SOLIDER
1.0.0

ソルダーへようこそ! SOLIDER は、大量のラベルのない人間の画像から一般的な人間の表現を学習するためのセマンティック制御可能な自己教師あり学習フレームワークで、下流の人間中心のタスクに最大限のメリットをもたらします。既存の自己教師あり学習方法とは異なり、SOLIDER では人間の画像からの事前知識を利用して、擬似意味ラベルを構築し、より多くの意味情報を学習された表現にインポートします。一方、異なる下流タスクは常に異なる比率の意味情報と外観情報を必要とし、単一の学習された表現がすべての要件に適合することはできません。この問題を解決するために、SOLIDER は下流タスクのさまざまなニーズに適合できるセマンティック コントローラーを備えた条件付きネットワークを導入します。詳細については、論文「外観を超えて: 人間中心の視覚タスクのためのセマンティック制御可能な自己教師あり学習フレームワーク」を参照してください。
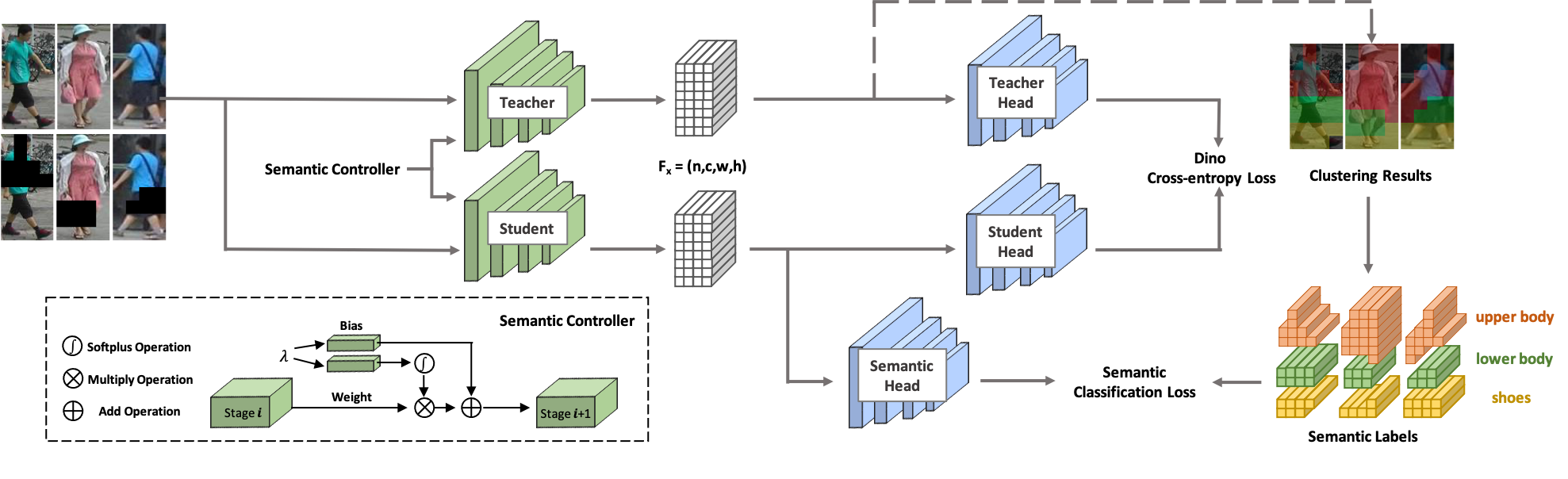
このコードベースは、Python バージョン 3.7、PyTorch バージョン 1.7.1、CUDA 10.1、および torchvision 0.8.2 を使用して開発されました。
ラベルのない人間の画像で構成されるLUperson をトレーニング データとして使用します。公式リンクからLUPersonal をダウンロードし、解凍します。
sh run_solider.shsh run_dino.sh
sh resume_solider.shトレーニング済みの SOLIDER モデルを実行するデモがあり、推論や下流タスクの微調整に組み込むことができます。
python demo.py私たちは Swin-Transformer をバックボーンとして使用しており、多くの CV タスクで大きな利点を示しています。
| タスク | データセット | スウィンタイニー (リンク) | スウィン小 (リンク) | スウィンベース (リンク) |
|---|---|---|---|---|
| 個人の再識別 (mAP/R1) 再ランキングなし | マーケット1501 | 91.6/96.1 | 93.3/96.6 | 93.9/96.9 |
| MSMT17 | 67.4/85.9 | 76.9/90.8 | 77.1/90.7 | |
| 個人の再識別 (mAP/R1) 再ランキングあり | マーケット1501 | 95.3/96.6 | 95.4/96.4 | 95.6/96.7 |
| MSMT17 | 81.5/89.2 | 86.5/91.7 | 86.5/91.7 | |
| 属性認識 (mA) | PETA_ZS | 74.37 | 76.21 | 76.43 |
| RAP_ZS | 74.23 | 75.95 | 76.42 | |
| PA100K | 84.14 | 86.25 | 86.37 | |
| 人物検索(mAP/R1) | チュ香港シス | 94.9/95.7 | 95.5/95.8 | 94.9/95.5 |
| PRW | 56.8/86.8 | 59.8/86.7 | 59.7/86.8 | |
| 歩行者検知(MR-2) | 都市人物 | 10.3/40.8 | 10.0/39.2 | 9.7/39.4 |
| 人間による解析 (mIOU) | リップ | 57.52 | 60.21 | 60.50 |
| 姿勢推定(AP/AR) | ココ | 74.4/79.6 | 76.3/81.3 | 76.6/81.5 |
私たちの実装は主に次のコードベースに基づいています。素晴らしい作品をありがとうございます。
研究で SOLIDER を使用する場合は、次の BibTeX エントリを使用して私たちの成果を引用してください。
@inproceedings{chen2023beyond,
title={Beyond Appearance: a Semantic Controllable Self-Supervised Learning Framework for Human-Centric Visual Tasks},
author={Weihua Chen and Xianzhe Xu and Jian Jia and Hao Luo and Yaohua Wang and Fan Wang and Rong Jin and Xiuyu Sun},
booktitle={The IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2023},
}


