dsub
Release 0.5.0
dsubクラウドでのバッチ スクリプトの送信と実行を簡単にするコマンドライン ツールです。
dsubユーザー エクスペリエンスは、Grid Engine や Slurm などの従来のハイパフォーマンス コンピューティング ジョブ スケジューラをモデルにしています。スクリプトを作成し、ローカル マシン上のシェル プロンプトからジョブ スケジューラに送信します。
現在、 dsubバックエンド バッチ ジョブ ランナーとして Google Cloud をサポートしているほか、開発とテストのためのローカル プロバイダーもサポートしています。コミュニティの協力を得て、Grid Engine、Slurm、Amazon Batch、Azure Batch などの他のバックエンドを追加したいと考えています。
dsub Python で書かれており、Python 3.7 以降が必要です。
dsub 0.4.7 でした。dsub 0.4.1 を使用します。dsub 0.3.10 を使用します。これはオプションですが、PyPI からインストールするか github からインストールするかに関係なく、Python 仮想環境を使用することを強くお勧めします。
これは、選択したディレクトリで実行できます。
python3 -m venv dsub_libs
source dsub_libs/bin/activate
Python 仮想環境を使用すると、システム上の他の Python アプリケーションからdsubライブラリの依存関係が分離されます。
dsub実行する前に、任意のシェル セッションでこの仮想環境をアクティブ化します。シェルで仮想環境を非アクティブ化するには、次のコマンドを実行します。
deactivate
あるいは、 dsub 、 dstat 、およびddel呼び出す前に virutalenv をアクティブ化する便利なスクリプトのセットが提供されています。これらは bin ディレクトリにあります。シェルで virtualenv を明示的にアクティブにしたくない場合は、これらのスクリプトを使用できます。
google-batchプロバイダーまたはgoogle-cls-v2プロバイダーのdsubによって直接使用されることはありませんが、Google Cloud SDK にあるコマンドライン ツールをインストールすることもできます。
ジョブ開発を迅速化するためにlocalプロバイダを使用する場合は、Google Cloud SDK をインストールする必要があります。これは、 gsutil使用してファイル操作セマンティクスが Google dsubプロバイダと一貫していることを確認します。
Google Cloud SDKをインストールする
走る
gcloud init
gcloudデフォルト プロジェクトを設定し、Google Cloud SDK に認証情報を付与するように求められます。
dsubをインストールする次のいずれかを選択します。
必要に応じて pip をインストールします。
dsubをインストールする
pip install dsub
git がインストールされていることを確認してください
ご使用の環境の手順については、git Web サイトをご覧ください。
このリポジトリのクローンを作成します。
git clone https://github.com/DataBiosphere/dsub
cd dsub
dsub をインストールします (これにより依存関係もインストールされます)
python -m pip install .
Bash のタブ補完を設定します (オプション)。
source bash_tab_complete
以下を実行して、インストールを最小限に確認します。
dsub --help
(オプション) Docker をインストールします。
これは、独自の Docker イメージを作成する場合、またはlocalプロバイダーを使用する場合にのみ必要です。
dsub リポジトリのクローンを作成した後、以下を実行して Makefile を使用することもできます。
make
これにより、Python 仮想環境が作成され、 dsub_libsという名前のディレクトリにdsubがインストールされます。
dsubタスクを構築する際には、 localプロバイダーが非常に役立つことがわかると思います。クラウド VM 上でコマンドを実行するリクエストを送信する代わりに、 localプロバイダーはローカル マシン上でdsubタスクを実行します。
localプロバイダーは、大規模な実行向けに設計されていません。クラウド VM 上での実行をエミュレートして、迅速に反復できるように設計されています。これを使用すると、所要時間が短縮され、クラウド料金は発生しません。
dsubジョブを実行し、完了するまで待ちます。
以下は非常に単純な「Hello World」テストです。
dsub
--provider local
--logging "${TMPDIR:-/tmp}/dsub-test/logging/"
--output OUT="${TMPDIR:-/tmp}/dsub-test/output/out.txt"
--command 'echo "Hello World" > "${OUT}"'
--wait
注: ほとんどの Unix システムでは、 TMPDIR通常、デフォルトで/tmpに設定されますが、未設定のままになることもよくあります。 MacOS の一部のバージョンでは、 TMPDIR は/var/folders下の場所に設定されます。
注: 上記の構文${TMPDIR:-/tmp} Bash、zsh、ksh でサポートされていることがわかっています。シェルはTMPDIRを展開しますが、設定されていない場合は/tmp使用されます。
