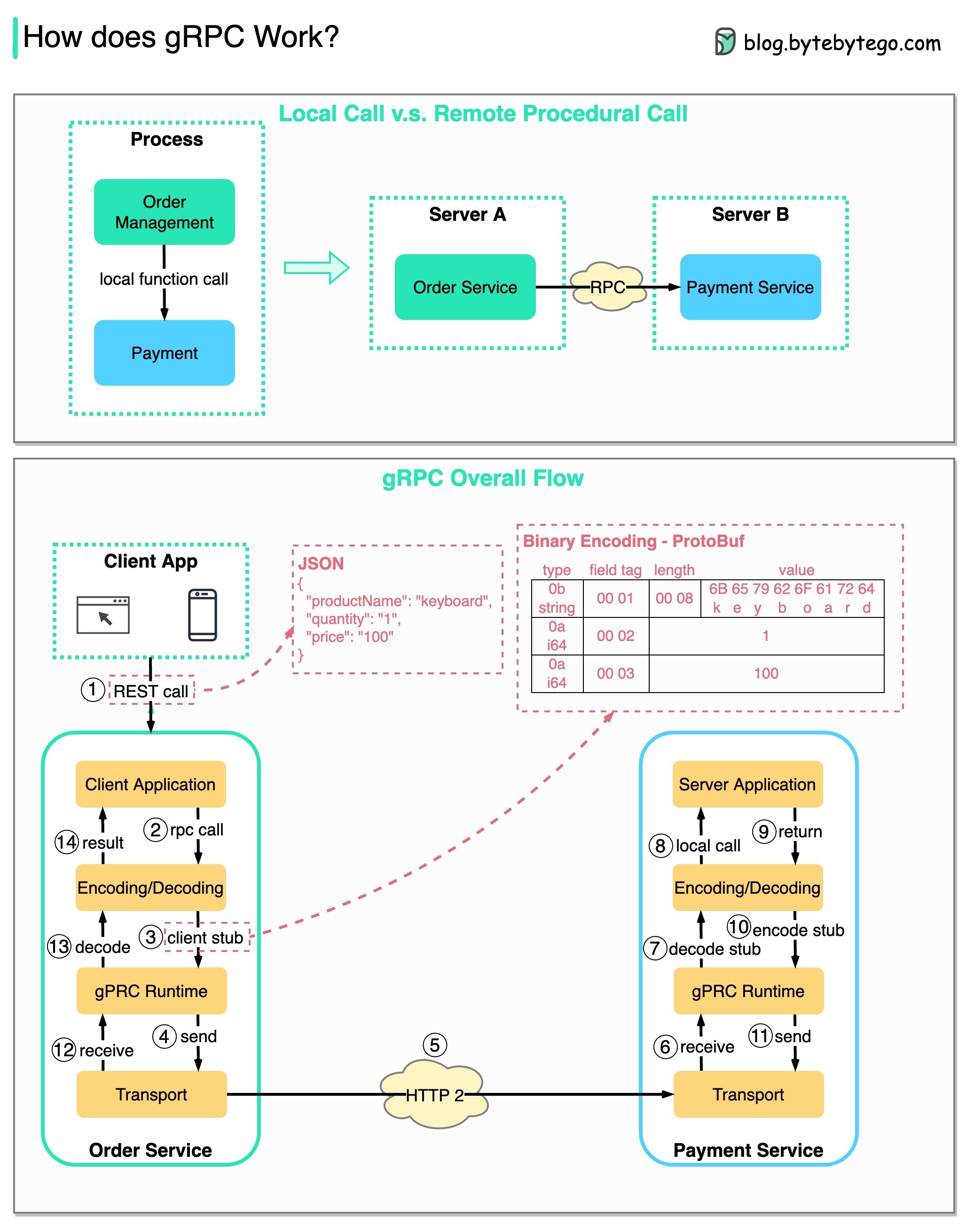
ステップ 1: REST 呼び出しがクライアントから行われます。リクエスト本文は通常、JSON 形式です。
ステップ 2 ~ 4: 注文サービス (gRPC クライアント) は REST 呼び出しを受信し、変換して、支払いサービスへの RPC 呼び出しを行います。 gRPC はクライアント スタブをバイナリ形式にエンコードし、低レベルのトランスポート層に送信します。
ステップ 5: gRPC は、HTTP2 経由でネットワーク上にパケットを送信します。バイナリ エンコードとネットワークの最適化により、gRPC は JSON より 5 倍高速であると言われています。
ステップ 6 ~ 8: 決済サービス (gRPC サーバー) はネットワークからパケットを受信し、デコードして、サーバー アプリケーションを呼び出します。
ステップ 9 ~ 11: 結果はサーバー アプリケーションから返され、エンコードされてトランスポート層に送信されます。
ステップ 12 ~ 14: オーダー サービスはパケットを受信し、デコードして、結果をクライアント アプリケーションに送信します。
以下の図は、ポーリングと Webhook の比較を示しています。
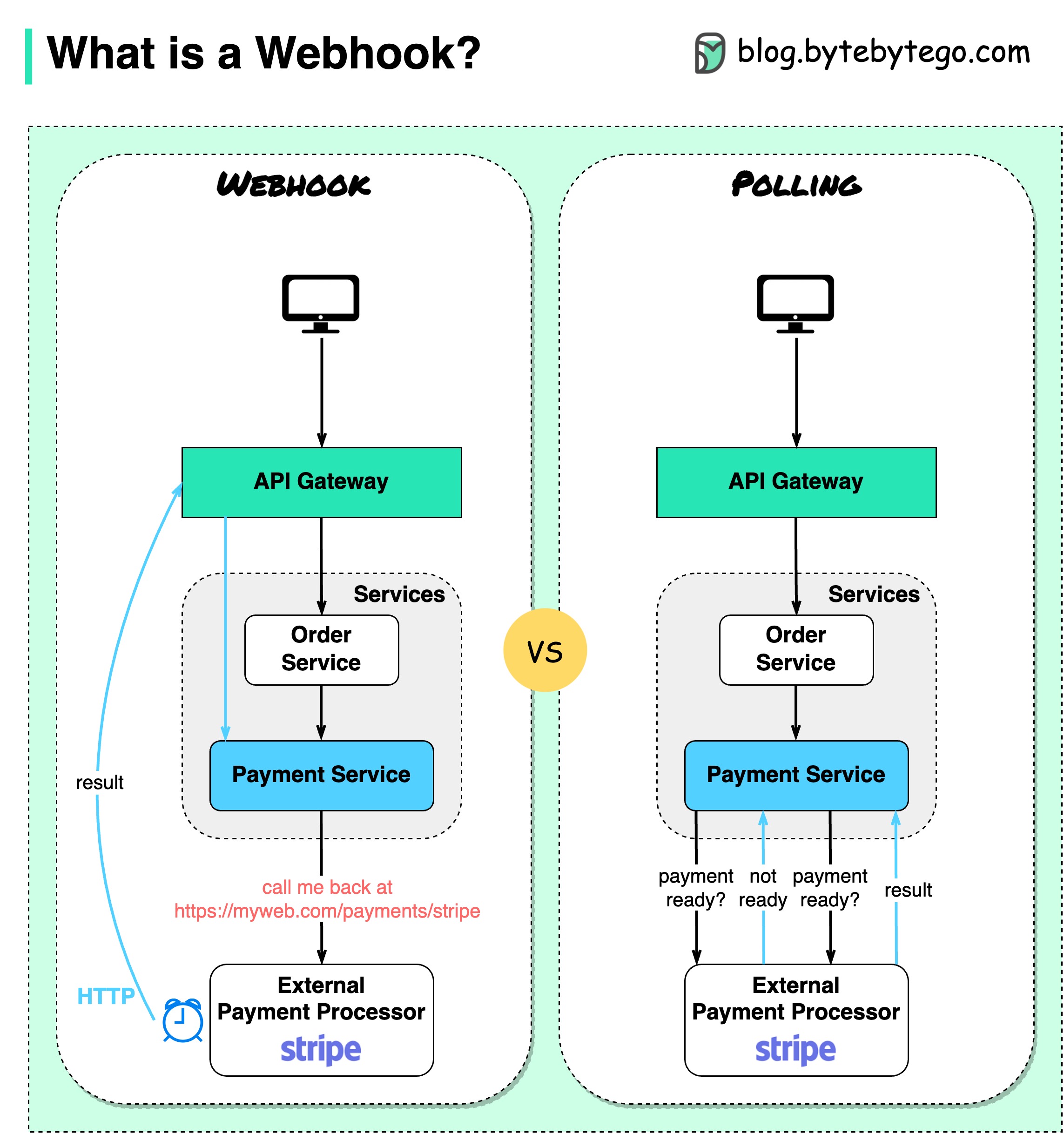
電子商取引 Web サイトを運営していると仮定します。クライアントは API ゲートウェイ経由で注文サービスに注文を送信し、注文サービスは支払いトランザクションのために支払いサービスに送られます。次に、支払いサービスは外部の支払いサービス プロバイダー (PSP) と通信して、トランザクションを完了します。
外部 PSP との通信を処理するには 2 つの方法があります。
1. ショートポーリング
支払いリクエストを PSP に送信した後、支払いサービスは PSP に支払いステータスを問い合わせ続けます。数ラウンドの後、PSP は最終的にステータスを返します。
ショートポーリングには 2 つの欠点があります。
2.Webhook
Webhook を外部サービスに登録できます。これは、リクエストに関する最新情報があれば、特定の URL に電話をかけ直すことを意味します。 PSP が処理を完了すると、HTTP リクエストを呼び出して支払いステータスを更新します。
このようにして、プログラミング パラダイムが変更され、支払いサービスは支払いステータスをポーリングするためにリソースを無駄にする必要がなくなりました。
PSP からコールバックがなかったらどうなるでしょうか?支払い状況を 1 時間ごとに確認するためのハウスキーピング ジョブを設定できます。
Webhook は、サーバーが HTTP リクエストをクライアントに送信するため、リバース API またはプッシュ API と呼ばれることがよくあります。 Webhook を使用するときは、次の 3 つの点に注意する必要があります。
以下の図は、API のパフォーマンスを向上させるための 5 つの一般的なトリックを示しています。
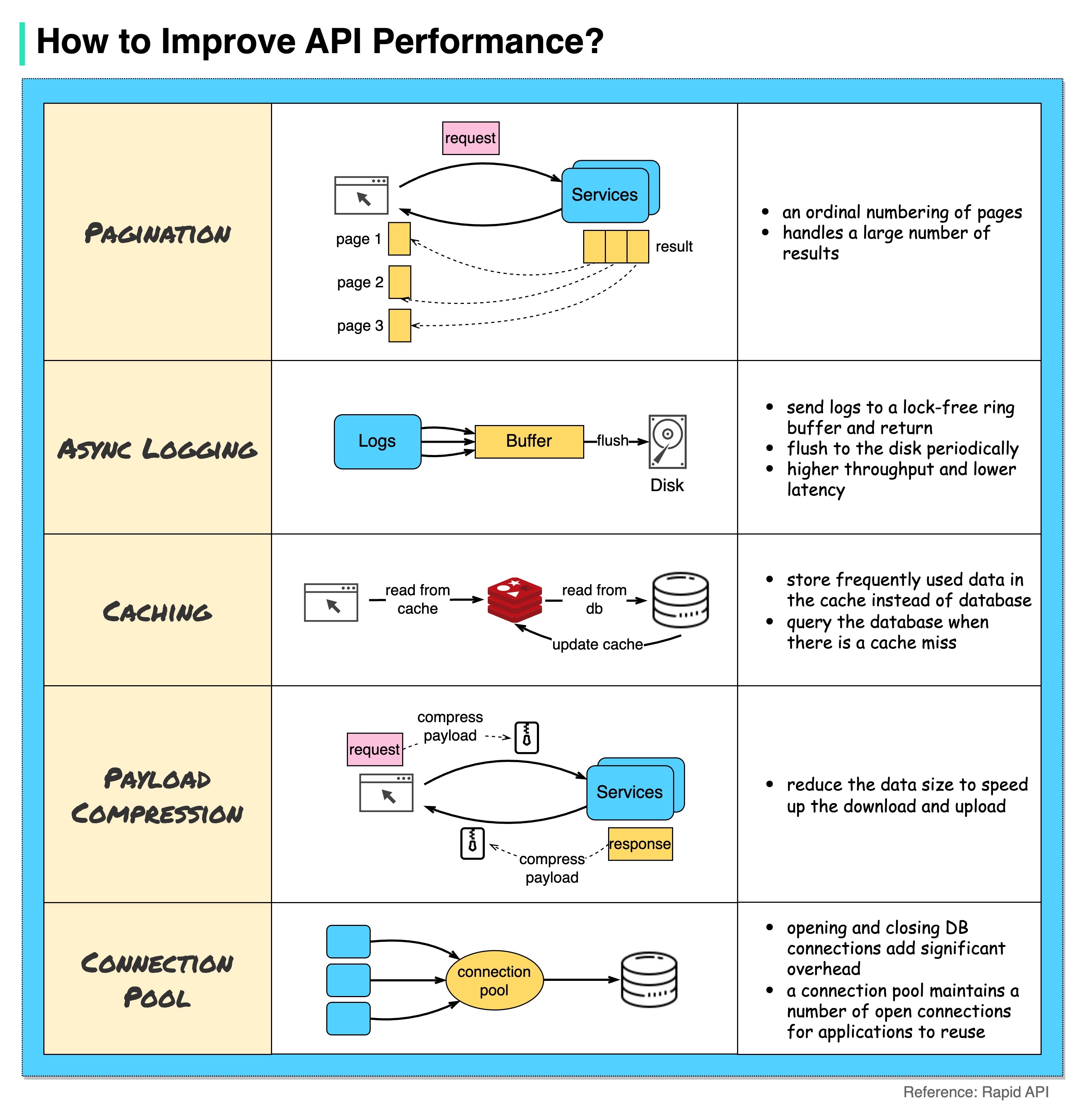
ページネーション
これは、結果のサイズが大きい場合によく行われる最適化です。結果はクライアントにストリーミングされて返され、サービスの応答性が向上します。
非同期ロギング
同期ログは呼び出しごとにディスクを処理するため、システムの速度が低下する可能性があります。非同期ログでは、最初にログがロックフリーのバッファに送信され、すぐに返されます。ログは定期的にディスクにフラッシュされます。これにより、I/O オーバーヘッドが大幅に削減されます。
キャッシング
頻繁にアクセスされるデータをキャッシュに保存できます。クライアントは、データベースに直接アクセスする代わりに、まずキャッシュにクエリを実行できます。キャッシュミスがあった場合、クライアントはデータベースからクエリを実行できます。 Redis のようなキャッシュはデータをメモリに保存するため、データ アクセスはデータベースよりもはるかに高速です。
ペイロード圧縮
リクエストとレスポンスは gzip などを使用して圧縮できるため、送信されるデータ サイズは大幅に小さくなります。これにより、アップロードとダウンロードが高速化されます。
接続プール
リソースにアクセスするとき、多くの場合、データベースからデータをロードする必要があります。閉じている DB 接続を開くと、大幅なオーバーヘッドが追加されます。したがって、開いている接続のプールを介してデータベースに接続する必要があります。接続プールは、接続のライフサイクルを管理します。
HTTP の各世代はどのような問題を解決しますか?
以下の図は主な機能を示しています。
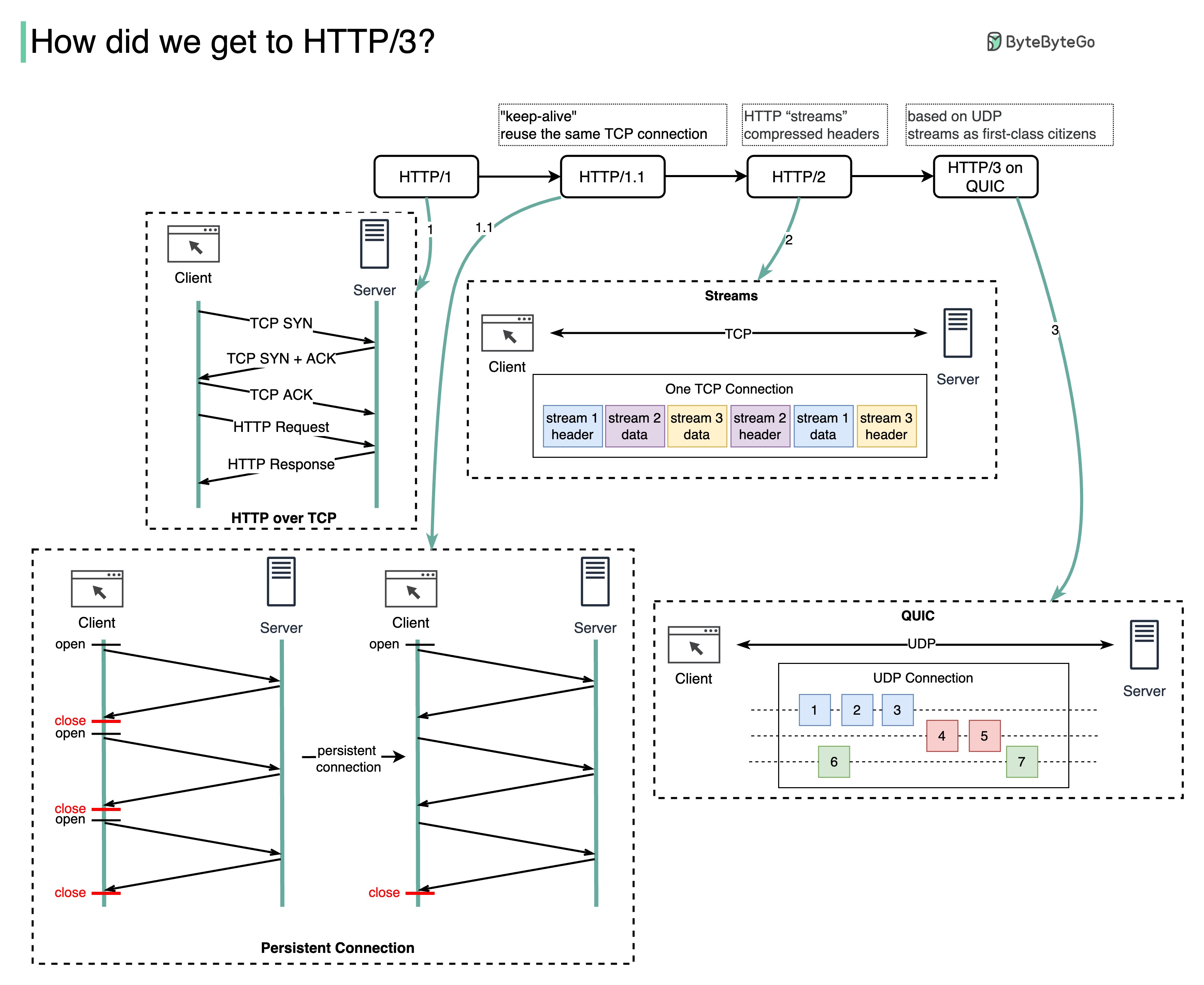
HTTP 1.0 は 1996 年に完成し、完全に文書化されました。同じサーバーへのすべてのリクエストには個別の TCP 接続が必要です。
HTTP 1.1 は 1997 年に公開されました。TCP 接続は再利用のために開いたままにすることができます (永続的な接続) が、HOL (ヘッドオブライン) ブロックの問題は解決されません。
HOL ブロック - ブラウザーで許可されている並列リクエストの数が使い果たされた場合、後続のリクエストは前のリクエストが完了するまで待機する必要があります。
HTTP 2.0 は 2015 年に公開されました。HTTP 2.0 はリクエストの多重化によって HOL の問題に対処し、アプリケーション層での HOL ブロックを排除しますが、トランスポート (TCP) 層には HOL がまだ存在します。
図からわかるように、HTTP 2.0 では HTTP 「ストリーム」という概念が導入されました。これは、異なる HTTP 交換を同じ TCP 接続上で多重化できる抽象化です。各ストリームを順番に送信する必要はありません。
HTTP 3.0 の最初のドラフトは 2020 年に公開されました。これは、HTTP 2.0 の後継として提案されています。基盤となるトランスポート プロトコルに TCP の代わりに QUIC を使用するため、トランスポート層での HOL ブロッキングが除去されます。
QUIC は UDP に基づいています。これにより、ストリームがトランスポート層の第一級市民として導入されます。 QUIC ストリームは同じ QUIC 接続を共有するため、新しいストリームを作成するために追加のハンドシェイクやスロー スタートは必要ありませんが、QUIC ストリームは独立して配信されるため、ほとんどの場合、1 つのストリームに影響を与えるパケット損失は他のストリームには影響しません。
以下の図は、API タイムラインと API スタイルの比較を示しています。
時間の経過とともに、さまざまな API アーキテクチャ スタイルがリリースされます。それぞれに、データ交換を標準化する独自のパターンがあります。
各スタイルの使用例を図で確認できます。
以下の図は、コードファースト開発と API ファースト開発の違いを示しています。 API ファーストの設計を検討する理由は何ですか?
