meme search engine
1.0.0
意味的に検索したいミームの大きなフォルダーがありますか? Nvidia GPU を搭載した Linux サーバーはありますか?あなたがやる;これは現在必須です。
百聞は一見に如かずと言います。残念ながら、多くの (ほとんどの?) 単語セットは、絵では適切に説明できません。それはともかく、ここに写真があります。ここで実行中のインスタンスを使用できます。
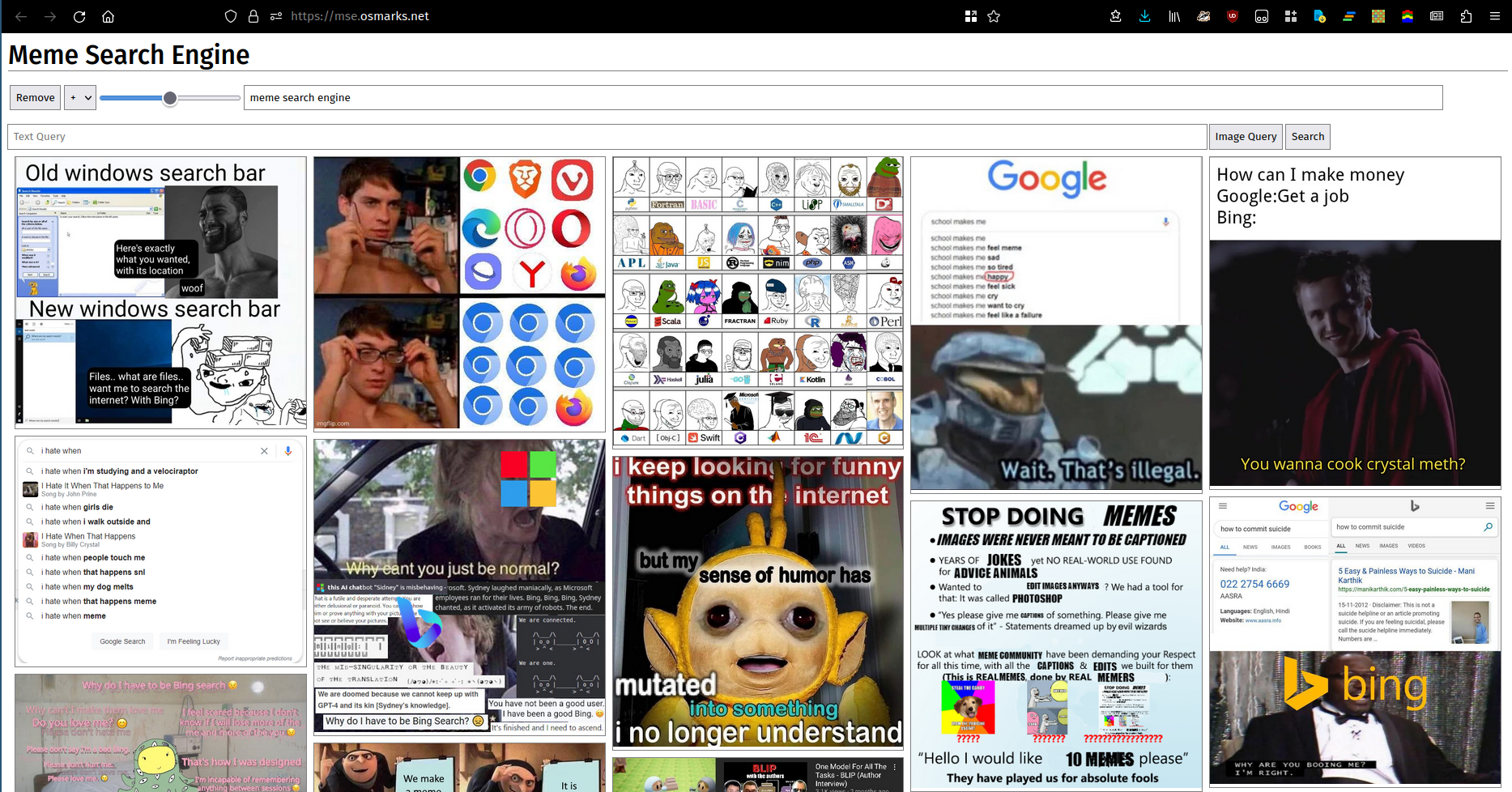
これは未テストです。それはうまくいくかもしれません。新しい Rust バージョンでは、いくつかの手順が簡素化されています (独自のサムネイルが統合されています)。
python -m http.server使用できます。requirements.txtのpipを使用してインストールします (バージョンを変更する必要がある場合、バージョンが正確に一致する必要はおそらくありません。現在インストールしているものをそのまま入力します)。transformersのパッチ適用済みバージョンが必要になります。thumbnailer.pyを実行します (定期的に、理想的にはインデックスのリロードと同時に)clip_server.py実行します。clip_server_config.jsonにあります。deviceおそらくcudaまたはcpuであるはずです。モデルはここで実行されます。modelはmodel_nameメトリクスを目的としたモデルの名前です。max_batch_size許可される最大バッチ サイズを制御します。一般に、値を高くすると、VRAM の使用量が多くなりますが、パフォーマンスが多少向上します (ただし、ほとんどの場合、ボトルネックは現時点では別の場所にあります)。port 、HTTP サーバーを実行するポートです。meme-search-engine (Rust) をビルドして実行します (バックグラウンド サービスとしても)。clip_serverバックエンド サーバーの完全な URL です。db_path 、画像と埋め込みベクトルの SQLite データベースのパスです。files 、meme ファイルの読み取り元です。サブディレクトリにはインデックスが付けられます。port HTTP を提供するポートです。enable_thumbs trueに設定します。npm install 、 node src/build.js 。