出力ファイルを表示します。
cat "${TMPDIR:-/tmp}/dsub-test/output/out.txt"
dsub現在、Google Cloud の Cloud Life Sciences v2beta API をサポートしており、Google Cloud の Batch API のサポートを開発中です。
dsub google-cls-v2プロバイダーで v2beta API をサポートします。 google-cls-v2が現在のデフォルトのプロバイダーです。 dsub今後のリリースでgoogle-batchデフォルトにするよう移行する予定です。
以下の手順に示すように、開始手順は若干異なります。
Googleアカウントにサインアップしてプロジェクトを作成します。
API を有効にします。
v2beta API (プロバイダー: google-cls-v2 ) の場合:クラウド ライフ サイエンス、ストレージ、およびコンピューティング API を有効にする
batch API (プロバイダー: google-batch ) の場合:バッチ、ストレージ、およびコンピューティング API を有効にします。
dsub Google API を呼び出せるように資格情報を指定します。
gcloud auth application-default login
Google Cloud Storage バケットを作成します。
dsub ログと出力ファイルはバケットに書き込まれます。ストレージ ブラウザを使用してバケットを作成するか、Cloud SDK に含まれるコマンドライン ユーティリティ gsutil を実行します。
gsutil mb gs://my-bucket
my-bucketバケットの命名規則に従って一意の名前に変更します。
(デフォルトでは、バケットは米国にありますが、 -lオプションを使用して場所の設定を変更または調整できます。)
非常に単純な「Hello World」 dsubジョブを実行し、完了するまで待ちます。
v2beta API (プロバイダー: google-cls-v2 ) の場合:
dsub
--provider google-cls-v2
--project my-cloud-project
--regions us-central1
--logging gs://my-bucket/logging/
--output OUT=gs://my-bucket/output/out.txt
--command 'echo "Hello World" > "${OUT}"'
--wait
my-cloud-project Google Cloud プロジェクトに変更し、 my-bucket上で作成したバケットに変更します。
batch API (プロバイダー: google-batch ) の場合:
dsub
--provider google-batch
--project my-cloud-project
--regions us-central1
--logging gs://my-bucket/logging/
--output OUT=gs://my-bucket/output/out.txt
--command 'echo "Hello World" > "${OUT}"'
--wait
my-cloud-project Google Cloud プロジェクトに変更し、 my-bucket上で作成したバケットに変更します。
スクリプト コマンドの出力は、指定した Cloud Storage 内のOUTファイルに書き込まれます。
出力ファイルを表示します。
gsutil cat gs://my-bucket/output/out.txt
可能な場合、 dsubユーザーがローカルで開発およびテストし (反復を高速化するため)、その後大規模な実行に進むことができるようにサポートしようとします。
この目的のために、 dsub複数の「バックエンド プロバイダー」を提供し、それぞれが一貫したランタイム環境を実装します。現在のプロバイダーは次のとおりです。
バックエンド プロバイダーによって実装されるランタイム環境の詳細については、dsub バックエンド プロバイダーを参照してください。
google-cls-v2とgoogle-batchの違いgoogle-cls-v2プロバイダーは、Cloud Life Sciences v2beta API に基づいて構築されています。この API は、その前身である Genomics v2alpha1 API と非常によく似ています。違いの詳細については、移行ガイドを参照してください。
google-batchプロバイダは Cloud Batch API に基づいて構築されています。クラウド ライフ サイエンスとバッチの詳細については、この移行ガイドを参照してください。
dsub API 間の違いをほとんど隠していますが、注意すべき違いがいくつかあります。
google-batchジョブを 1 つのリージョンで実行する必要がありますdsubの--regionsフラグと--zonesフラグは、タスクを実行する場所を指定します。 google-cls-v2 USようなマルチリージョン、複数のリージョン、またはリージョン間の複数のゾーンを指定できます。 google-batchプロバイダーを使用する場合は、1 つのリージョンまたは 1 つのリージョン内の複数のゾーンを指定する必要があります。
dsub機能次のセクションでは、より複雑なジョブを実行する方法を示します。
上記の hello の例のように、dsub コマンド ラインでシェル コマンドを直接指定できます。
スクリプトをhello.shなどのファイルに保存することもできます。次に、次を実行できます。
dsub
...