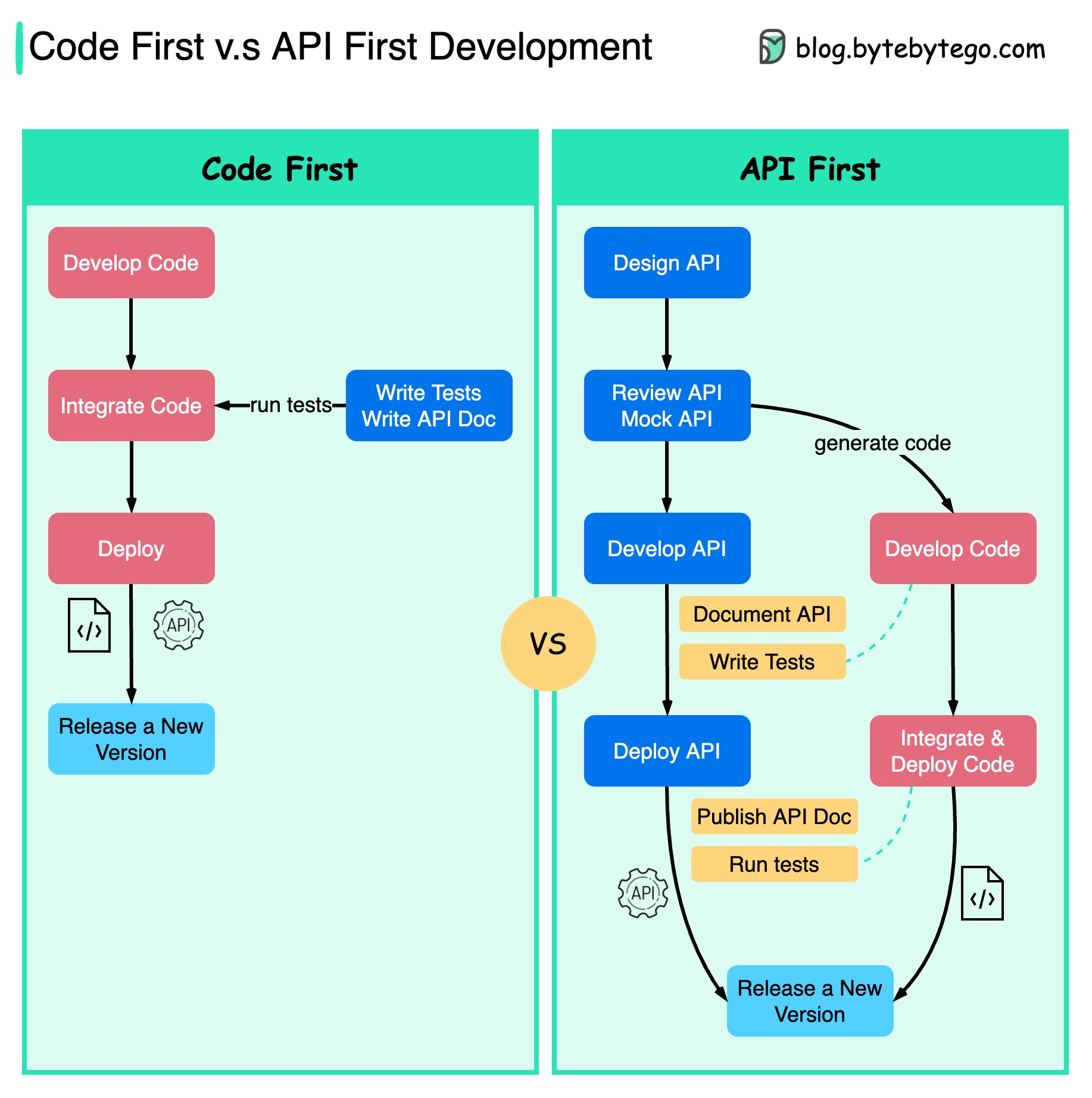
コードを記述し、サービスの境界を慎重に定義する前に、システムの複雑さを十分に検討することをお勧めします。
コードを記述する前に、リクエストとレスポンスをモックして API 設計を検証できます。
開発者も、突然の変更について交渉する代わりに機能開発に集中できるため、このプロセスに満足しています。
プロジェクトのライフサイクルの終わりに向けて予期せぬ事態が発生する可能性が低くなります。
最初に API を設計したため、コードの開発中にテストを設計できます。ある意味、APIファースト開発をする場合のTDD(テスト駆動設計)もあります。
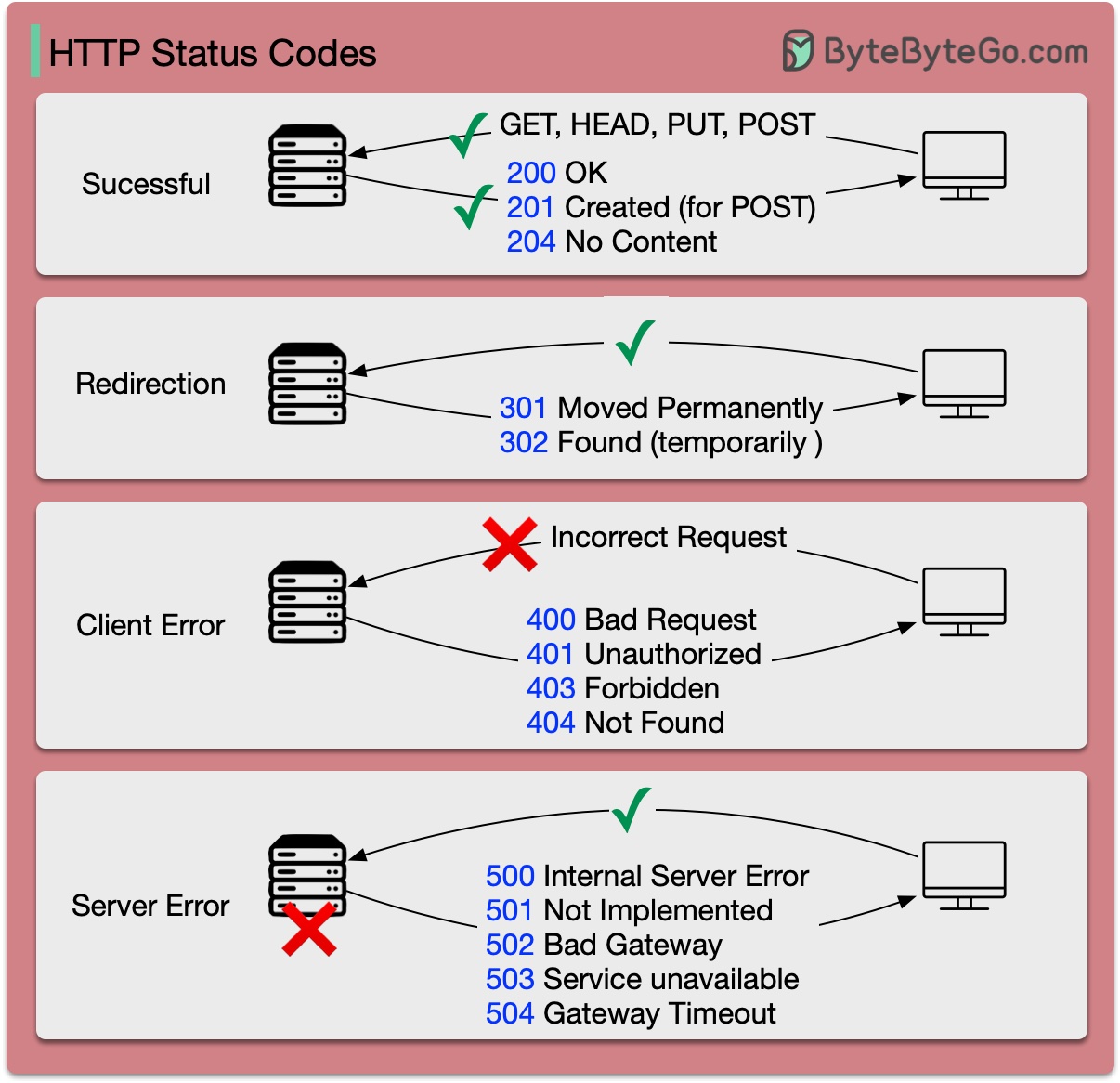
HTTP の応答コードは、次の 5 つのカテゴリに分類されます。
情報 (100-199) 成功 (200-299) リダイレクト (300-399) クライアント エラー (400-499) サーバー エラー (500-599)
以下の図に詳細を示します。
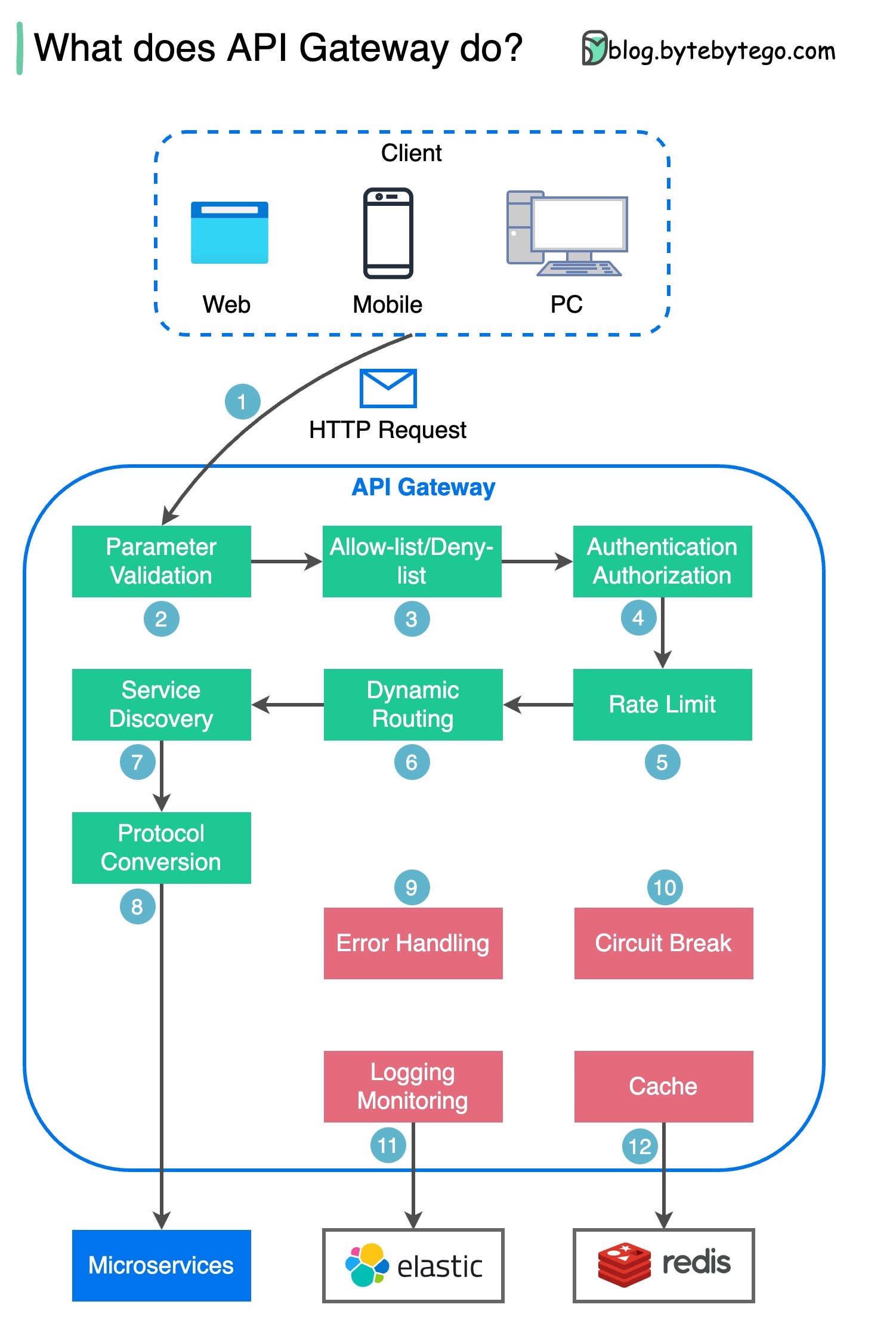
ステップ 1 - クライアントは HTTP リクエストを API ゲートウェイに送信します。
ステップ 2 - API ゲートウェイは、HTTP リクエスト内の属性を解析して検証します。
ステップ 3 - API ゲートウェイは、許可リスト/拒否リストのチェックを実行します。
ステップ 4 - API ゲートウェイは、認証と認可のために ID プロバイダーと通信します。
ステップ 5 - レート制限ルールがリクエストに適用されます。制限を超える場合、リクエストは拒否されます。
ステップ 6 と 7 - リクエストが基本的なチェックに合格したので、API ゲートウェイはパスの一致によってルーティング先の関連サービスを見つけます。
ステップ 8 - API ゲートウェイはリクエストを適切なプロトコルに変換し、バックエンド マイクロサービスに送信します。
ステップ 9 ~ 12: API ゲートウェイはエラーを適切に処理でき、エラーの回復に時間がかかる場合 (サーキット ブレーク) に障害を処理します。また、ログ記録と監視のために ELK (Elastic-Logstash-Kibana) スタックを利用することもできます。 API ゲートウェイにデータをキャッシュすることがあります。
以下の図は、ショッピング カートの例を含む一般的な API 設計を示しています。
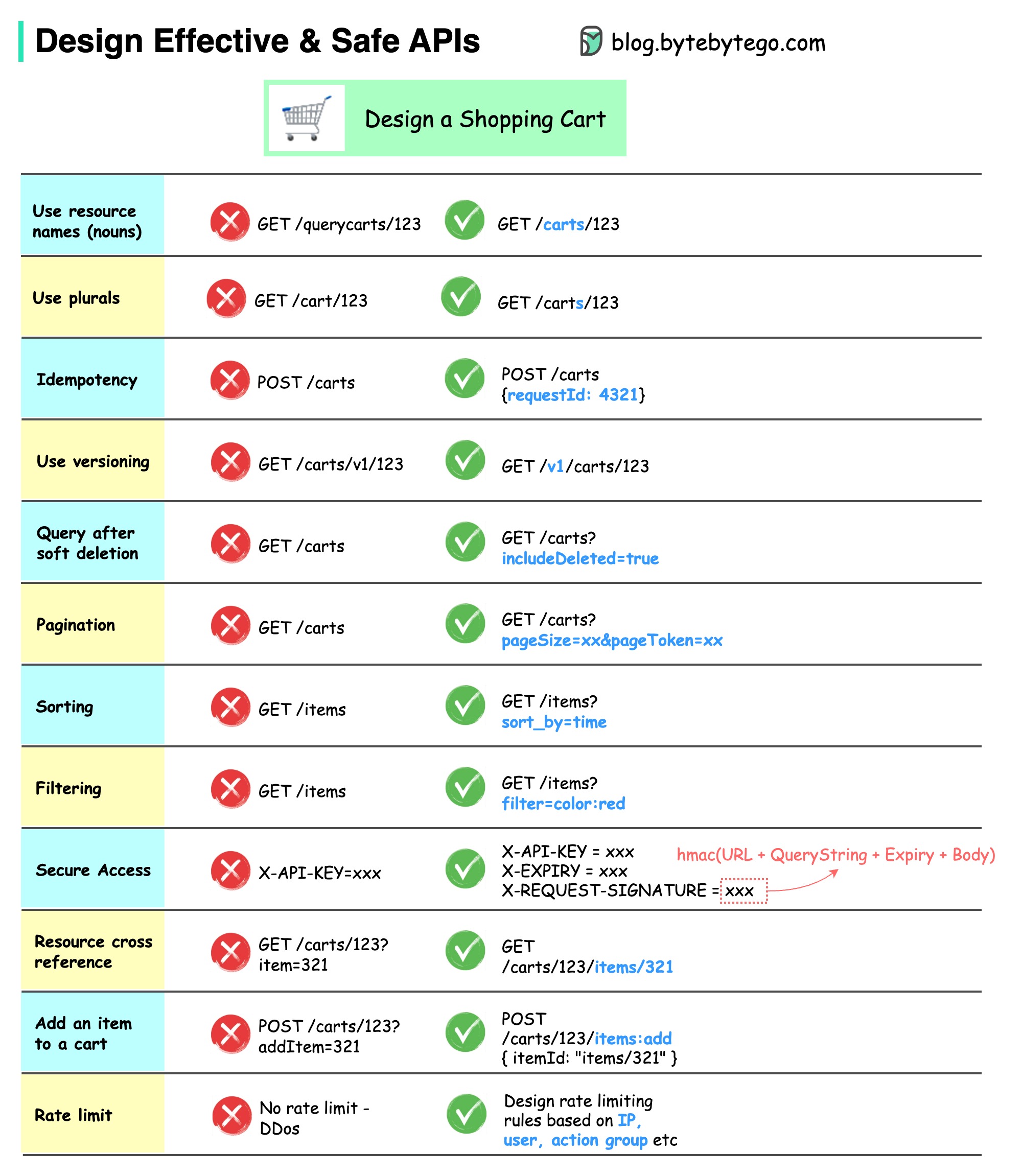
API 設計は単なる URL パス設計ではないことに注意してください。ほとんどの場合、適切なリソース名、識別子、パス パターンを選択する必要があります。適切な HTTP ヘッダー フィールドを設計すること、または API ゲートウェイ内で効果的なレート制限ルールを設計することも同様に重要です。
データはネットワーク上でどのように送信されるのでしょうか? OSI モデルにこれほど多くのレイヤーが必要なのはなぜですか?