frontend_config.json編集するたびに再構築する必要があります。image_pathミーム Web サーバーのベース URL (末尾にスラッシュが付きます) です。backend_urlは、 mse.pyが公開されている URL です (末尾のスラッシュはおそらくオプションです)。clip_server.py監視するように Prometheus を構成します。 新しい自動ミーム取得/評価システム ( meme-raterの下) MemeThresher については、こちらを参照してください。自分でデプロイするのは多少難しいことが予想されますが、おおよそ実行できるはずです。
crawler.py編集し、それを実行して初期データセットを収集します。mse.py実行し、インデックスを付けます。rater_server.pyを使用して、ペアの初期データセットを収集します。train.py使用してモデルをトレーニングします。どのハイパーパラメータが良いのかわからないので、ハイパーパラメータを調整する必要があるかもしれません。active_learning.py使用して、評価する新しいペアを取得します。copy_into_queue.pyを使用して、新しいペアをrater_server.pyキューにコピーします。library_processing_server.pyをデプロイし、 meme_pipeline.py定期的に実行するようにスケジュールします。 ミーム検索エンジンは、埋め込みベクトルを保持するためにメモリ内の FAISS インデックスを使用します。これは、私が怠け者だったためであり、正常に動作します (8000 個のミームに使用される合計 RAM は約 100MB)。それよりも大幅に多くのインデックスを保存したい場合は、より効率的でコンパクトなインデックスに切り替える必要があります (ここを参照)。ベクトル インデックスはメモリ内に排他的に保持されるため、ベクトル インデックスをディスクに永続化するか、構築/削除/追加が高速なインデックス (おそらく PCA/PQ インデックス) を使用する必要があります。ある時点で総トラフィックが増加すると、バッチ処理戦略がないため、CLIP モデルもボトルネックになる可能性があります。新しいモデルはバッチサイズが大きいと若干遅くなり、画像読み込みパイプラインを改善したため、インデックス作成は現在 GPU に依存しています。必要な帯域幅を削減するために、表示されるミームを縮小することもできます。