--script hello.sh
スクリプトに Docker イメージに保存されていない依存関係がある場合は、それらをローカル ディスクに転送できます。入力ファイルと出力ファイルおよびフォルダーの操作については、以下の手順を参照してください。
より簡単に始めるために、 dsubストックの Ubuntu Docker イメージを使用します。このデフォルトのイメージは将来のリリースでいつでも変更される可能性があるため、再現可能な運用ワークフローを実現するには、常にイメージを明示的に指定する必要があります。
--imageフラグを渡すことでイメージを変更できます。
dsub
...
--image ubuntu:16.04
--script hello.sh
注: --imageには Bash シェル インタープリタが含まれている必要があります。
--imageフラグの使用の詳細については、「スクリプト、コマンド、および Docker」のイメージのセクションを参照してください。
--envフラグを使用して、環境変数をスクリプトに渡すことができます。
dsub
...
--env MESSAGE=hello
--command 'echo ${MESSAGE}'
Docker コンテナーの実行時に、環境変数MESSAGE値helloが割り当てられます。
スクリプトまたはコマンドは、他の Linux 環境変数と同様に、 ${MESSAGE}として変数を参照できます。
コマンド文字列は二重引用符ではなく、必ず一重引用符で囲んでください。二重引用符を使用すると、コマンドは dsub に渡される前にローカル シェルで展開されます。 --commandフラグの使用の詳細については、「スクリプト、コマンド、および Docker」を参照してください。
複数の環境変数を設定するには、フラグを繰り返すことができます。
--env VAR1=value1
--env VAR2=value2
単一のフラグを使用して、スペースで区切って複数の変数を設定することもできます。
--env VAR1=value1 VAR2=value2
dsub は、入力および出力ファイルとフォルダーのクラウド ストレージ バケット パスを使用して、共有ファイル システムの動作を模倣します。クラウド ストレージ バケット パスを指定します。パスは次のとおりです。
gs://my-bucket/my-fileようなファイル パスgs://my-bucket/my-folderのようなフォルダー パスgs://my-bucket/my-folder/*のようなワイルドカード パス詳細については、入力と出力のドキュメントを参照してください。
スクリプトが Docker イメージ内にまだ含まれていないローカル入力ファイルを読み取ることを想定している場合、そのファイルは Google Cloud Storage で利用可能である必要があります。
スクリプトに依存ファイルがある場合は、次の方法で依存ファイルをスクリプトで使用できるようにできます。
ファイルを Google Cloud Storage にアップロードするには、ストレージ ブラウザまたは gsutil を使用できます。また、公開されているデータ、またはサービス アカウント (Google Cloud Console で確認できるメール アドレス) と共有されているデータに対して実行することもできます。
入力ファイルと出力ファイルを指定するには、 --inputフラグと--outputフラグを使用します。
dsub
...
--input INPUT_FILE_1=gs://my-bucket/my-input-file-1
--input INPUT_FILE_2=gs://my-bucket/my-input-file-2
--output OUTPUT_FILE=gs://my-bucket/my-output-file
--command 'cat "${INPUT_FILE_1}" "${INPUT_FILE_2}" > "${OUTPUT_FILE}"'
この例では:
gs://my-bucket/my-input-file-1からデータ ディスク上のパスにコピーされます${INPUT_FILE_1}に設定されます。gs://my-bucket/my-input-file-2からデータ ディスク上のパスにコピーされます${INPUT_FILE_2}に設定されます。 --command環境変数を使用してファイル パスを参照できます。
この例でも次のようになります。
${OUTPUT_FILE}に設定されます。${OUTPUT_FILE}で指定された場所にあるデータ ディスクに書き込まれます。 --commandが完了すると、出力ファイルはバケット パスgs://my-bucket/my-output-fileにコピーされます。
複数の--inputおよび--outputパラメータを指定でき、それらは任意の順序で指定できます。
ファイルではなくフォルダーをコピーするには、 --input-recursiveとoutput-recursiveフラグを使用します。
dsub
...