以下の図は、ネットワーク上で送信するときにデータがどのようにカプセル化およびカプセル化解除されるかを示しています。
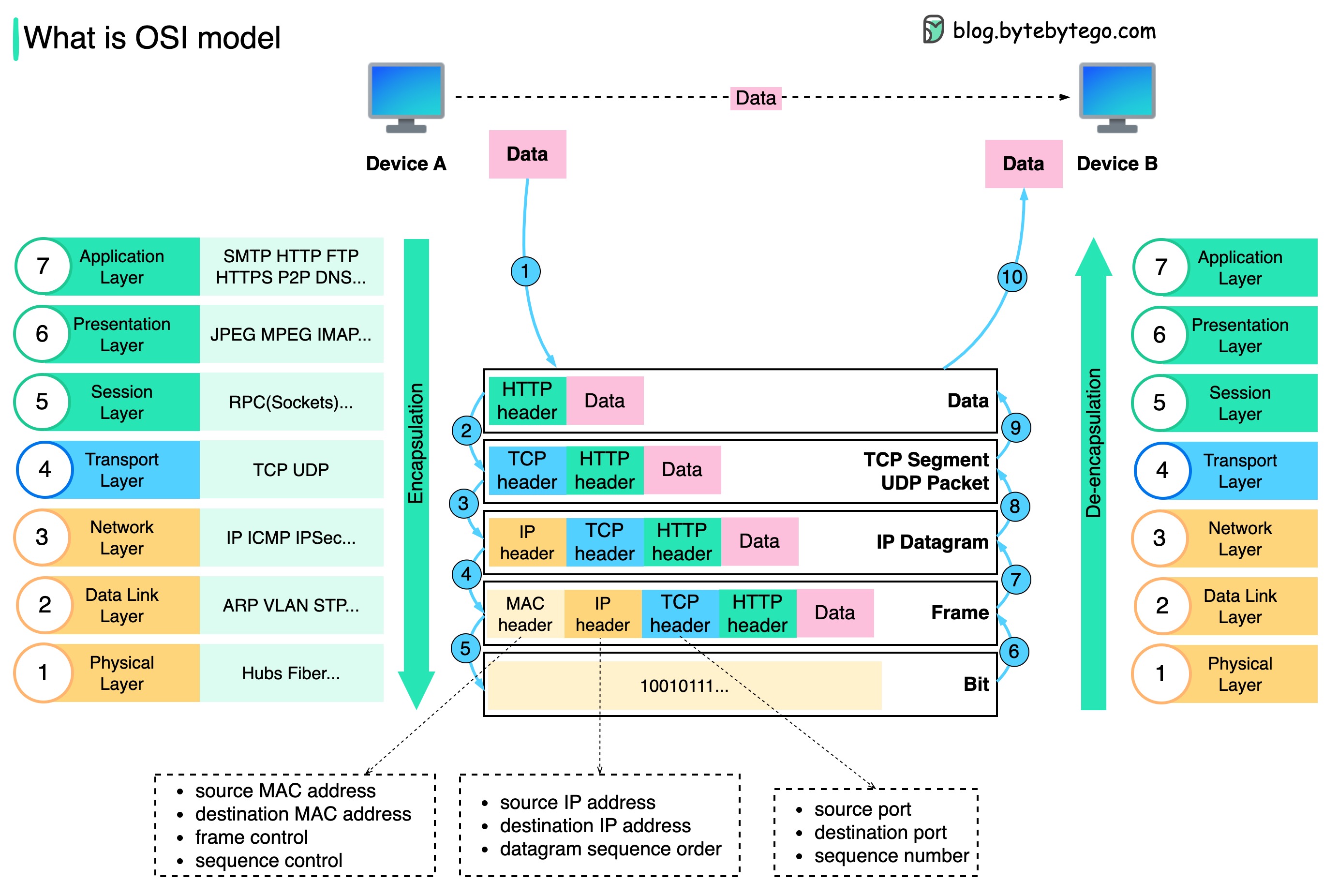
ステップ 1: デバイス A が HTTP プロトコルを介してネットワーク経由でデータをデバイス B に送信すると、まずアプリケーション層で HTTP ヘッダーが追加されます。
ステップ 2: 次に、TCP または UDP ヘッダーがデータに追加されます。これは、トランスポート層で TCP セグメントにカプセル化されます。ヘッダーには、送信元ポート、宛先ポート、およびシーケンス番号が含まれます。
ステップ 3: 次に、セグメントはネットワーク層で IP ヘッダーを使用してカプセル化されます。 IP ヘッダーには、送信元/宛先 IP アドレスが含まれます。
ステップ 4: IP データグラムには、送信元/宛先 MAC アドレスを含む MAC ヘッダーがデータリンク層に追加されます。
ステップ 5: カプセル化されたフレームは物理層に送信され、バイナリ ビットでネットワーク上に送信されます。
ステップ 6 ~ 10: デバイス B は、ネットワークからビットを受信すると、カプセル化プロセスの逆の処理であるカプセル化解除プロセスを実行します。ヘッダーはレイヤーごとに削除され、最終的にデバイス B はデータを読み取ることができるようになります。
各層がそれぞれの責任に重点を置くため、ネットワーク モデルには層が必要です。各層は処理命令のヘッダーに依存することができ、最後の層からのデータの意味を知る必要はありません。
以下の図は、??????? の違いを示しています。 ???????そして????????? ???????。
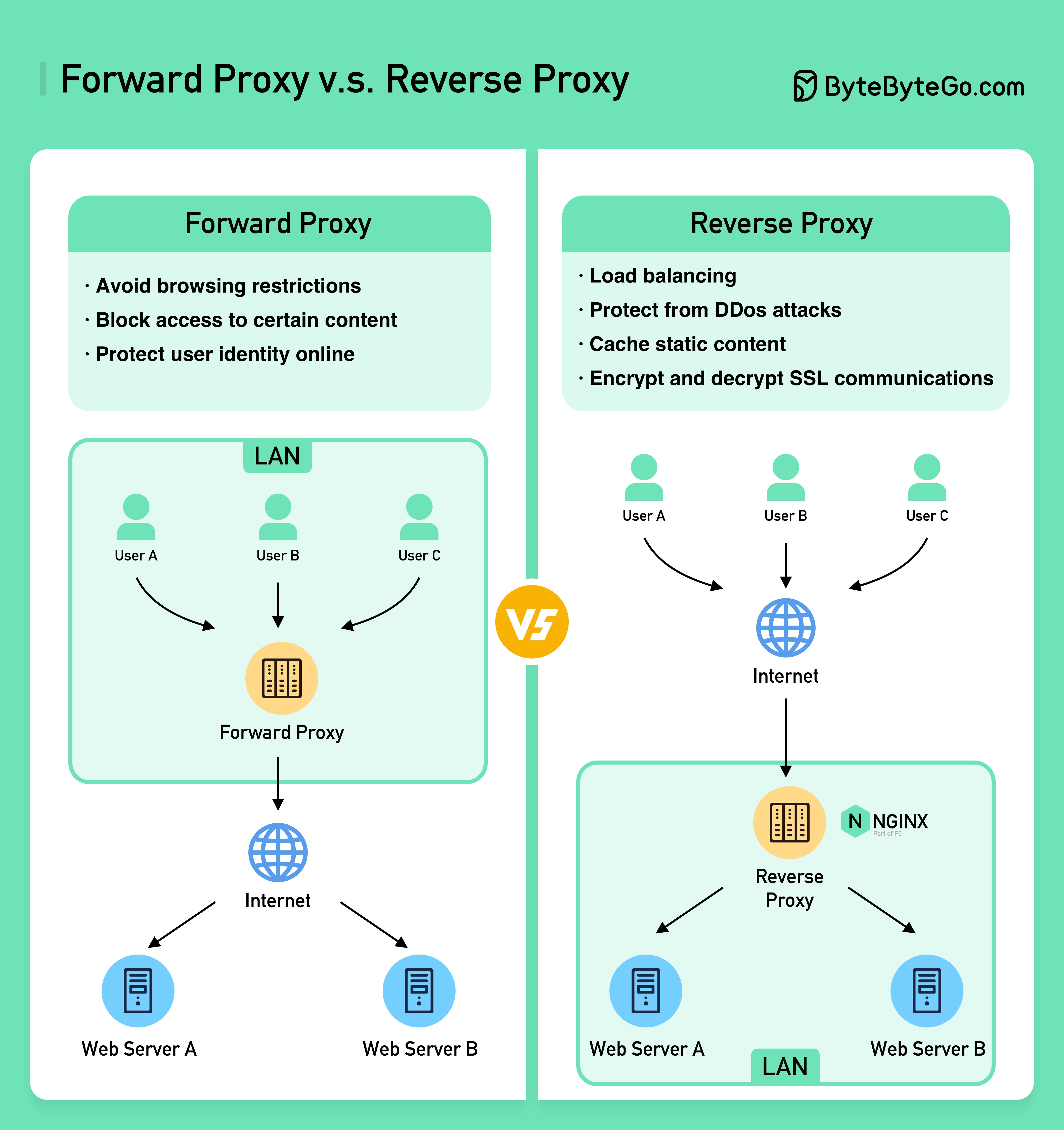
フォワード プロキシは、ユーザー デバイスとインターネットの間にあるサーバーです。
フォワード プロキシは通常、次の目的で使用されます。
リバース プロキシは、クライアントからのリクエストを受け取り、そのリクエストを Web サーバーに転送し、プロキシ サーバーがリクエストを処理したかのように結果をクライアントに返すサーバーです。
リバース プロキシは次の場合に適しています。
以下の図は、6 つの一般的なアルゴリズムを示しています。
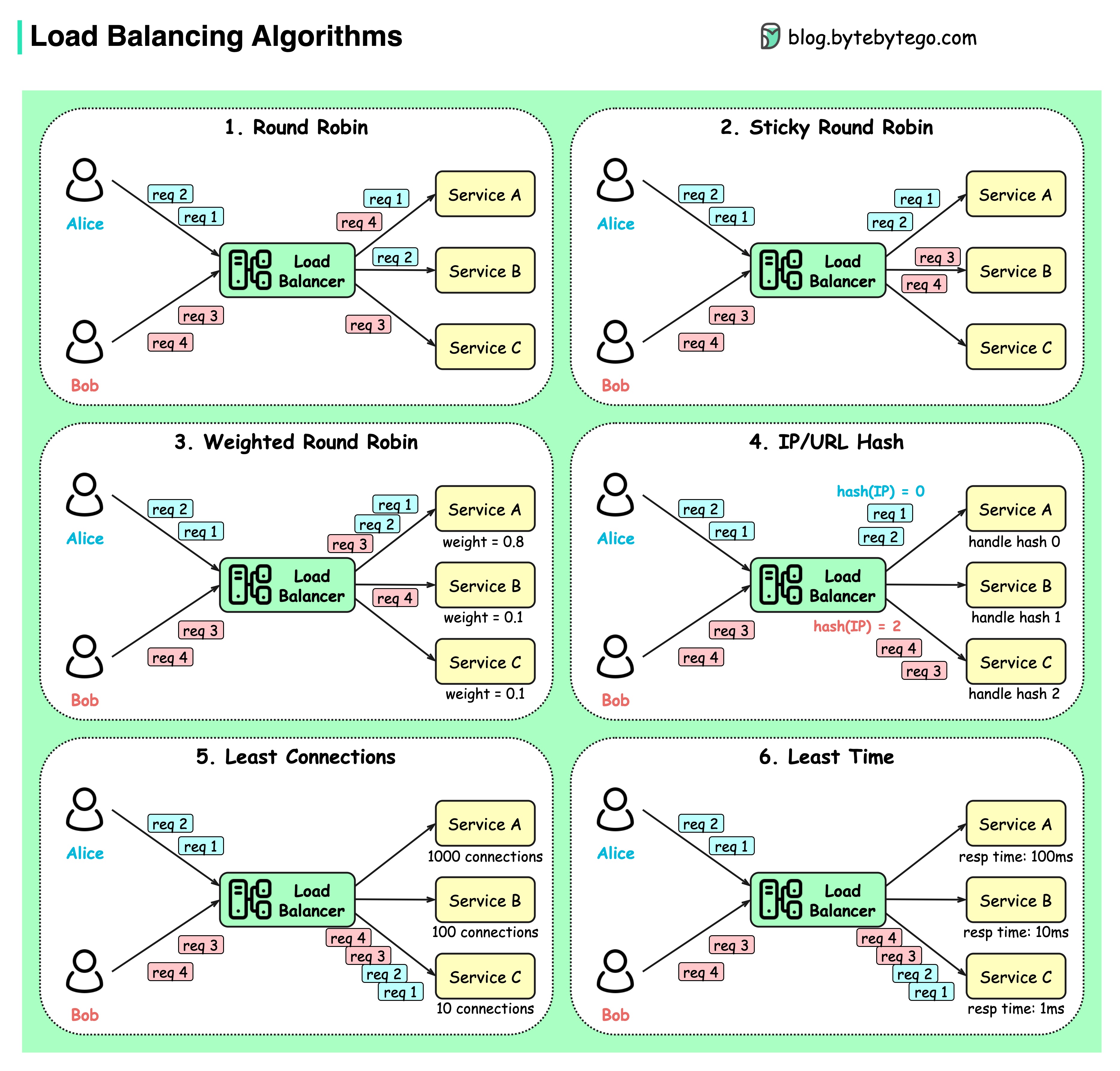
ラウンドロビン
クライアント要求は、異なるサービス インスタンスに順番に送信されます。通常、サービスはステートレスである必要があります。
スティッキーラウンドロビン
これはラウンドロビン アルゴリズムの改良です。アリスの最初のリクエストがサービス A に送られると、次のリクエストもサービス A に送られます。
加重ラウンドロビン
管理者はサービスごとに重みを指定できます。重みが大きいものは、他のものよりも多くのリクエストを処理します。
ハッシュ
このアルゴリズムは、受信リクエストの IP または URL にハッシュ関数を適用します。リクエストは、ハッシュ関数の結果に基づいて関連するインスタンスにルーティングされます。
最小接続数
新しいリクエストは、同時接続が最も少ないサービス インスタンスに送信されます。
最短の応答時間
新しいリクエストは、応答時間が最も速いサービス インスタンスに送信されます。
次の図は、URL、URI、URN の比較を示しています。
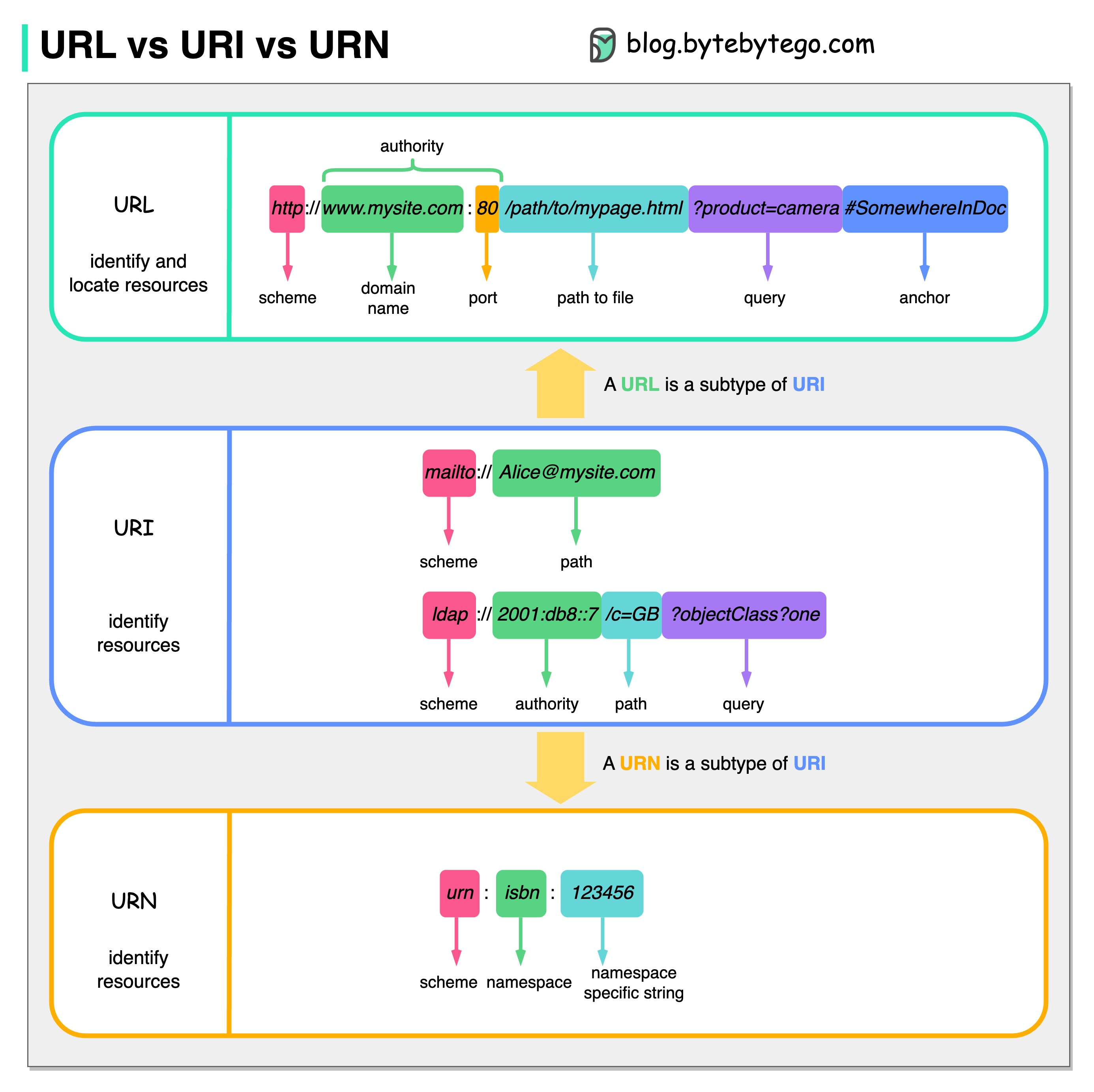
URI は、Uniform Resource Identifier の略です。これは、Web 上の論理的または物理的なリソースを識別します。 URL と URN は URI のサブタイプです。 URL はリソースを特定し、URN はリソースに名前を付けます。
URI は次の部分で構成されます: スキーム:[//authority]path[?query][#fragment]
URL は、Uniform Resource Locator の略で、HTTP の重要な概念です。これは、Web 上の固有のリソースのアドレスです。 FTP や JDBC などの他のプロトコルでも使用できます。
URN は、Uniform Resource Name の略です。これは、urn スキームを使用します。 URN を使用してリソースを見つけることはできません。図に示されている簡単な例は、名前空間と名前空間固有の文字列で構成されています。
この件についてさらに詳しく知りたい場合は、W3C の説明を参照することをお勧めします。
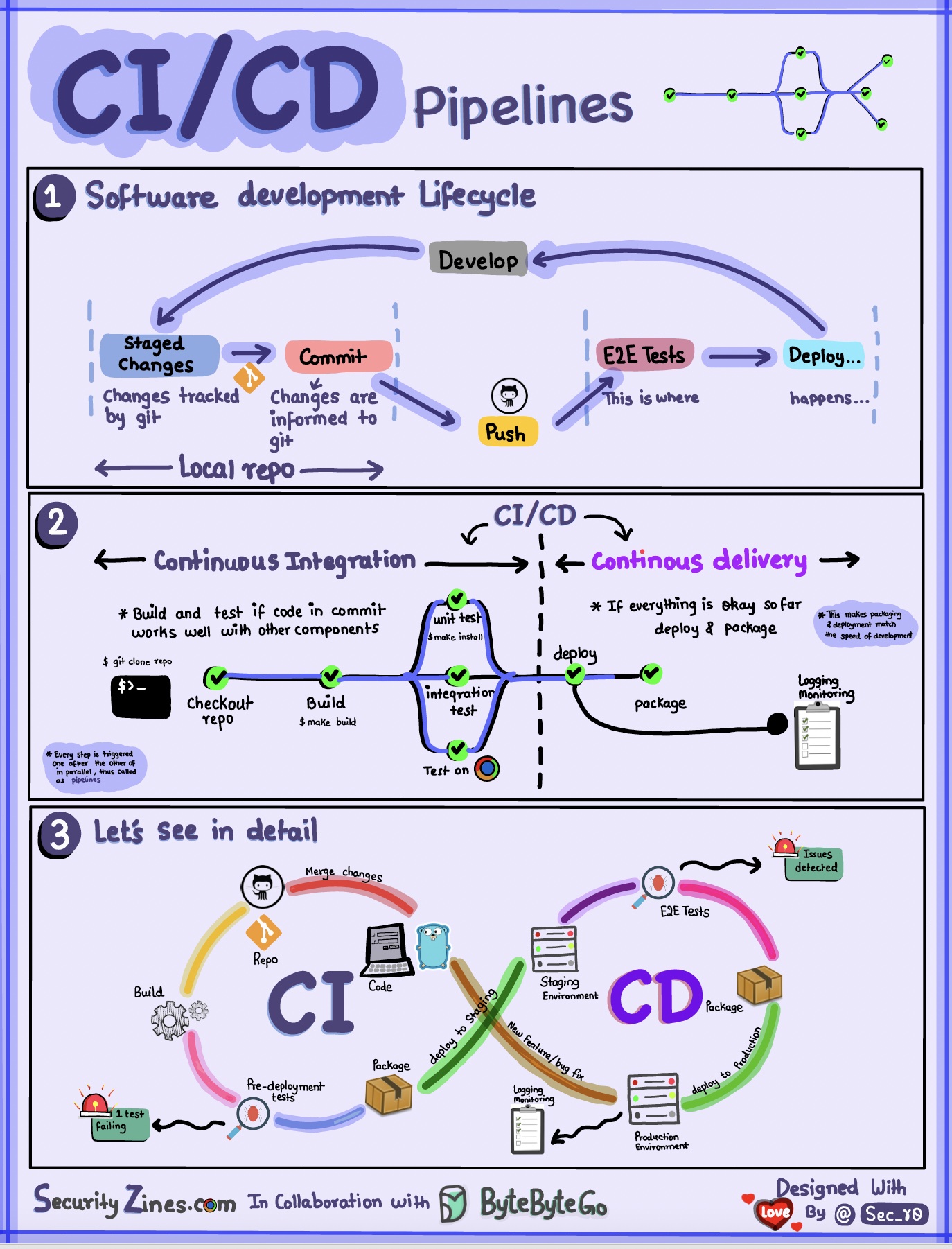
セクション 1 - CI/CD を使用した SDLC
ソフトウェア開発ライフ サイクル (SDLC) は、開発、テスト、展開、メンテナンスといういくつかの主要な段階で構成されます。 CI/CD はこれらの段階を自動化および統合して、より迅速で信頼性の高いリリースを可能にします。
コードが git リポジトリにプッシュされると、自動化されたビルドとテストのプロセスがトリガーされます。コードを検証するためにエンドツーエンド (e2e) テスト ケースが実行されます。テストに合格すると、コードはステージング/運用環境に自動的にデプロイされます。問題が見つかった場合、コードはバグ修正のために開発に返送されます。この自動化により、開発者に迅速なフィードバックが提供され、運用環境でのバグのリスクが軽減されます。
セクション 2 - CI と CD の違い
継続的インテグレーション (CI) は、ビルド、テスト、マージのプロセスを自動化します。コードがコミットされるたびにテストを実行して、統合の問題を早期に検出します。これにより、コードの頻繁なコミットと迅速なフィードバックが促進されます。
継続的デリバリー (CD) は、インフラストラクチャの変更や展開などのリリース プロセスを自動化します。自動化されたワークフローを通じて、いつでもソフトウェアを確実にリリースできるようになります。 CD は、運用展開前に必要な手動のテストと承認の手順を自動化することもできます。
セクション 3 - CI/CD パイプライン
一般的な CI/CD パイプラインには、いくつかの接続されたステージがあります。
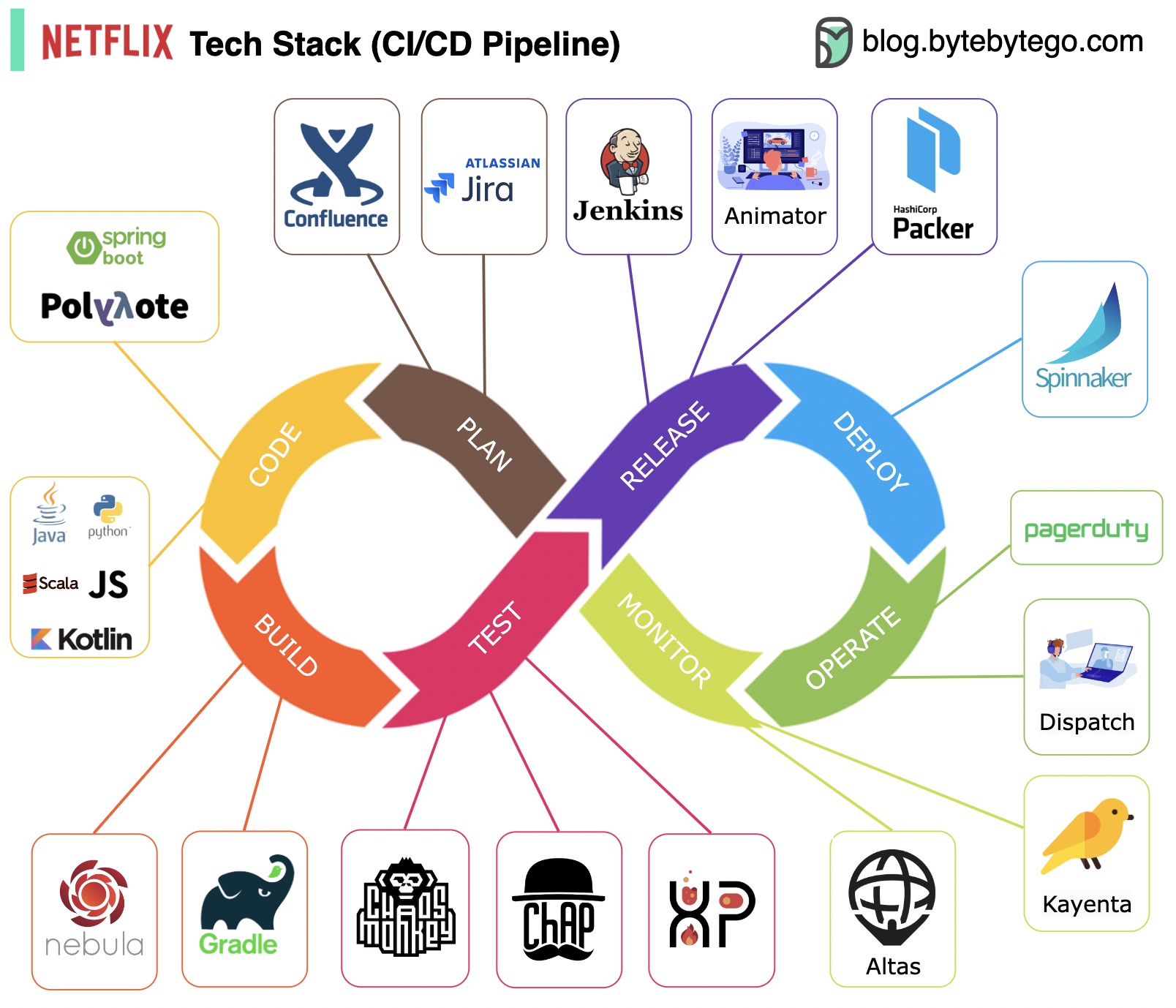
計画: Netflix エンジニアリングは計画に JIRA を使用し、ドキュメントに Confluence を使用します。
コーディング: Java はバックエンド サービスの主要なプログラミング言語ですが、他の言語はさまざまなユースケースに使用されます。
ビルド: Gradle は主にビルドに使用され、Gradle プラグインはさまざまなユースケースをサポートするために構築されています。
パッケージ化: パッケージと依存関係は、リリース用に Amazon Machine Image (AMI) にパッケージ化されます。
テスト: テストでは、運用文化がカオス ツールの構築に重点を置いていることが強調されます。
導入: Netflix は、カナリアのロールアウト導入に自社構築の Spinnaker を使用します。
監視: 監視メトリクスは Atlas に集中されており、異常の検出には Kayenta が使用されます。
インシデントレポート: インシデントは優先度に従って発送され、インシデント処理には PagerDuty が使用されます。
これらのアーキテクチャ パターンは、iOS プラットフォームでも Android プラットフォームでも、アプリ開発で最も一般的に使用されます。開発者は、以前のパターンの制限を克服するためにこれらを導入しました。では、それらはどのように異なるのでしょうか?