--input-recursive FOLDER=gs://my-bucket/my-folder
--command 'find ${FOLDER} -name "foo*"'
複数の--input-recursiveおよび--output-recursiveパラメーターを指定でき、それらは任意の順序で指定できます。
入力を明示的に指定するとデータの出所の追跡が向上しますが、Cloud Storage からジョブ VM へのすべての入力を明示的にローカライズしたくない場合もあります。
たとえば、次のような場合です。
または
または
その場合は、読み取り専用でマウントしてこのデータにアクセスする方が効率的または便利であることがわかります。
google-cls-v2およびgoogle-batchプロバイダーは、リソース データへのアクセスを提供するこれらの方法をサポートしています。
localプロバイダーは、ローカル開発をサポートするために、同様の方法でローカル ディレクトリのマウントをサポートします。
google-cls-v2またはgoogle-batchプロバイダに Cloud Storage FUSE を使用して Cloud Storage バケットをマウントさせるには、 --mountコマンドライン フラグを使用します。
--mount RESOURCES=gs://mybucket
バケットは、 --scriptまたは--command実行する Docker コンテナに読み取り専用でマウントされ、その場所は環境変数${RESOURCES}を介して利用可能になります。スクリプト内では、環境変数を使用してマウントされたパスを参照できます。 Cloud Storage FUSE を使用する前に、POSIX ファイル システムとの主な違いとセマンティクスをお読みください。
事前に作成して設定した永続ディスクをgoogle-cls-v2またはgoogle-batchプロバイダーにマウントさせるには、 --mountコマンド ライン フラグとソース ディスクの URL を使用します。
--mount RESOURCES="https://www.googleapis.com/compute/v1/projects/your-project/zones/your_disk_zone/disks/your-disk"
google-cls-v2またはgoogle-batchプロバイダーにイメージから作成された永続ディスクをマウントさせるには、 --mountコマンド ライン フラグ、ソース イメージの URL、およびディスクのサイズ (GB 単位) を使用します。
--mount RESOURCES="https://www.googleapis.com/compute/v1/projects/your-project/global/images/your-image 50"
このイメージは、Compute Engine VM に接続される新しい永続ディスクの作成に使用されます。ディスクは、 --scriptまたは--command実行する Docker コンテナにマウントされ、その場所は環境変数${RESOURCES}によって利用可能になります。スクリプト内では、環境変数を使用してマウントされたパスを参照できます。
イメージを作成するには、「カスタム イメージの作成」を参照してください。
localプロバイダー) localプロバイダーにディレクトリを読み取り専用でマウントさせるには、 --mountコマンド ライン フラグとfile://プレフィックスを使用します。
--mount RESOURCES=file://path/to/my/dir
ローカル ディレクトリは、 --scriptまたは--commandを実行する Docker コンテナにマウントされ、その場所は環境変数${RESOURCES}を介して利用可能になります。スクリプト内では、環境変数を使用してマウントされたパスを参照できます。
localプロバイダーを使用して実行されるdsubタスクは、ローカル マシンで利用可能なリソースを使用します。
google-cls-v2またはgoogle-batchプロバイダーを使用して実行されるdsubタスクは、CPU、RAM、ディスク、およびハードウェア アクセラレータ (GPU など) の幅広いオプションを利用できます。
詳細については、コンピューティング リソースのドキュメントを参照してください。
デフォルトでは、 dsub job-name--userid--timestampの形式でjob-idを生成します。ここで、 job-name 10 文字で切り捨てられ、 timestampはYYMMDD-HHMMSS-XXの形式で、100 分の 1 秒単位で一意です。 。複数のジョブを同時に送信している場合でも、 job-idが一意ではない状況が発生する可能性があります。この状況で一意のjob-idが必要な場合は、 --unique-job-idパラメーターを使用できます。