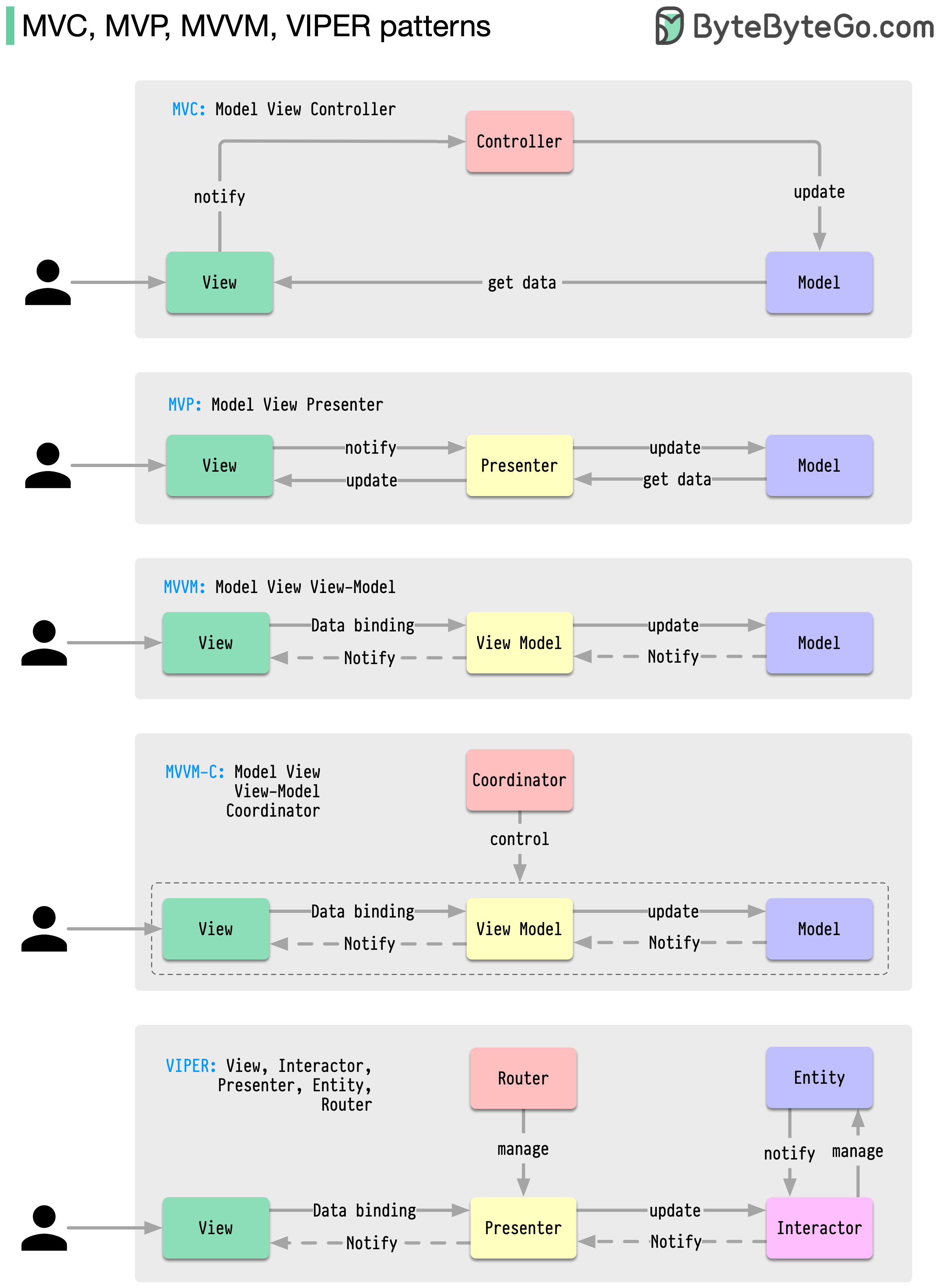
パターンは一般的な設計上の問題に対する再利用可能なソリューションであり、その結果、よりスムーズで効率的な開発プロセスが実現します。これらは、より優れたソフトウェア構造を構築するための青写真として機能します。以下は最も一般的なパターンの一部です。

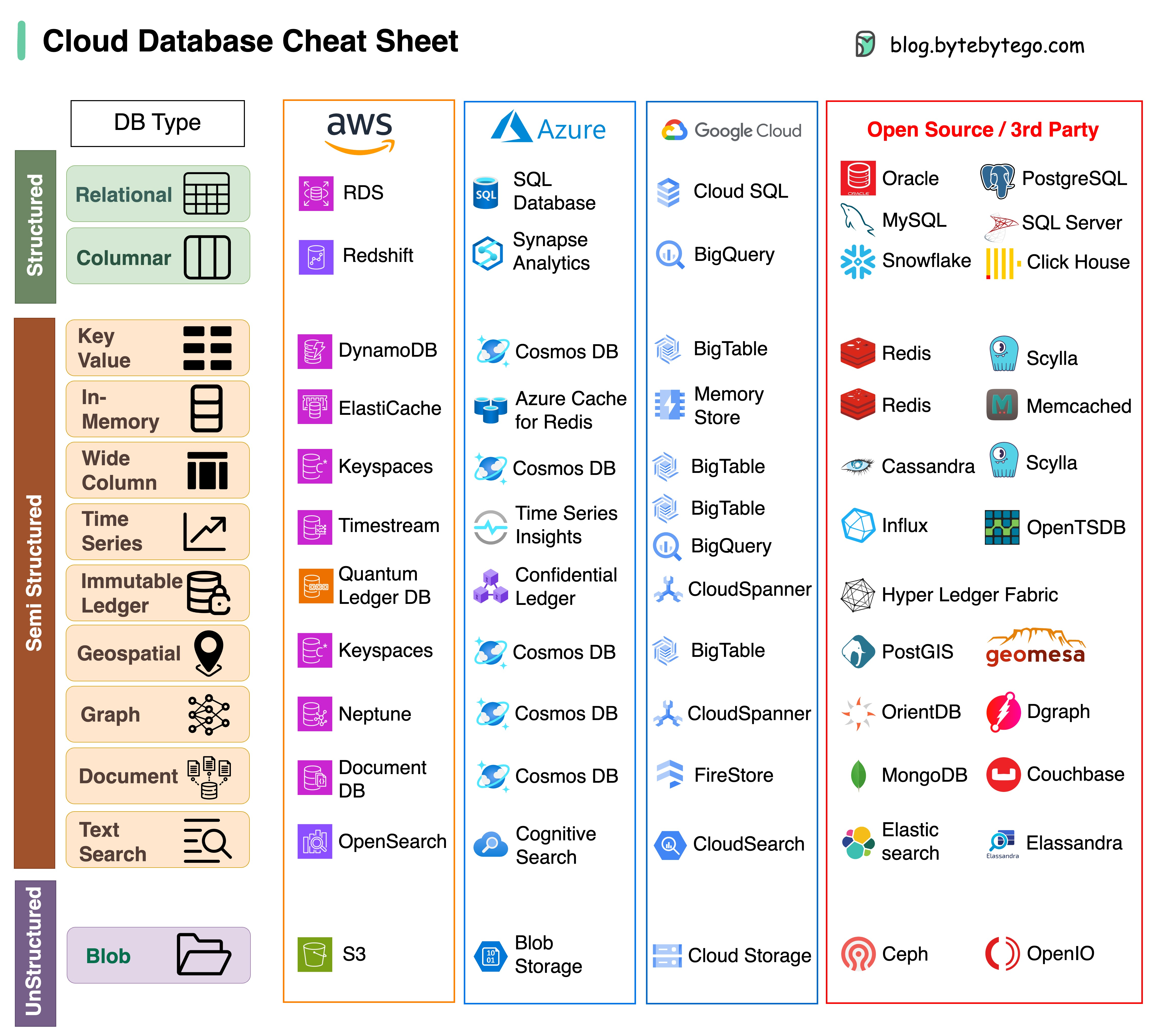
プロジェクトに適切なデータベースを選択するのは複雑な作業です。多くのデータベース オプションは、それぞれ異なるユースケースに適していますが、すぐに意思決定疲れにつながる可能性があります。
このチートシートが、プロジェクトのニーズに合った適切なサービスを特定し、潜在的な落とし穴を回避するための高レベルの指示を提供することを願っています。
注: Google では、データベースの使用例に関するドキュメントが限られています。利用可能なものを検討して最善のオプションに到達するために最善を尽くしましたが、一部のエントリはより正確にする必要がある場合があります。
答えはユースケースによって異なります。データはメモリ内またはディスク上でインデックスを作成できます。同様に、データ形式も数値、文字列、地理座標などさまざまです。システムは書き込みが多い場合もあれば、読み取りが多い場合もあります。これらすべての要因が、データベース インデックス形式の選択に影響します。
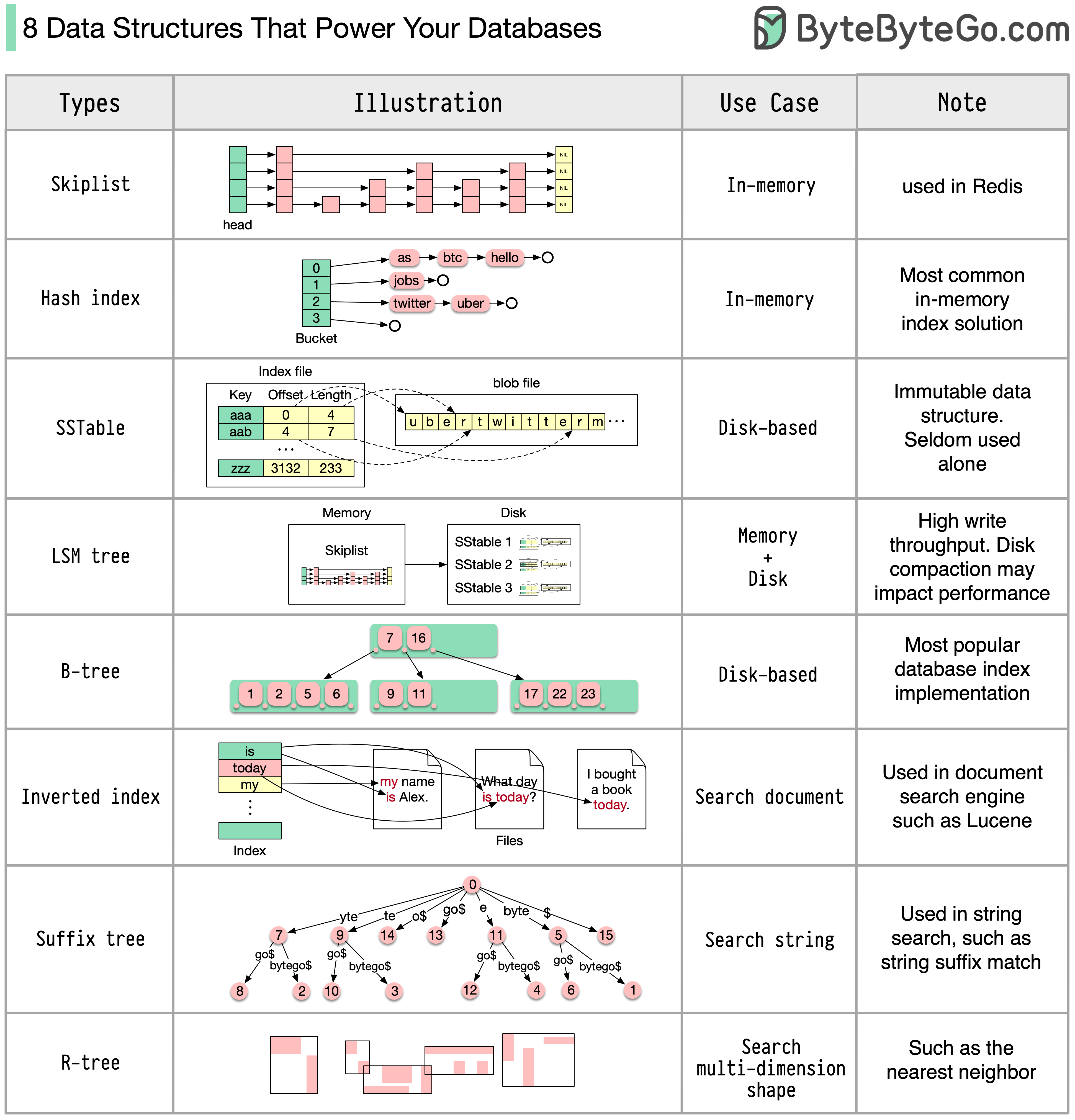
以下は、データのインデックス付けに使用される最も一般的なデータ構造の一部です。
以下の図はそのプロセスを示しています。データベースごとにアーキテクチャが異なることに注意してください。図はいくつかの一般的な設計を示しています。
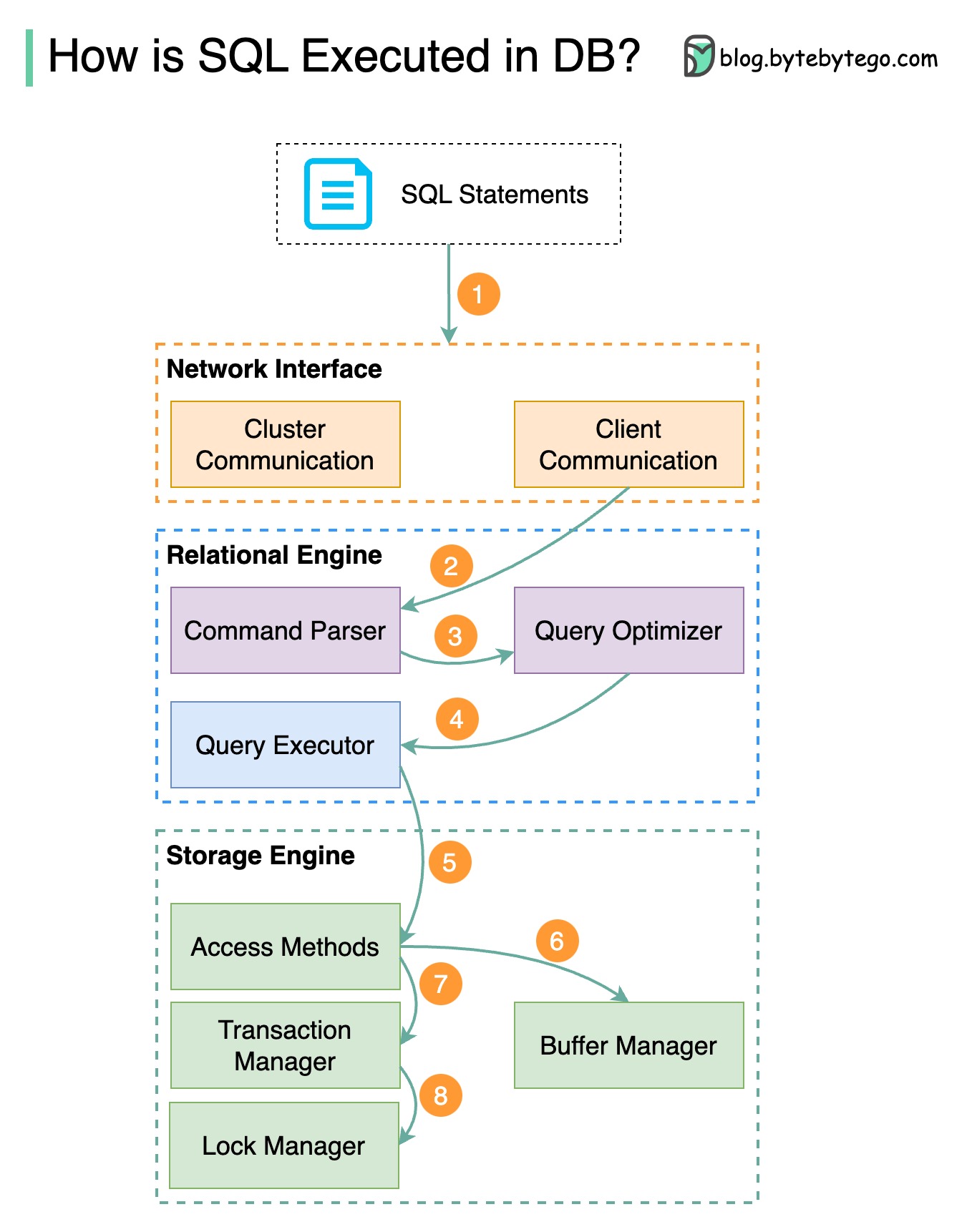
ステップ 1 - SQL ステートメントがトランスポート層プロトコル (TCP など) 経由でデータベースに送信されます。
ステップ 2 - SQL ステートメントはコマンド パーサーに送信され、そこで構文分析と意味分析が行われ、その後クエリ ツリーが生成されます。
ステップ 3 - クエリ ツリーがオプティマイザに送信されます。オプティマイザーは実行計画を作成します。
ステップ 4 - 実行計画が実行者に送信されます。エグゼキュータは実行からデータを取得します。
ステップ 5 - アクセス メソッドは、実行に必要なデータ フェッチ ロジックを提供し、ストレージ エンジンからデータを取得します。
ステップ 6 - アクセス メソッドは、SQL ステートメントが読み取り専用かどうかを決定します。クエリが読み取り専用 (SELECT ステートメント) の場合、クエリはさらなる処理のためにバッファ マネージャーに渡されます。バッファ マネージャーは、キャッシュまたはデータ ファイル内のデータを検索します。
ステップ 7 - ステートメントが UPDATE または INSERT の場合、さらなる処理のためにトランザクション マネージャーに渡されます。
ステップ 8 - トランザクション中、データはロック モードになります。これはロック マネージャーによって保証されています。また、トランザクションの ACID プロパティも保証します。
CAP 定理はコンピューター サイエンスで最も有名な用語の 1 つですが、開発者によって理解が異なると思います。それが何なのか、なぜ混乱を招くのかを見てみましょう。
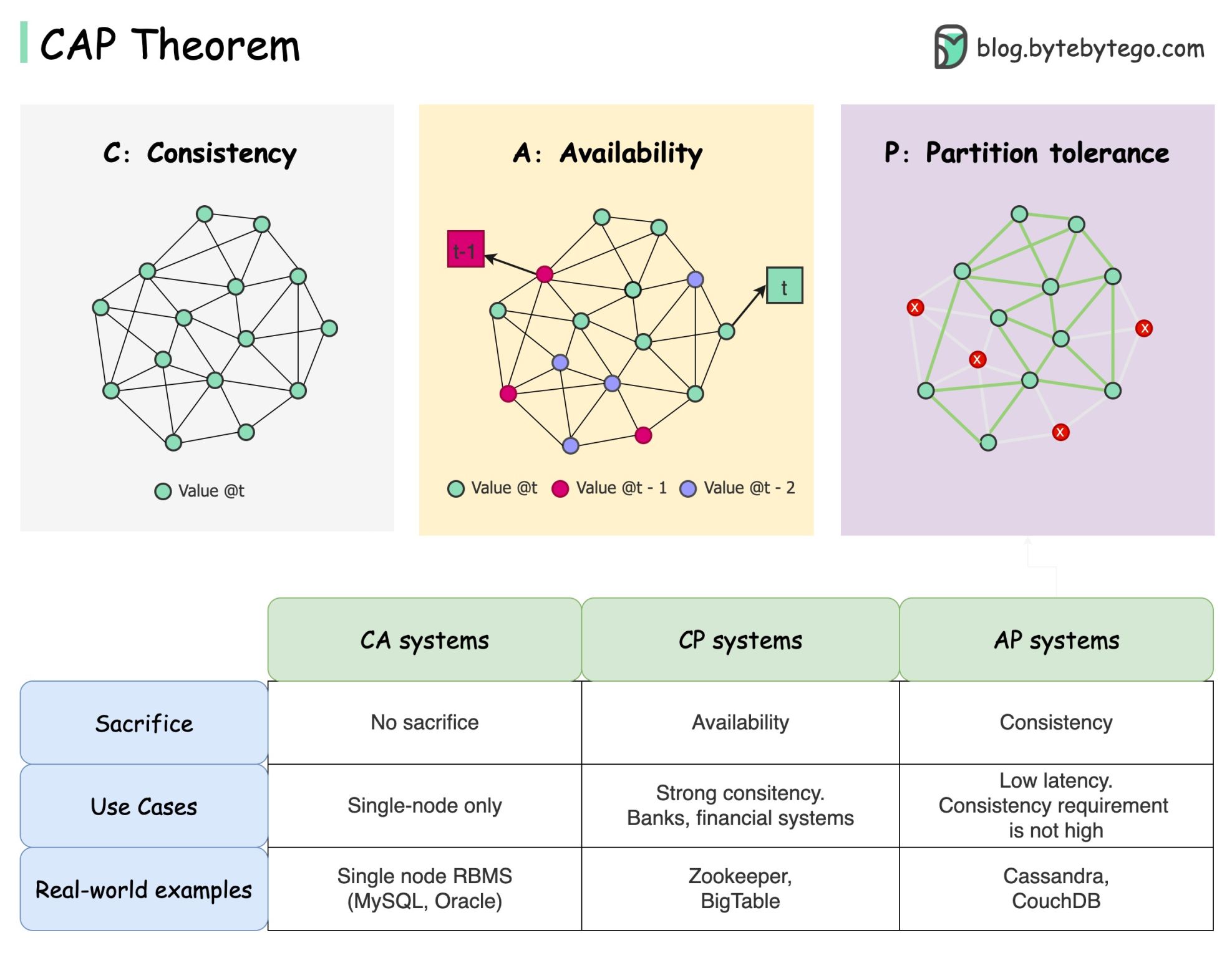
CAP 定理では、分散システムはこれら 3 つの保証のうち 2 つ以上を同時に提供できないと述べています。
一貫性: 一貫性とは、どのノードに接続しても、すべてのクライアントが同時に同じデータを参照できることを意味します。
可用性: 可用性とは、一部のノードがダウンしている場合でも、データを要求したクライアントが応答を受け取ることを意味します。
パーティション許容値: パーティションは 2 つのノード間の通信の中断を示します。パーティション耐性とは、ネットワークが分割されてもシステムが動作し続けることを意味します。
「2 of 3」の定式化は便利ですが、この単純化は誤解を招く可能性があります。
データベースを選択するのは簡単ではありません。純粋に CAP 定理に基づいて私たちの選択を正当化するだけでは十分ではありません。たとえば、企業は、AP システムであるという理由だけで、チャット アプリケーションに Cassandra を選択するわけではありません。 Cassandra がチャット メッセージを保存するための望ましいオプションとなる優れた特性のリストがあります。さらに深く掘り下げる必要があります。
「CAP が禁止するのは設計空間のごく一部だけです。パーティションが存在する場合でも完全な可用性と一貫性が確保されますが、これはまれです。」論文からの引用: CAP 12 年後: 「ルール」はどのように変化したか。
定理は、約 100% の可用性と一貫性です。より現実的な議論は、ネットワーク分割がない場合の遅延と一貫性の間のトレードオフになります。詳細については、PACELC の定理を参照してください。
CAP定理は実際に役に立つのでしょうか?