--unique-job-idパラメーターが設定されている場合、 job-id https://docs.python.org/3/library/uuid.html によって作成された一意の 32 文字の UUID になります。一部のプロバイダーではjob-id文字で始まることが必要なため、 dsub一意性を維持する方法で開始桁を文字に置き換えます。
上記の各例では、変数、入力、出力の単一セットを使用して単一のタスクを送信する方法を示しました。入力のバッチがあり、それらに対して同じ操作を実行したい場合は、 dsub使用してバッチ ジョブを作成できます。
dsub繰り返し呼び出す代わりに、各タスクの変数、入力、出力を含むタブ区切り値 (TSV) ファイルを作成し、 dsub 1 回呼び出すことができます。結果は、複数のタスクを含む単一のjob-idになります。タスクは個別にスケジュールおよび実行されますが、グループとして監視および削除することができます。
TSV ファイルの最初の行では、パラメータの名前とタイプを指定します。例えば:
--env SAMPLE_ID<tab>--input VCF_FILE<tab>--output OUTPUT_PATH
ファイル内の各追加行には、各タスクの変数、入力値、および出力値を指定する必要があります。ヘッダー以降の各行は、個別のタスクの値を表します。
複数の--env 、 --input 、および--outputパラメータを指定でき、それらは任意の順序で指定できます。例えば:
--env SAMPLE<tab>--input A<tab>--input B<tab>--env REFNAME<tab>--output O
S1<tab>gs://path/A1.txt<tab>gs://path/B1.txt<tab>R1<tab>gs://path/O1.txt
S2<tab>gs://path/A2.txt<tab>gs://path/B2.txt<tab>R2<tab>gs://path/O2.txt
--tasksパラメーターを使用して、TSV ファイルを dsub に渡します。このパラメータは、ファイル パスと、オプションで処理するタスクの範囲の両方を受け入れます。ファイルは、ローカル ファイル システム ( dsub呼び出し元のマシン上) から、または Google Cloud Storage のバケット (ファイル名は「gs://」で始まる) から読み取られます。
たとえば、 my-tasks.tsvに 101 行、つまり 1 行のヘッダーと実行するタスクのパラメーターが 100 行含まれているとします。それから:
dsub ... --tasks ./my-tasks.tsv
100 個のタスクを含むジョブが作成されますが、次のようになります。
dsub ... --tasks ./my-tasks.tsv 1-10
2 行目から 11 行目までに 1 つずつ、合計 10 個のタスクを含むジョブが作成されます。
タスク範囲の値は、次のいずれかの形式を取ることができます。
mタスクmサブミットすることを示します (行 m+1)m-タスクmで始まるすべてのタスクを送信することを示しますmn 、 mからn (両端を含む) までのすべてのタスクを送信することを示します。--loggingフラグは、 dsubタスク ログ ファイルの場所を指します。ログ パスの指定方法の詳細については、「ログ」を参照してください。
ジョブが完了するまで待ってから別のジョブを開始することができます。詳細については、「dsub によるジョブ制御」を参照してください。
dsub失敗したタスクを自動的に再試行することができます。詳細については、「dsub による再試行」を参照してください。
ジョブやタスクにカスタム ラベルを追加すると、独自の識別子を使用してタスクを監視したりキャンセルしたりできます。さらに、Google プロバイダでは、タスクにラベルを付けると、仮想マシンやディスクなどの関連するコンピューティング リソースにもラベルが付けられます。
詳細については、「ステータスの確認とジョブのトラブルシューティング」を参照してください。
dstatコマンドはジョブのステータスを表示します。
dstat --provider google-cls-v2 --project my-cloud-project
追加の引数を指定しないと、 dstat は現在のUSERに対して実行中のジョブのリストを表示します。
特定のジョブのステータスを表示するには、 --jobsフラグを使用します。
dstat --provider google-cls-v2 --project my-cloud-project --jobs job-id
バッチ ジョブの場合、出力には実行中のすべてのタスクがリストされます。
dsub によって送信された各ジョブには、ジョブの識別とジョブ制御に使用できるメタデータ値のセットが与えられます。各ジョブに関連付けられたメタデータには次のものが含まれます。