一連のトレードオフの議論に私たちの心を開くので、これは今でも役に立つと思いますが、それは話の一部にすぎません。適切なデータベースを選択するときは、さらに深く掘り下げる必要があります。
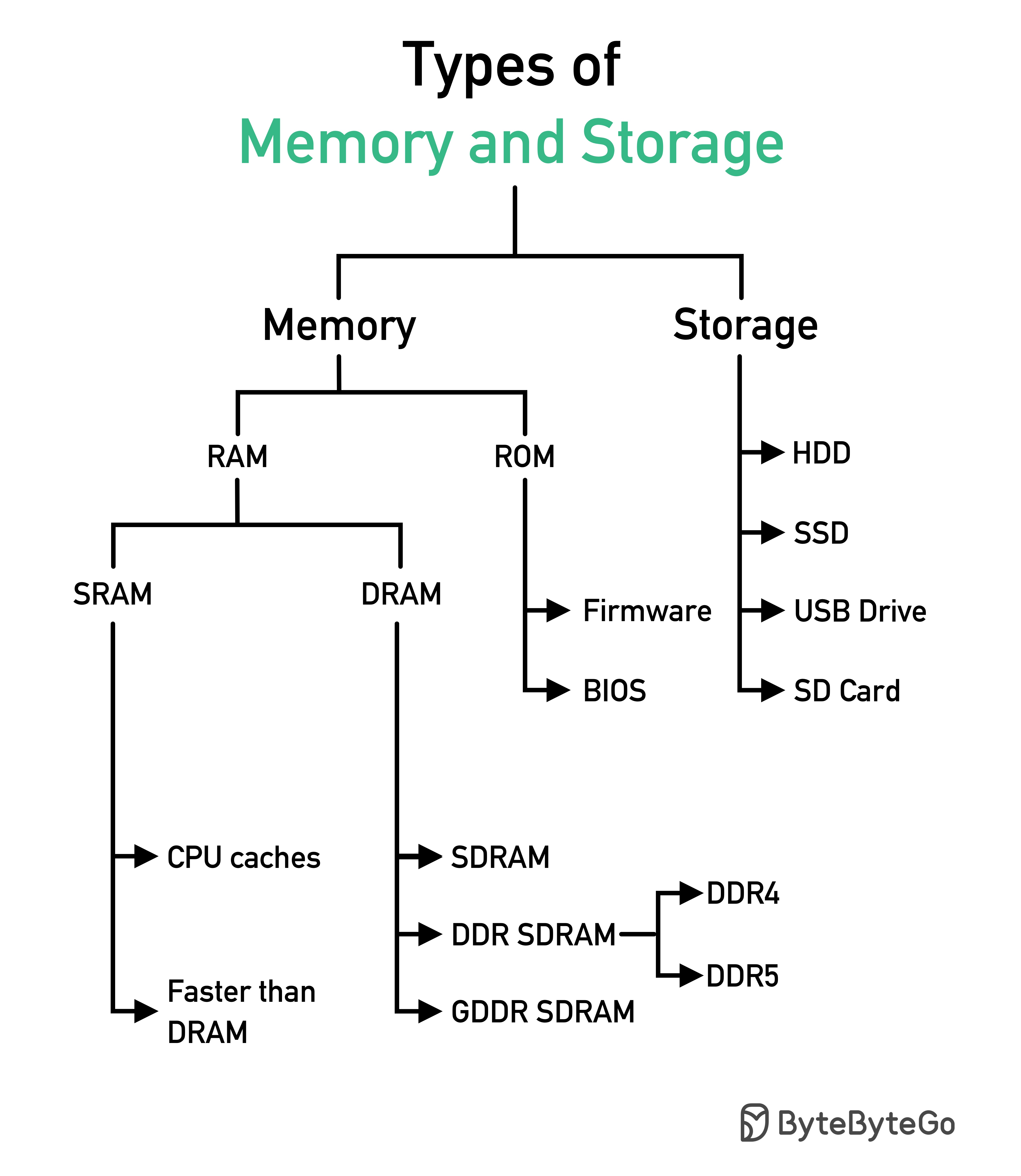
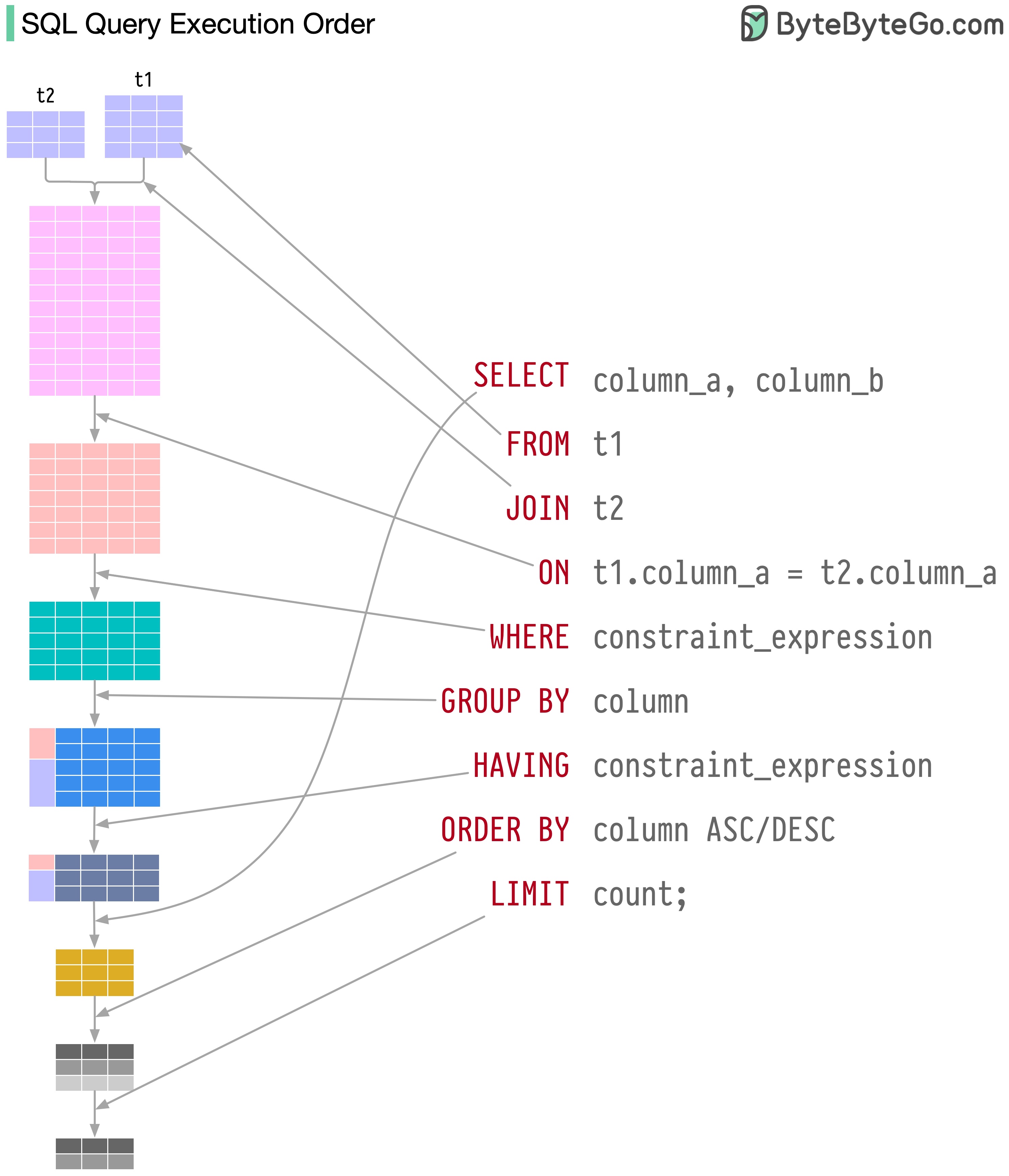
SQL ステートメントは、データベース システムによって次のようないくつかの手順で実行されます。
SQL の実行は非常に複雑であり、次のような多くの考慮事項が必要になります。
1986 年に SQL (構造化照会言語) が標準になりました。その後 40 年間にわたり、この言語はリレーショナル データベース管理システムの主流の言語となりました。最新の規格 (ANSI SQL 2016) を読むには時間がかかる場合があります。どうすれば学べますか?
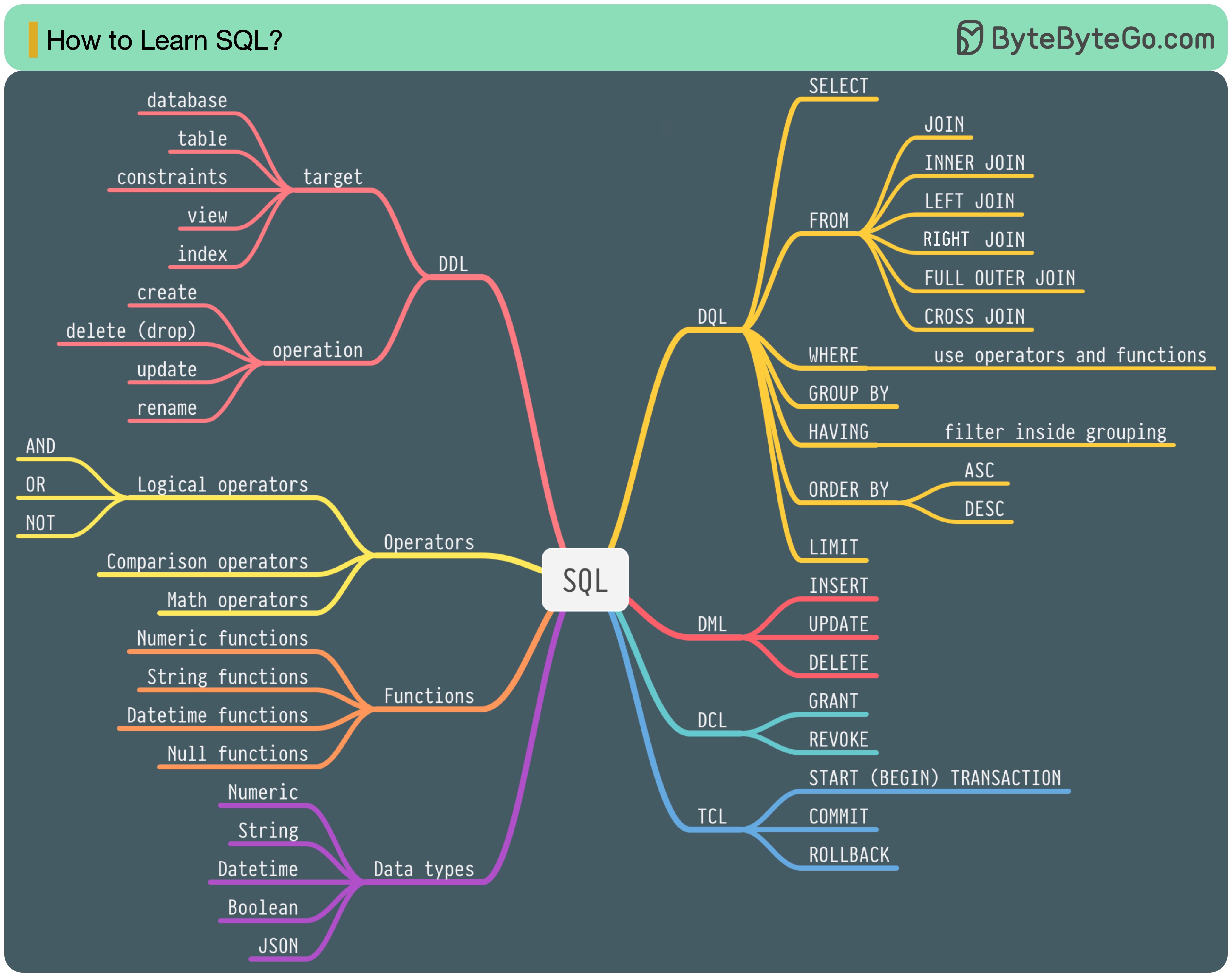
SQL 言語には 5 つのコンポーネントがあります。
バックエンドエンジニアの場合、そのほとんどを知っておく必要があるかもしれません。データ アナリストは、DQL についてよく理解する必要があるかもしれません。最も関連性の高いトピックを選択してください。
この図は、一般的なアーキテクチャでデータをキャッシュする場所を示しています。
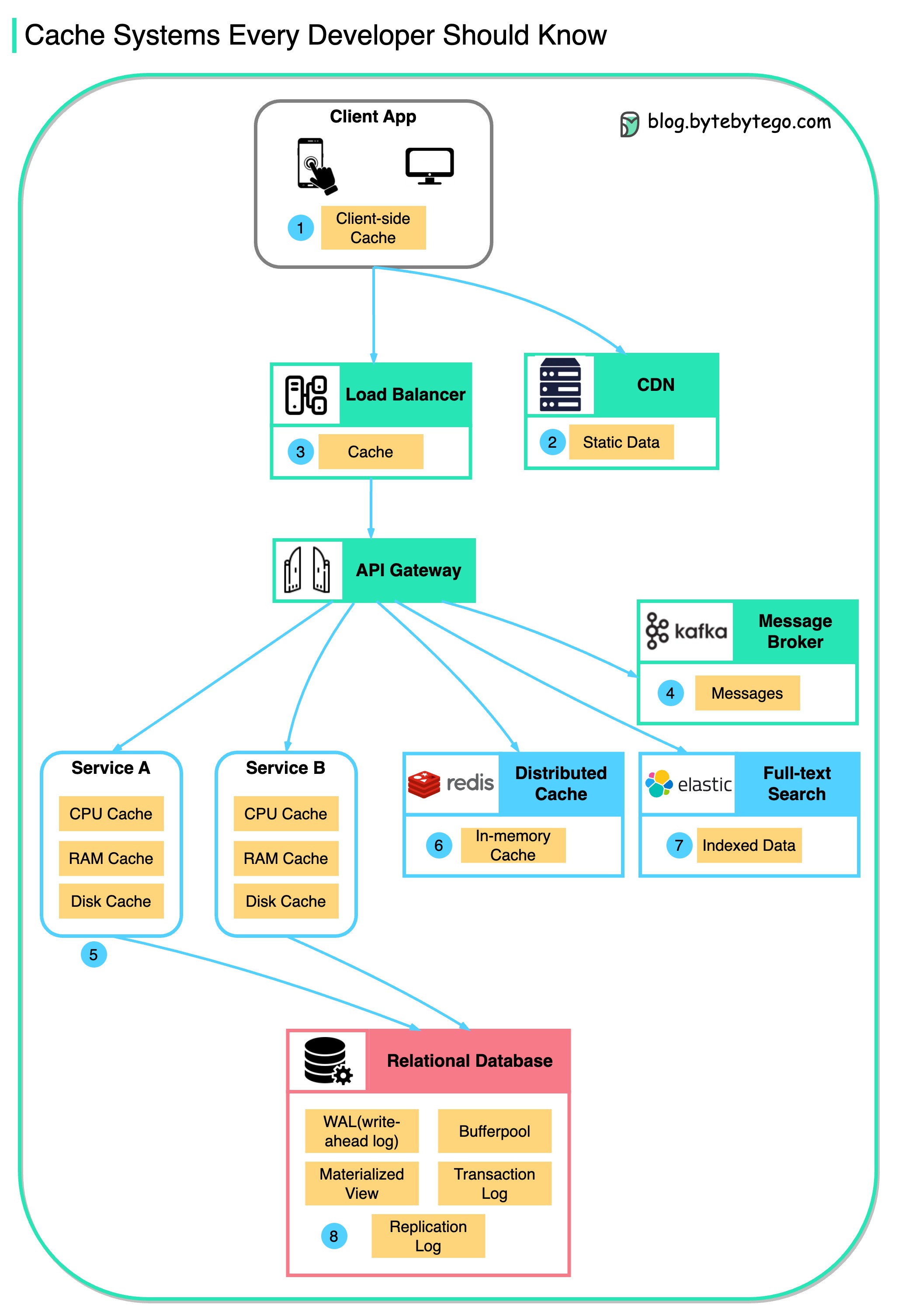
流れに沿って複数の層があります。
その理由は下図のように主に3つあります。
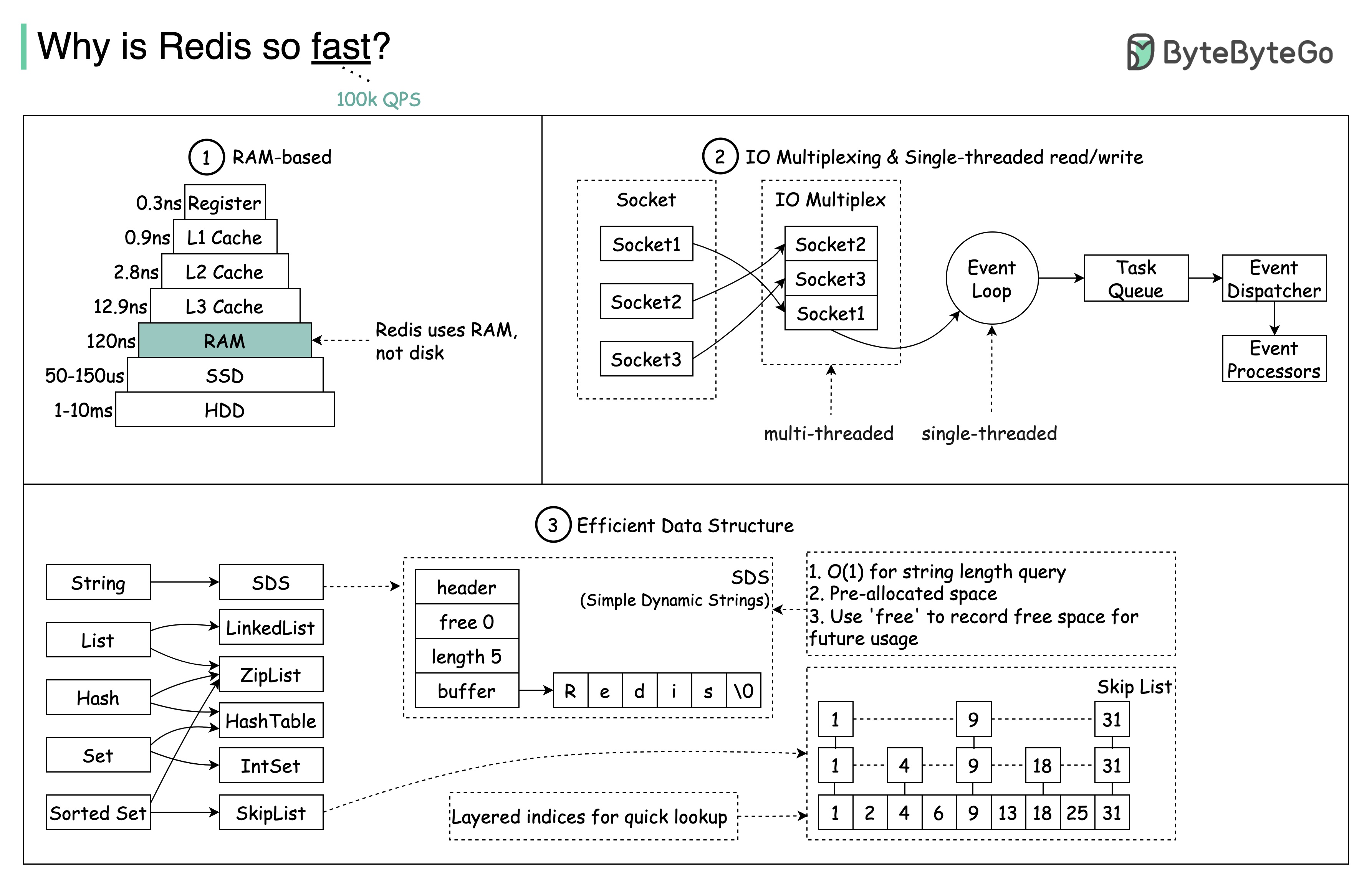
質問: もう 1 つの人気のあるメモリ内ストアは Memcached です。 Redis と Memcached の違いをご存知ですか?
この図のスタイルが私の以前の投稿とは異なることに気付いたかもしれません。どちらが好みか教えてください。
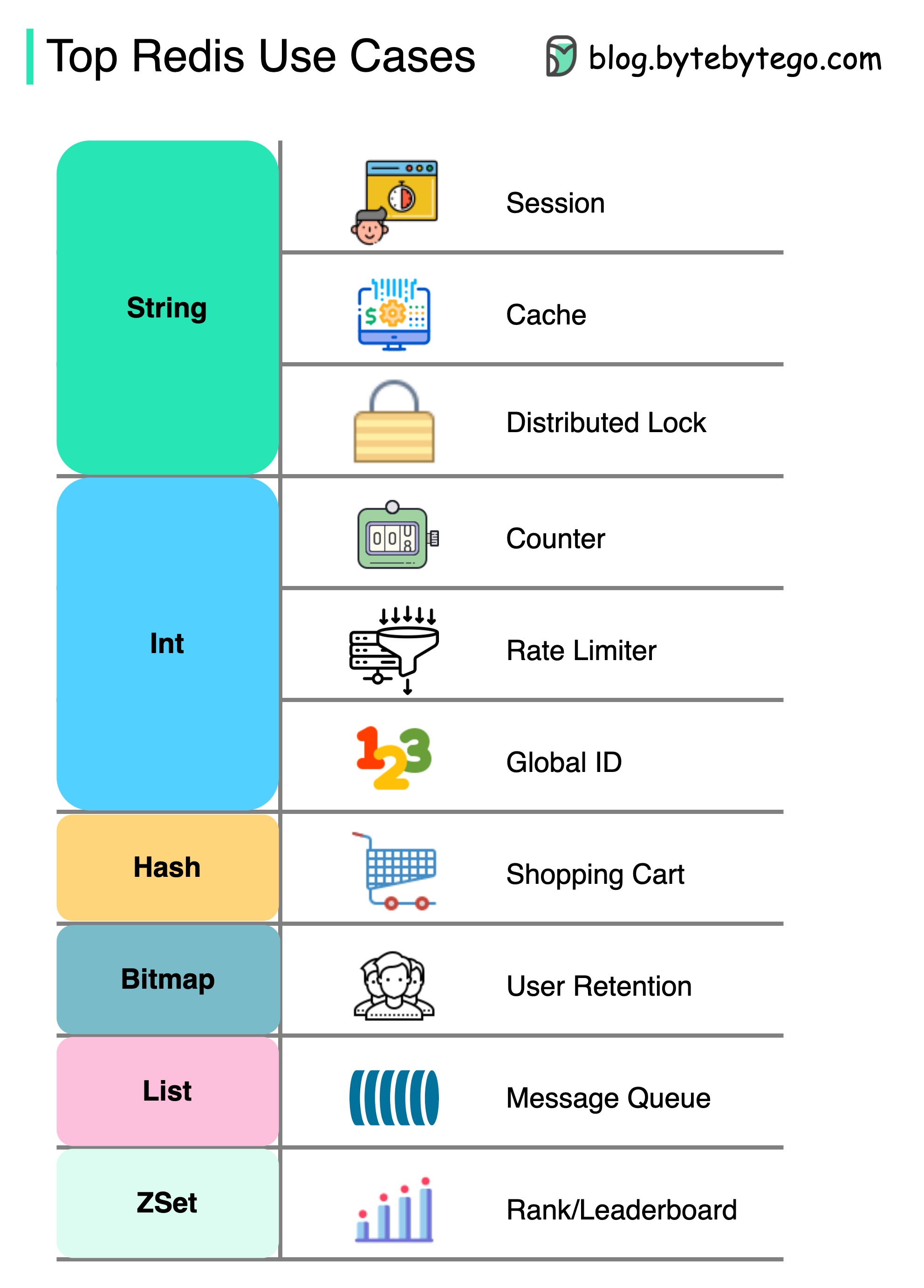
キャッシングだけでなく、Redisには多くのことがあります。
Redisは、図に示すように、さまざまなシナリオで使用できます。
セッション
Redisを使用して、さまざまなサービス間でユーザーセッションデータを共有できます。
キャッシュ
Redisを使用して、特にホットスポットデータに対してオブジェクトまたはページをキャッシュできます。
分散ロック
Redis文字列を使用して、分散サービス間でロックを取得できます。
カウンタ
記事のいいねまたは読み取りの数を数えることができます。
リミッターをレートします
特定のユーザーIPSにレートリミッターを適用できます。
グローバルIDジェネレーター
Global IDにRedis Intを使用できます。
ショッピングカート
Redis Hashを使用して、ショッピングカートのキー価値ペアを表すことができます。
ユーザー保持を計算します
ビットマップを使用して、ユーザーログインを毎日表し、ユーザーの保持を計算できます。
メッセージキュー
メッセージキューにリストを使用できます。
ランキング
Zsetを使用して記事を並べ替えることができます。
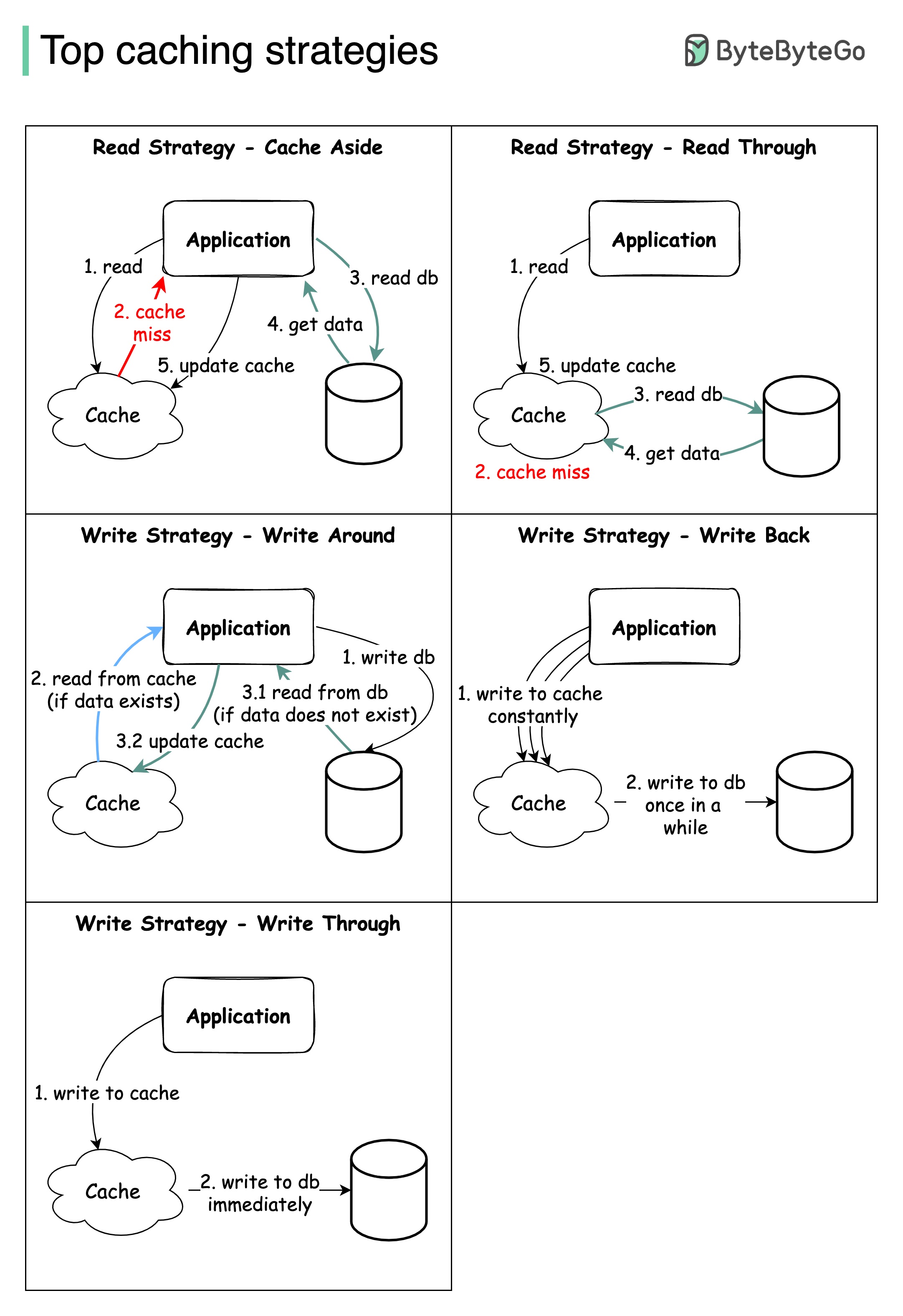
大規模システムの設計には、通常、キャッシュを慎重に検討する必要があります。以下は、頻繁に利用される5つのキャッシュ戦略です。
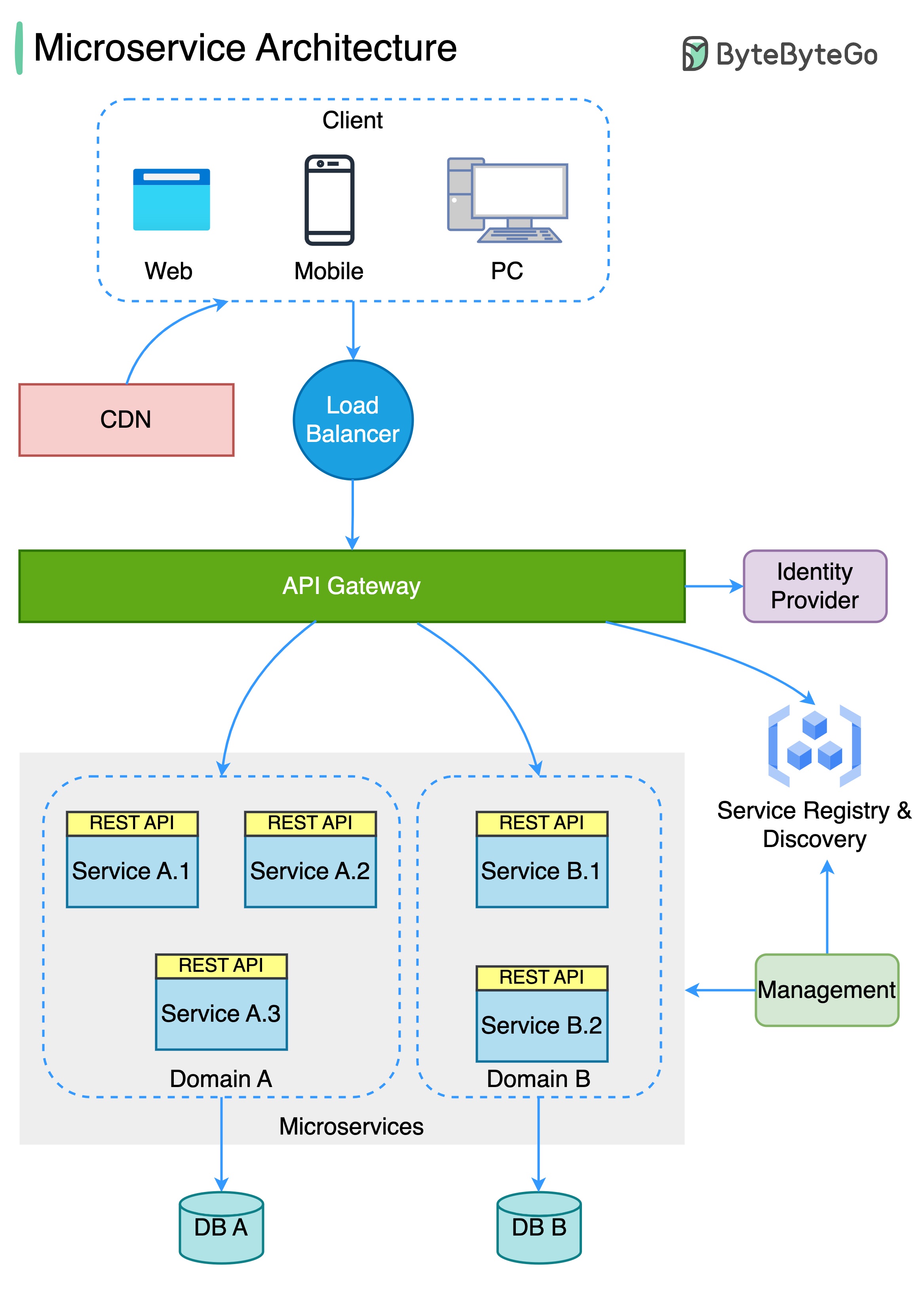
以下の図は、典型的なマイクロサービスアーキテクチャを示しています。
マイクロサービスの利点:
写真は千の言葉の価値があります:マイクロサービスを開発するための9のベストプラクティス。
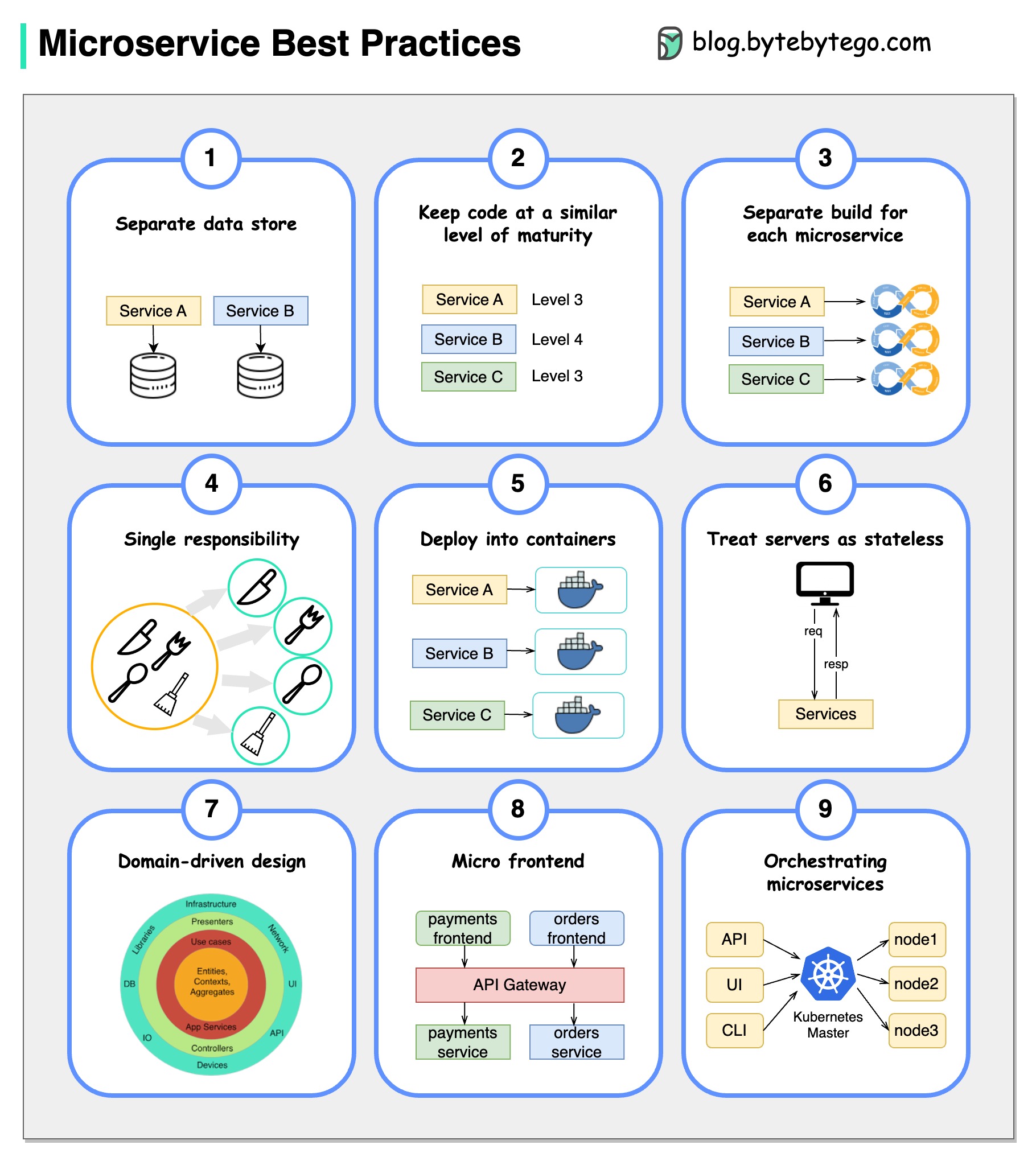
マイクロサービスを開発するときは、次のベストプラクティスに従う必要があります。
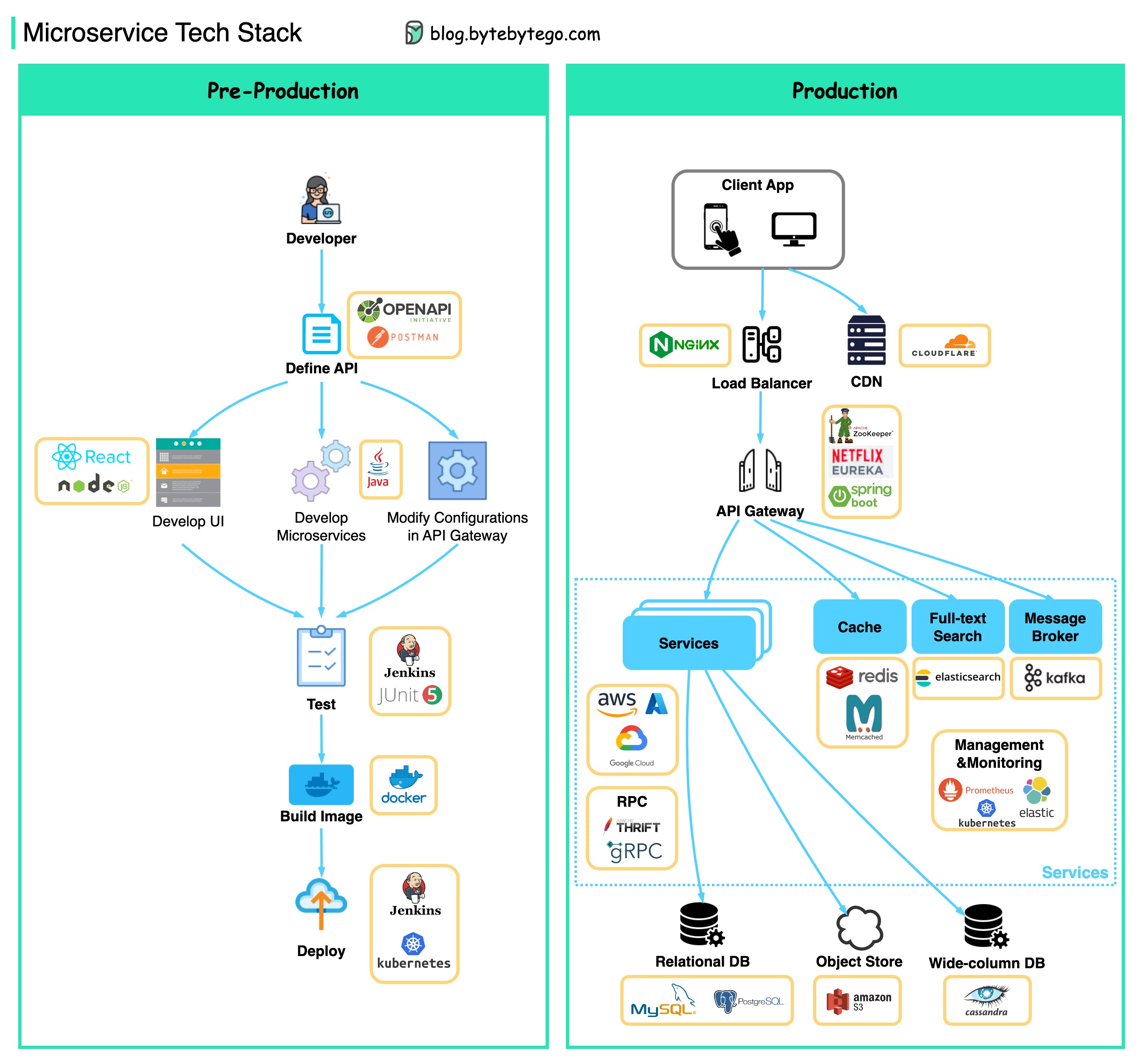
以下に、開発段階と生産用の両方のマイクロサービス技術スタックを示す図を示します。
Kafkaのパフォーマンスに貢献した多くの設計上の決定があります。この投稿では、2つに焦点を当てます。これら2つは最も重みを持っていると思います。
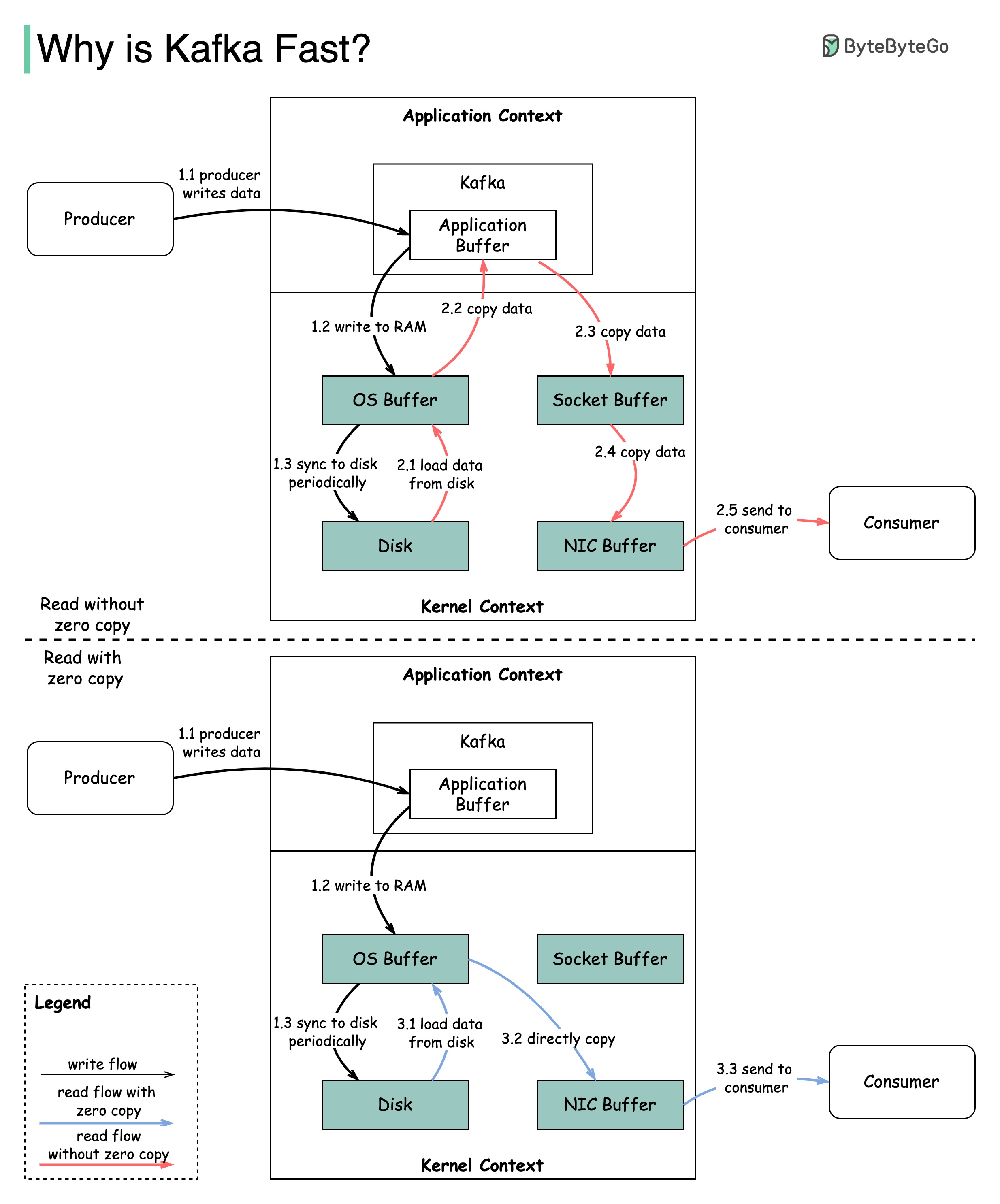
この図は、生産者と消費者の間にデータがどのように送信されるか、ゼロコピーの意味を示しています。
2.1データはディスクからOSキャッシュにロードされます
2.2データはOSキャッシュからKafkaアプリケーションにコピーされます
2.3 Kafkaアプリケーションはデータをソケットバッファーにコピーします
2.4データはソケットバッファーからネットワークカードにコピーされます
2.5ネットワークカードは消費者にデータを送信します
3.1:データがディスクからOSキャッシュからロードされます3.2 OSキャッシュは、sendfile()コマンドを介してネットワークカードにデータを直接コピーします3.3ネットワークカードは消費者にデータを送信します
Zero Copyは、アプリケーションコンテキストとカーネルコンテキストの間に複数のデータコピーを保存するためのショートカットです。
以下の図は、クレジットカードの支払いフローの経済性を示しています。
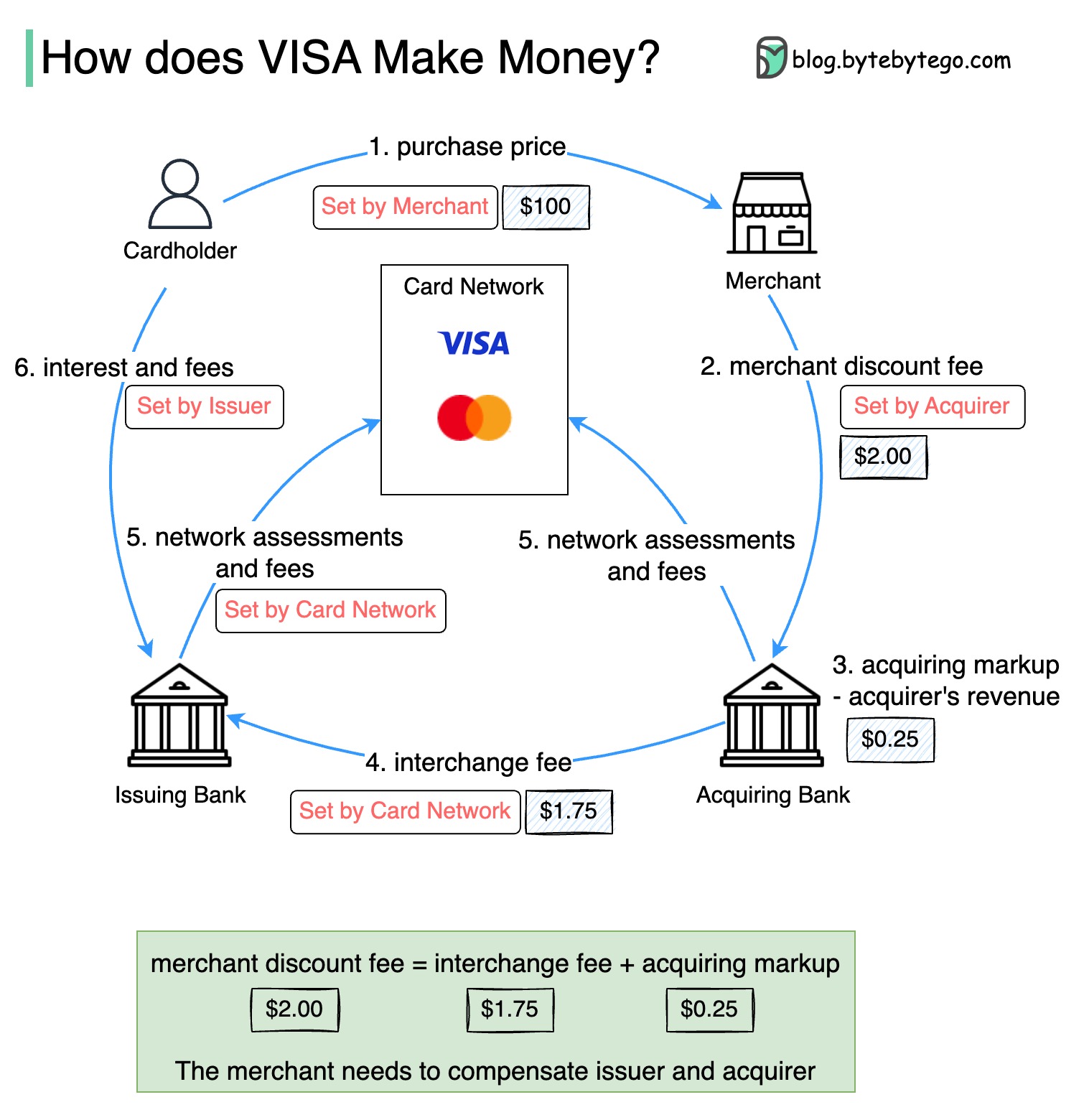
1.カード所有者は、商人に100ドルを支払い、製品を購入します。
2。販売量が多いクレジットカードを使用することで商人は恩恵を受け、支払いサービスを提供するために発行者とカードネットワークを補償する必要があります。買収銀行は、「商人割引料金」と呼ばれる商人に料金を設定します。
3-4。買収銀行は、取得マークアップとして0.25ドルを維持し、1.75ドルがインターチェンジ料金として発行銀行に支払われます。マーチャント割引料金は、交換料金をカバーする必要があります。
インターチェンジ料金は、各販売者との料金を交渉するために各発行銀行が効率が低いため、カードネットワークによって設定されます。
5.カードネットワークは、各銀行にネットワークの評価と料金を設定します。これは、毎月サービスにカードネットワークを支払うものです。たとえば、Visaは0.11%の評価に加えて、スワイプごとに0.0195ドルの使用料を請求します。
6.カード所有者は、発行銀行にサービスのために支払います。
発行銀行を補償する必要があるのはなぜですか?
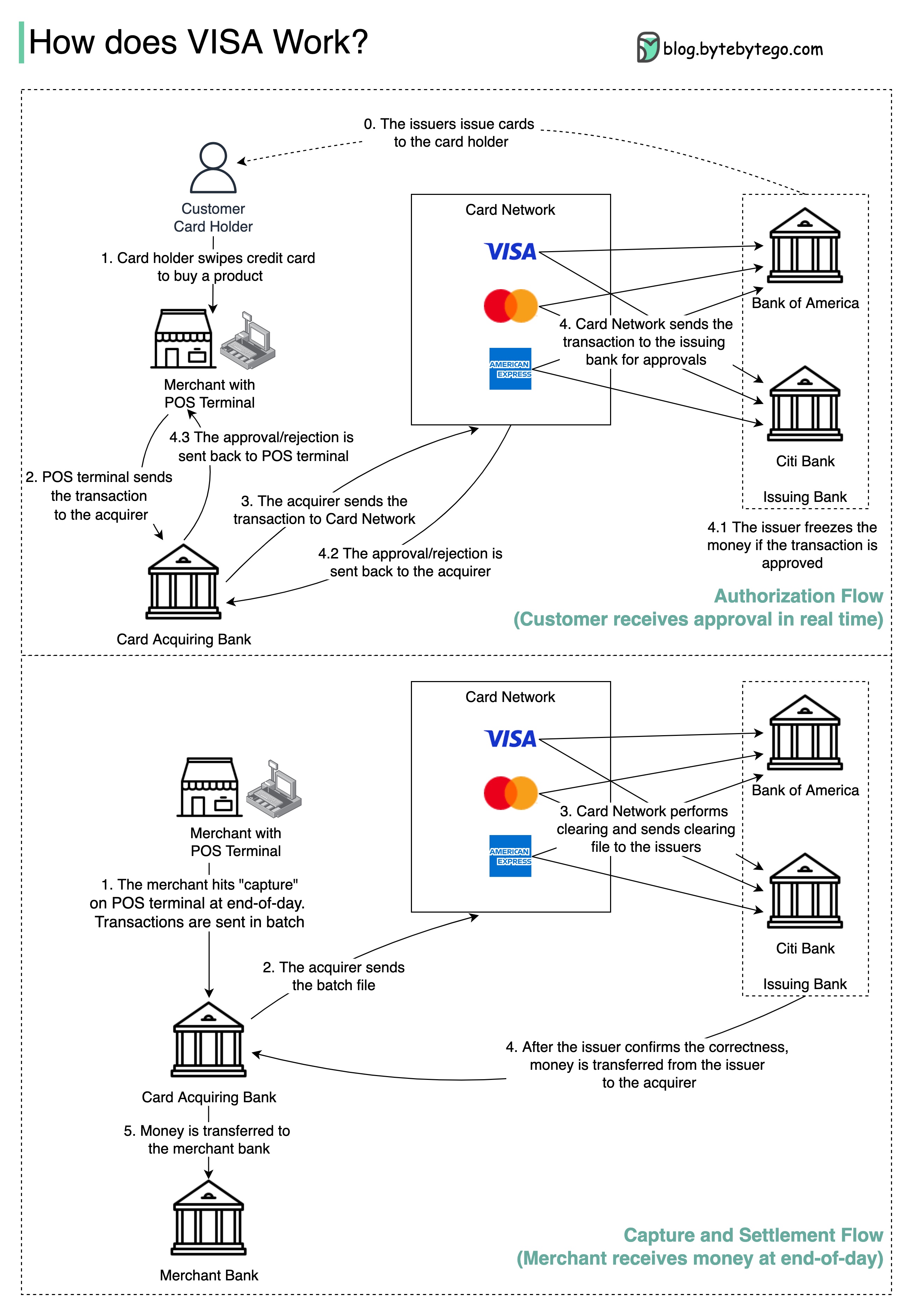