job-name : デフォルトは、スクリプト ファイルの名前またはスクリプト コマンドの最初の単語です。 --nameパラメータを使用して明示的に設定できます。user-id : USER環境変数の値。job-id : ジョブの識別子。これは、それぞれジョブの監視とキャンセルのためのdstatとddelの呼び出しで使用できます。 job-id形式の詳細については、「ジョブ ID」を参照してください。task-id : ジョブが--tasksパラメーターを使用して送信された場合、各タスクは「task- n 」形式の連続した値を取得します。nは 1 から始まります。ジョブのメタデータ値は、『ステータスの確認とジョブのトラブルシューティング』ガイドに記載されている「ラベルの制限」に準拠するように変更されることに注意してください。
メタデータを使用して、ジョブまたはバッチ ジョブ内の個々のタスクをキャンセルできます。
詳細については、「ステータスの確認とジョブのトラブルシューティング」を参照してください。
デフォルトでは、dstat はタスクごとに 1 行を出力します。多くのタスクを含むバッチ ジョブを使用している場合は、 --summaryの利点が得られる可能性があります。
$ dstat --provider google-cls-v2 --project my-project --status '*' --summary
Job Name Status Task Count
------------- ------------- -------------
my-job-name RUNNING 2
my-job-name SUCCESS 1
このモードでは、dstat は (ジョブ名、タスクのステータス) のペアごとに 1 行を出力します。完了したタスクの数、まだ実行中のタスクの数、失敗/キャンセルされたタスクの数が一目でわかります。
ddelコマンドは実行中のジョブを削除します。
デフォルトでは、現在のユーザーによって送信されたジョブのみが削除されます。他のユーザーを指定するには--usersフラグを使用するか、すべてのユーザーには'*'使用します。
実行中のジョブを削除するには:
ddel --provider google-cls-v2 --project my-cloud-project --jobs job-id
ジョブがバッチ ジョブの場合、実行中のタスクはすべて削除されます。
特定のタスクを削除するには:
ddel
--provider google-cls-v2
--project my-cloud-project
--jobs job-id
--tasks task-id1 task-id2
現在のユーザーの実行中のジョブをすべて削除するには:
ddel --provider google-cls-v2 --project my-cloud-project --jobs '*'
google-cls-v2またはgoogle-batchプロバイダーを使用してdsubコマンドを実行する場合は、2 つの異なる資格情報のセットを考慮する必要があります。
pipelines.run()リクエストを送信するアカウントpipelines.run()リクエストの送信に使用されるアカウントは通常、エンド ユーザーの資格情報です。これを設定するには、次のコマンドを実行します。
gcloud auth application-default login
VM で使用されるアカウントはサービス アカウントです。以下の図はこれを示しています。
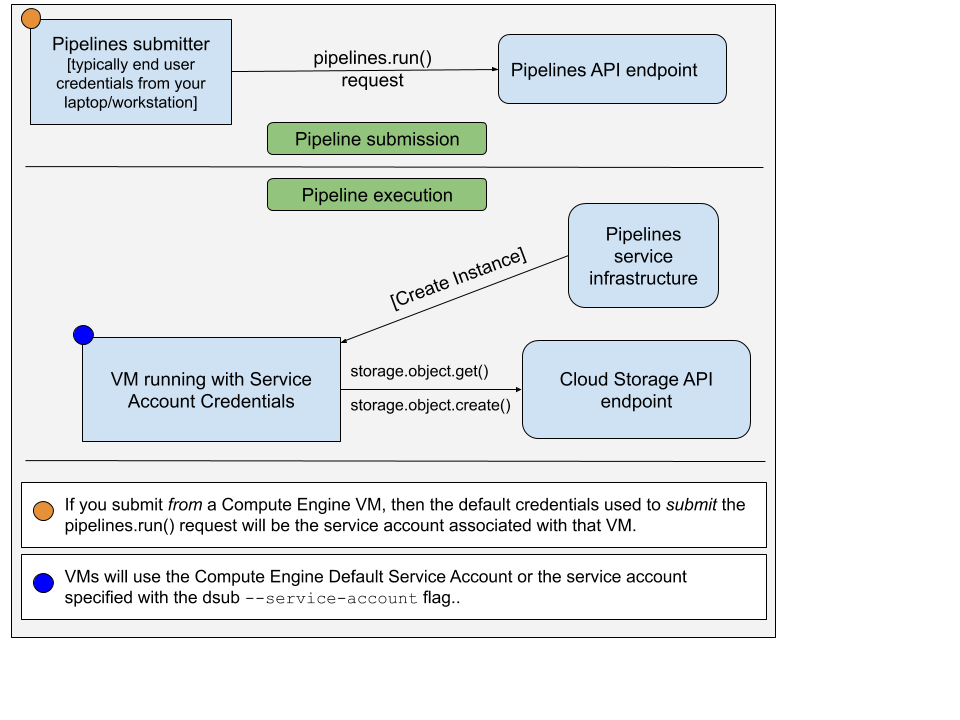
デフォルトでは、 dsubデフォルトの Compute Engine サービス アカウントを VM インスタンスの承認されたサービス アカウントとして使用します。 --service-account使用して、別のサービス アカウントの電子メール アドレスを指定することもできます。
デフォルトでは、 dsubサービス アカウントに次のアクセス スコープを付与します。
さらに、API は常に次のスコープを追加します。
--scopes使用してスコープを指定することもできます。
デフォルトのサービス アカウントを使用するのは簡単ですが、このアカウントにはデフォルトで広範な権限も付与されています。最小特権の原則に従って、 dsubコマンド/スクリプトを実行するために必要な特権のみが付与されたサービス アカウントを作成して使用することができます。
新しいサービス アカウントを作成するには、次の手順に従います。
gcloud iam service-accounts createコマンドを実行します。サービス アカウントの電子メール アドレスは[email protected]になります。
gcloud iam service-accounts create "sa-name"
バケットなどに対する IAM アクセスをサービス アカウントに付与します。
gsutil iam ch serviceAccount:[email protected]:roles/storage.objectAdmin gs://bucket-name
--service-account含めるようにdsubコマンドを更新します
dsub
--service-account [email protected]
...
例を参照してください。
詳細については、次のドキュメントを参照してください。