Visa、MasterCard、およびAmerican Expressは、資金の清算と決済のためのカードネットワークとして機能します。銀行を買収するカードとカード発行銀行は、違うことがあります。銀行が仲介者なしで取引を1つずつ解決する場合、各銀行は他のすべての銀行と取引を解決する必要があります。これは非常に非効率的です。
以下の図は、クレジットカードの支払いプロセスにおけるVisaの役割を示しています。 2つのフローが関係しています。承認のフローは、顧客がクレジットカードをスワイプすると発生します。キャプチャと決済の流れは、商人が一日の終わりにお金を手に入れたいときに起こります。
ステップ0:銀行を発行するカードは、顧客にクレジットカードを発行します。
ステップ1:カード所有者は製品を購入し、商人の店の販売時点(POS)ターミナルでクレジットカードをスワイプしたいと考えています。
ステップ2:POSターミナルは、取引を取得銀行に送信し、POSターミナルを提供しました。
ステップ3および4:取得銀行は、カードスキームとも呼ばれるカードネットワークにトランザクションを送信します。カードネットワークは、承認のために取引を発行銀行に送信します。
手順4.1、4.2、および4.3:取引が承認された場合、発行銀行はお金を凍結します。承認または拒否は、POS端末だけでなく、取得者に送り返されます。
ステップ1と2:商人は、1日の終わりにお金を集めたいので、POSターミナルで「Capture」を打ちました。トランザクションは、バッチの取得者に送信されます。取得者は、トランザクションを備えたバッチファイルをカードネットワークに送信します。
ステップ3:カードネットワークは、異なる取得者から収集されたトランザクションのクリアを実行し、異なる発行銀行にクリアリングファイルを送信します。
ステップ4:発行銀行は、クリアリングファイルの正しさを確認し、関連する買収銀行に送金します。
ステップ5:その後、買収銀行は商人の銀行にお金を譲渡します。
ステップ4:カードネットワークは、さまざまな買収銀行からの取引をクリアします。クリアリングは、相互のオフセットトランザクションがネットになるプロセスであるため、総トランザクションの数が減少します。
その過程で、カードネットワークは各銀行との会話の負担を引き受け、見返りにサービス料を受け取ります。
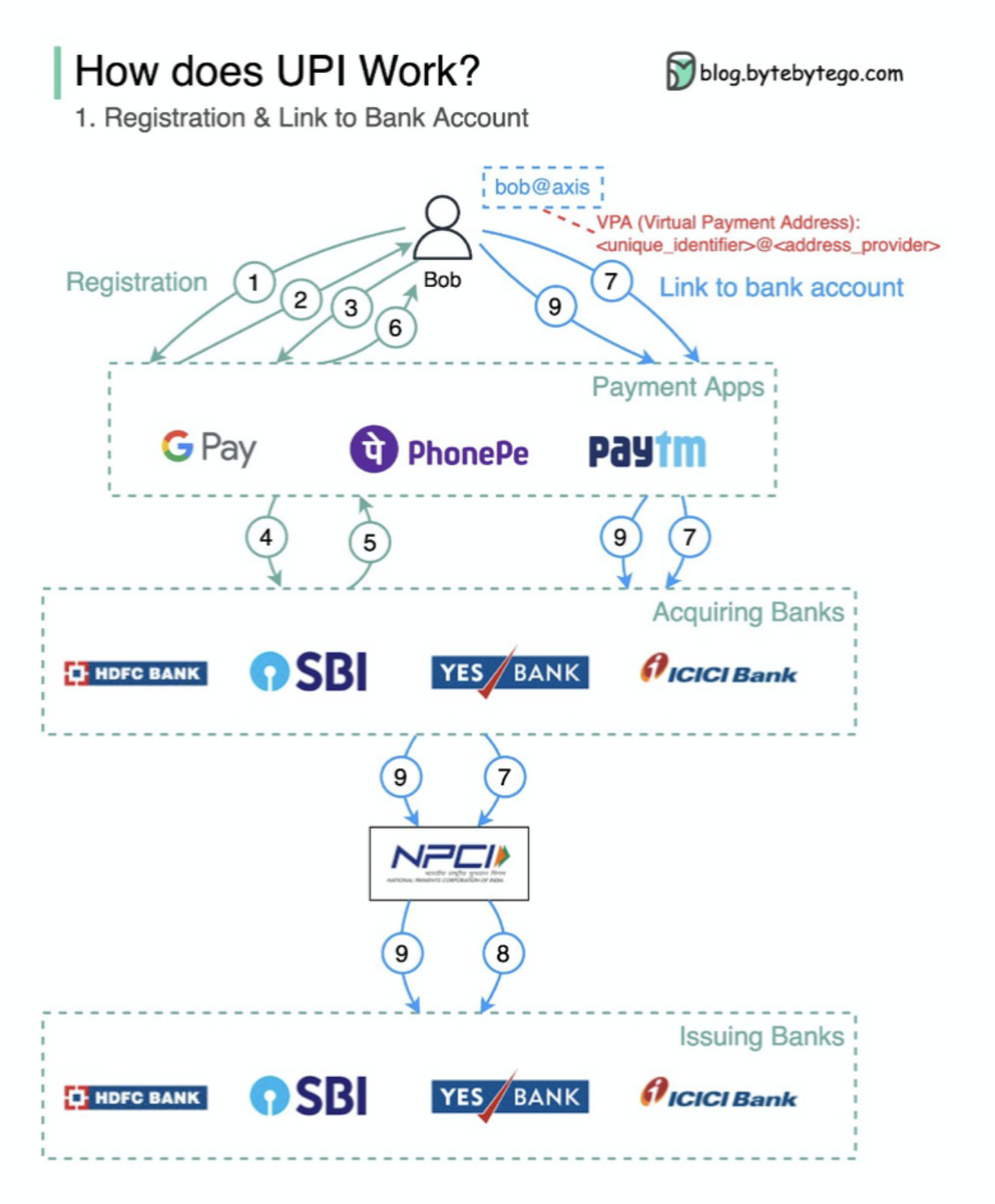
upiとは何ですか? UPIは、インド国立支払い公社によって開発された即座のリアルタイム支払いシステムです。
今日のインドでのデジタル小売取引の60%を占めています。
upi =支払いマークアップ言語 +相互運用可能な支払いの標準
DevOps、SRE、およびプラットフォームエンジニアリングの概念は、さまざまな時期に登場し、さまざまな個人や組織によって開発されてきました。
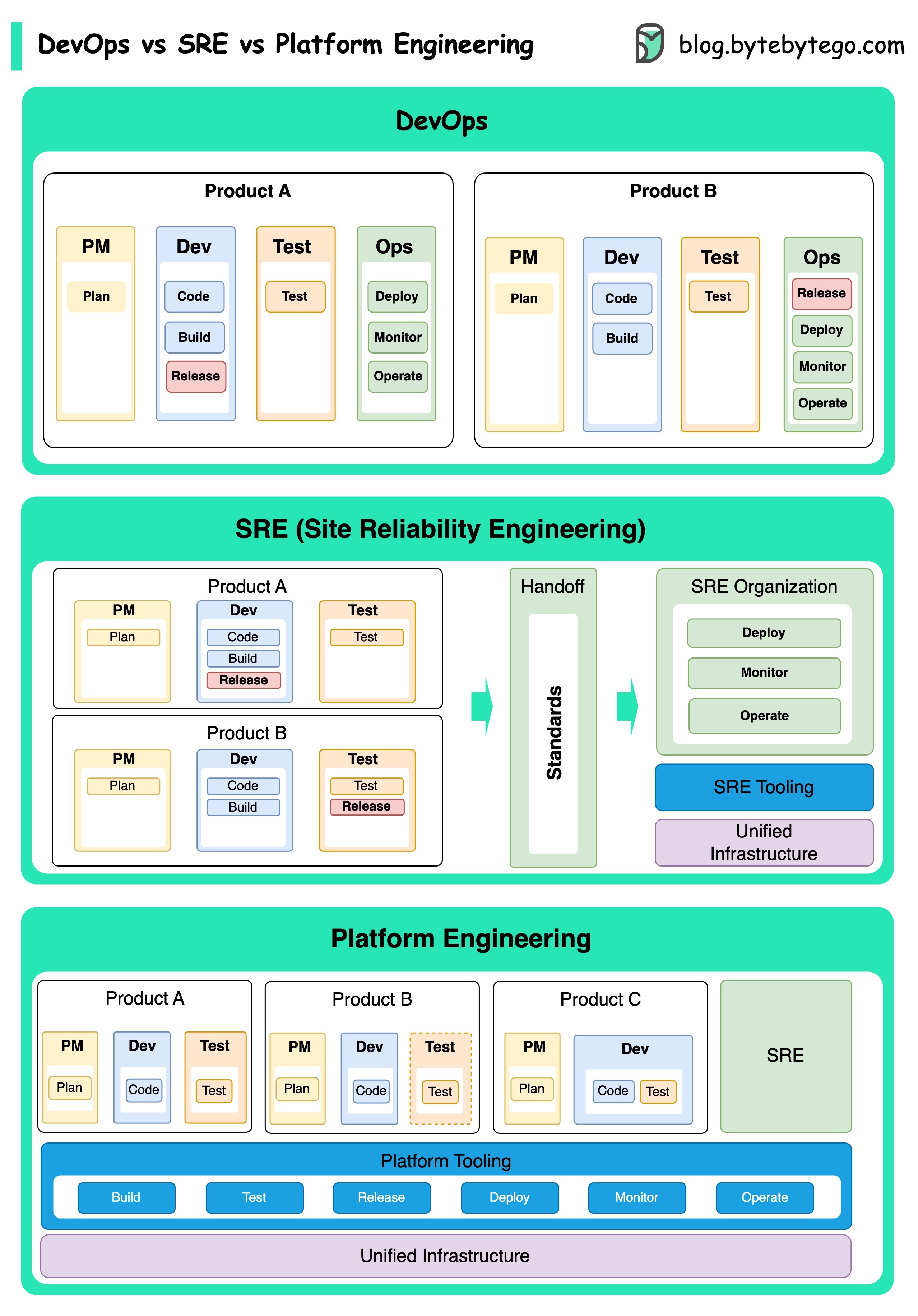
DevOpsとしてのDevOpsは、2009年にAgile ConferenceでPatrick DeboisとAndrew Shaferによって紹介されました。彼らは、共同文化を促進し、ソフトウェア開発ライフサイクル全体に対する責任を共有することにより、ソフトウェア開発と運用のギャップを埋めようとしました。
SRE、またはサイトの信頼性エンジニアリングは、2000年代初頭にGoogleによって開拓され、大規模で複雑なシステムの管理における運用上の課題に対処しました。 Googleは、サービスの信頼性と効率を向上させるために、Borgクラスター管理システムやMonarch Monitoring SystemなどのSREプラクティスとツールを開発しました。
プラットフォームエンジニアリングは、より最近のコンセプトであり、SREエンジニアリングの基礎に基づいています。プラットフォームエンジニアリングの正確な起源はそれほど明確ではありませんが、一般的にDevOpsとSREプラクティスの拡張であると理解されており、ビジネス全体をサポートする製品開発のための包括的なプラットフォームを提供することに焦点を当てています。
これらの概念はさまざまな時期に現れましたが、注目に値します。これらはすべて、ソフトウェアの開発と運用のコラボレーション、自動化、効率を改善するより広範な傾向に関連しています。
K8Sはコンテナオーケストレーションシステムです。コンテナの展開と管理に使用されます。その設計は、Googleの内部システムBorgの影響を大きく影響します。
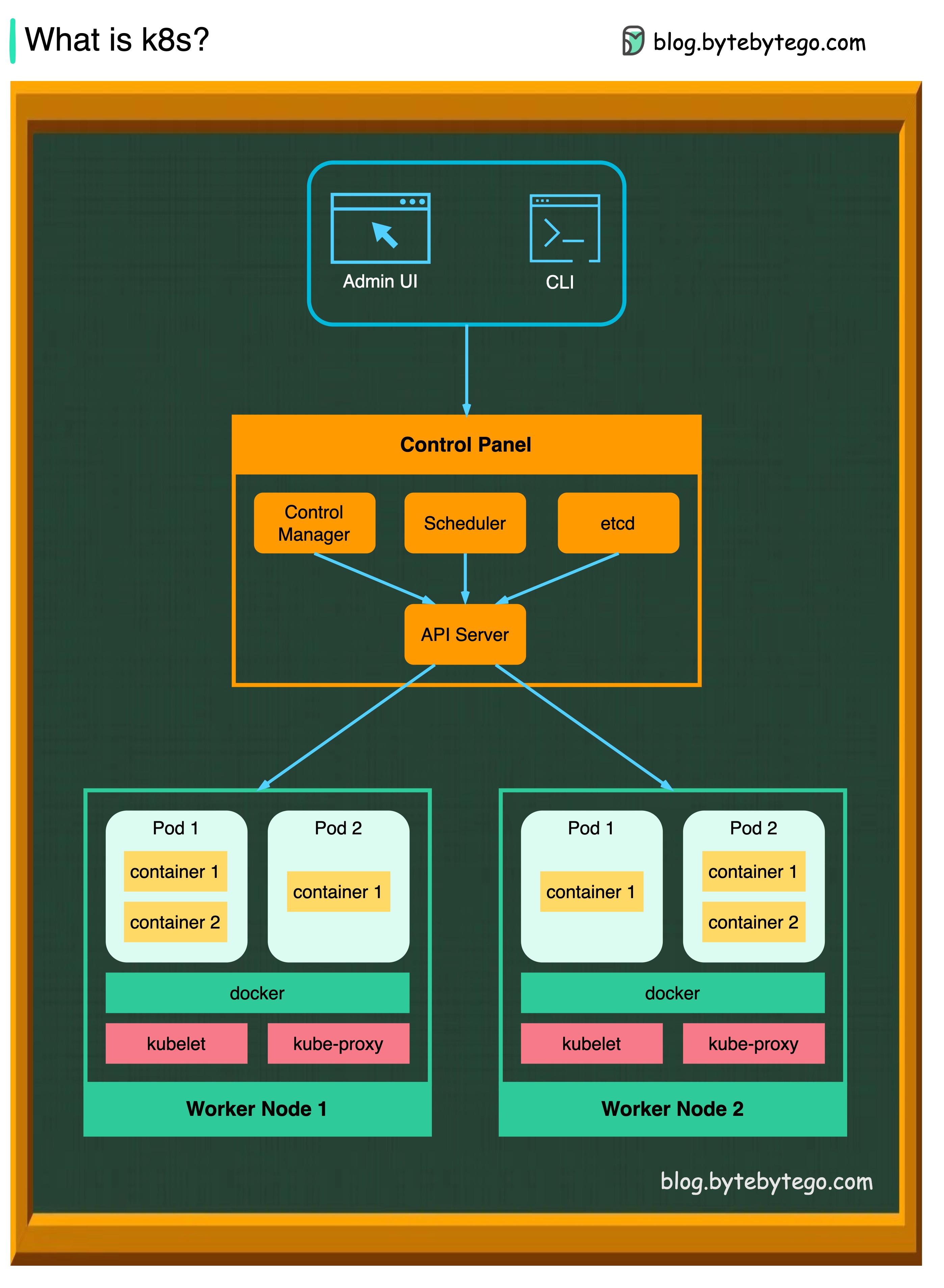
K8Sクラスターは、コンテナ化されたアプリケーションを実行するノードと呼ばれるワーカーマシンのセットで構成されています。すべてのクラスターには、少なくとも1人のワーカーノードがあります。
ワーカーノードは、アプリケーションワークロードのコンポーネントであるポッドをホストします。コントロールプレーンは、クラスター内のワーカーノードとポッドを管理します。生産環境では、コントロールプレーンは通常複数のコンピューターを走り、クラスターは通常複数のノードを実行し、断層許容度と高可用性を提供します。
APIサーバー
APIサーバーは、K8Sクラスター内のすべてのコンポーネントについて説明します。 PODのすべての操作は、APIサーバーと通信することにより実行されます。
スケジューラ
スケジューラは、ポッドワークロードを監視し、新しく作成したポッドにロードを割り当てます。
コントローラーマネージャー
コントローラーマネージャーは、ノードコントローラー、ジョブコントローラー、エンドポイントスライスコントローラー、およびサービシーカウントコントローラーなどのコントローラーを実行します。
など
etcdは、すべてのクラスターデータのKubernetesのバッキングストアとして使用されるキー価値ストアです。
ポッド
ポッドはコンテナのグループであり、K8Sが管理する最小のユニットです。ポッドには、ポッド内のすべてのコンテナに単一のIPアドレスが適用されています。
kubelet
クラスター内の各ノードで実行されるエージェント。コンテナがポッドで稼働していることを保証します。
Kube Proxy
Kube-Proxyは、クラスター内の各ノードで実行されるネットワークプロキシです。サービスからノードにトラフィックをルーティングします。作業のリクエストを正しい容器に転送します。

Dockerとは何ですか?
Dockerは、孤立したコンテナでアプリケーションをパッケージ化、配布、および実行できるオープンソースプラットフォームです。コンテナ化に焦点を当て、アプリケーションとその依存関係をカプセル化する軽量環境を提供します。
Kubernetesとは何ですか?
Kubernetesは、しばしばK8Sと呼ばれ、オープンソースのコンテナオーケストレーションプラットフォームです。ノードのクラスター全体でコンテナ化されたアプリケーションの展開、スケーリング、および管理を自動化するためのフレームワークを提供します。
どちらも互いにどのように違いますか?
Docker:Dockerは、単一のオペレーティングシステムホストの個々のコンテナレベルで動作します。
各ホストを手動で管理し、複数の関連するコンテナのネットワーク、セキュリティポリシー、およびストレージをセットアップする必要があります。
Kubernetes:Kubernetesはクラスターレベルで動作します。複数のホストで複数のコンテナ化されたアプリケーションを管理し、ロードバランシング、スケーリング、目的のアプリケーションの状態を確保するなどのタスクの自動化を提供します。
要するに、Dockerは個々のホストのコンテナ化とランニングコンテナに焦点を当て、Kubernetesはホストのクラスター全体で規模のコンテナの管理と調整を専門としています。
以下の図は、Dockerのアーキテクチャと、「Docker Build」、「Docker Pull」、「Docker Run」を実行したときの仕組みを示しています。
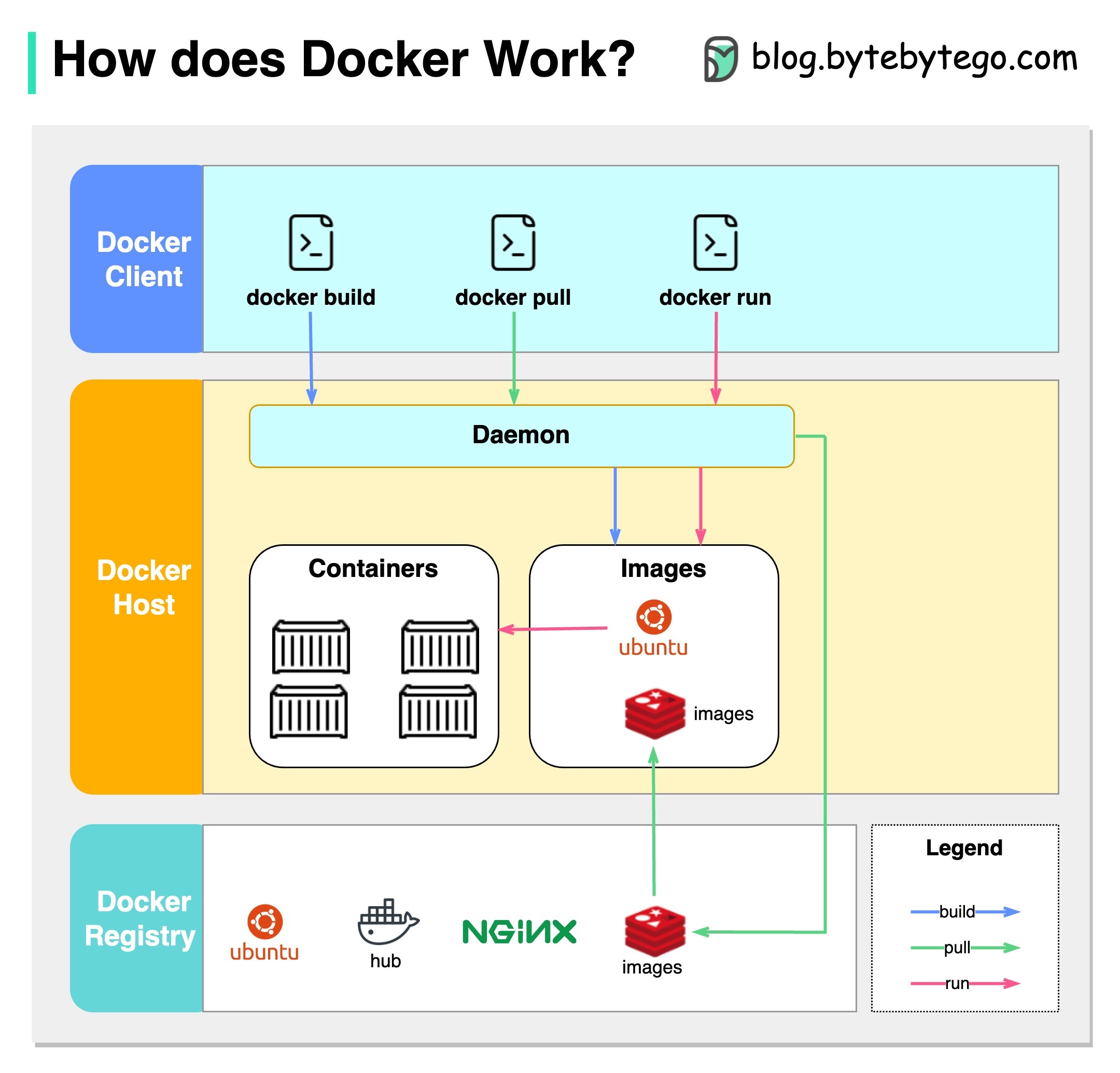
Dockerアーキテクチャには3つのコンポーネントがあります。
Dockerクライアント
DockerクライアントはDockerデーモンと話します。
Dockerホスト
Docker Daemonは、Docker API要求のリッスンを行い、画像、コンテナ、ネットワーク、ボリュームなどのDockerオブジェクトを管理します。
Dockerレジストリ
DockerレジストリはDocker画像を保存します。 Docker Hubは、誰でも使用できる公開レジストリです。
「Docker Run」コマンドを例にとってみましょう。
そもそも、コードが保存されている場所を特定することが不可欠です。一般的な仮定は、GitHubのようなリモートサーバーに、もう1つはローカルマシンに1つだけの場所があるということです。ただし、これは完全に正確ではありません。 GITはマシン上に3つのローカルストレージを維持しています。つまり、コードは4つの場所で見つけることができます。
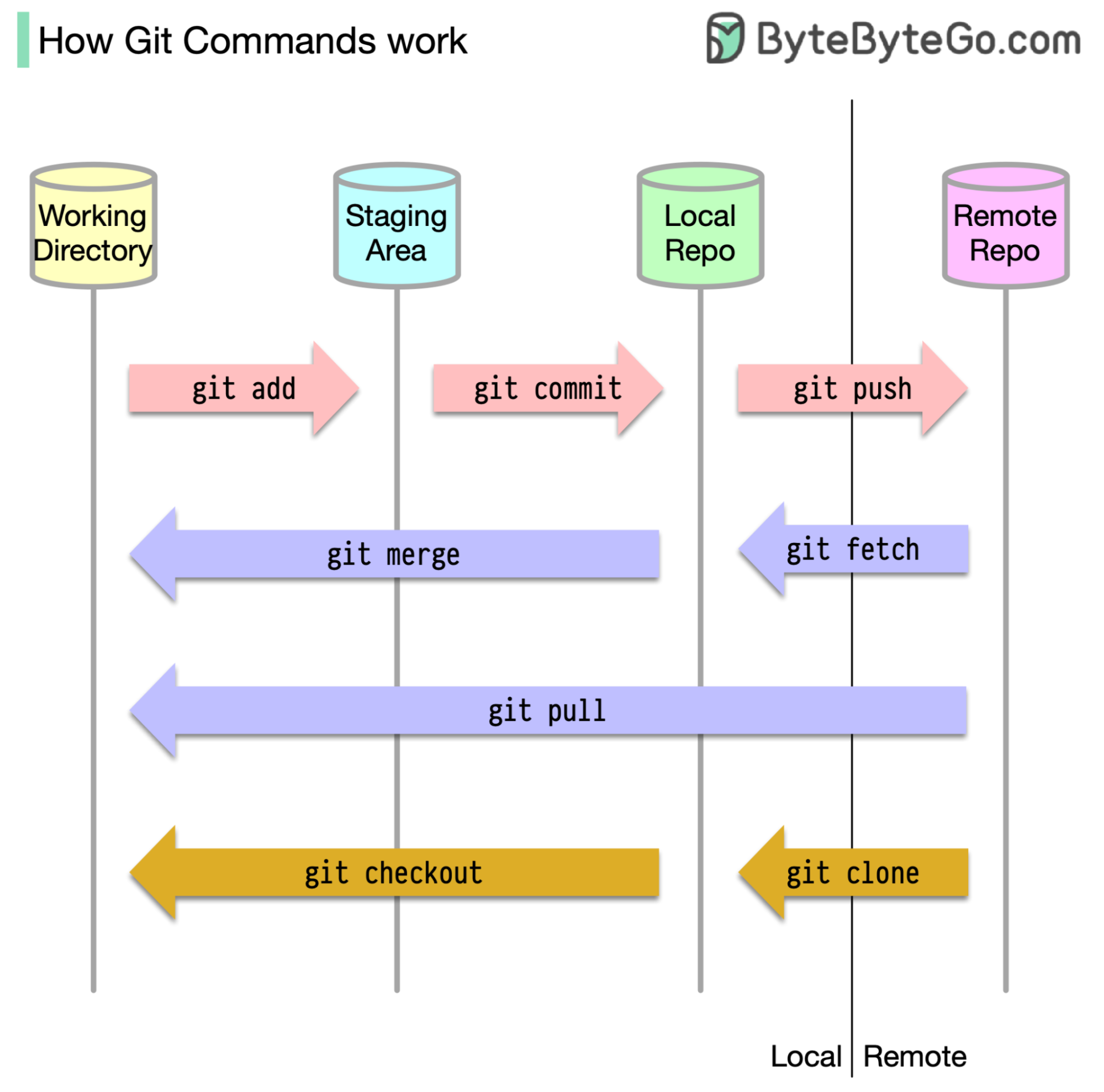
ほとんどのgitコマンドは、主にこれらの4つの場所間でファイルを移動します。
下の図は、Gitワークフローを示しています。
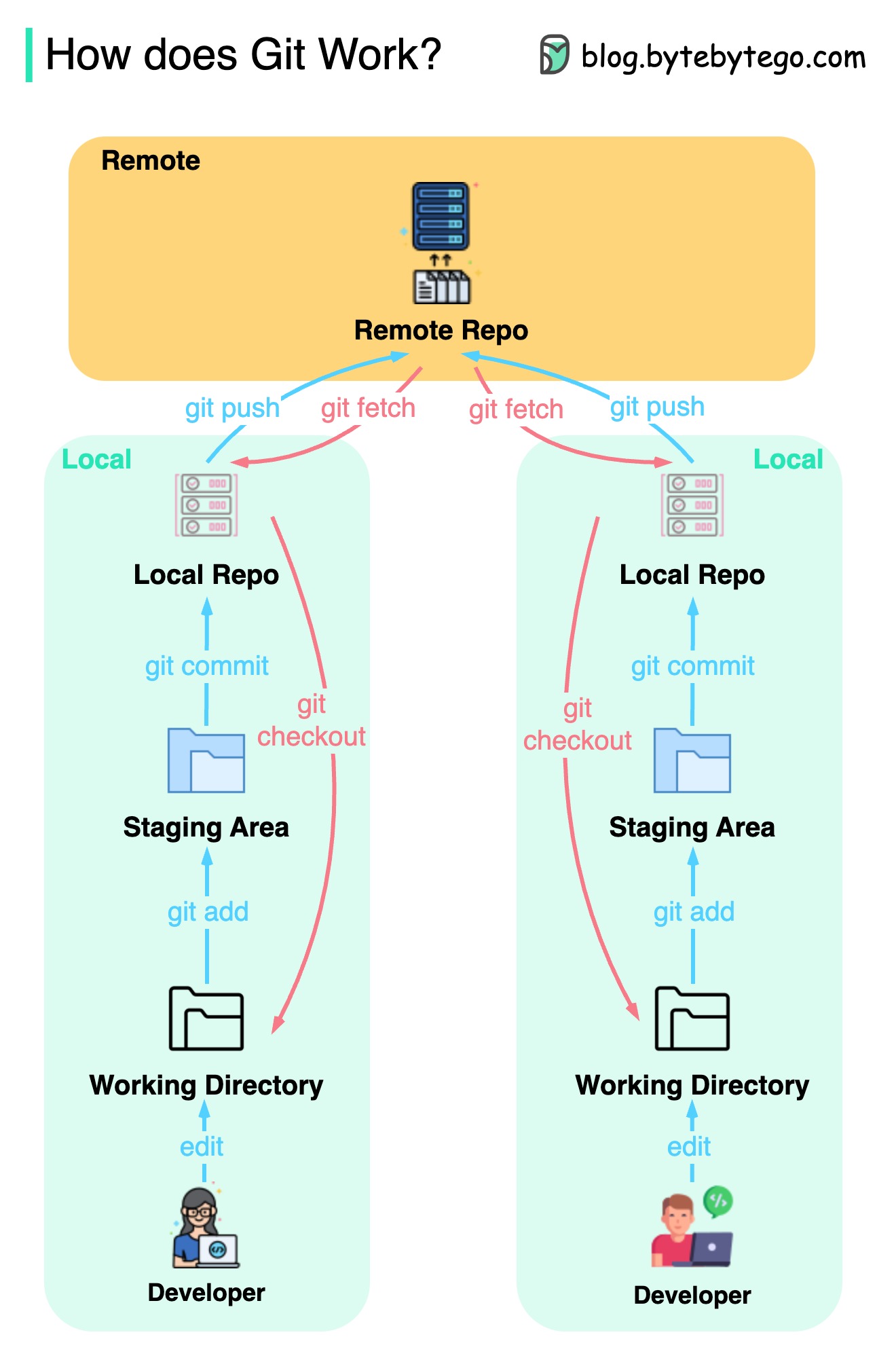
Gitは分散バージョン制御システムです。
すべての開発者は、メインリポジトリのローカルコピーを維持し、ローカルコピーを編集およびコミットします。
操作がリモートリポジトリと相互作用しないため、コミットは非常に高速です。
リモートリポジトリがクラッシュした場合、ファイルはローカルリポジトリから回復できます。
違いは何ですか?


