TEMPO
1.0.0

[「TEMPO: 時系列予測用のプロンプトベースの生成事前トレーニング済みトランスフォーマー (ICLR 2024)」] の公式コード。
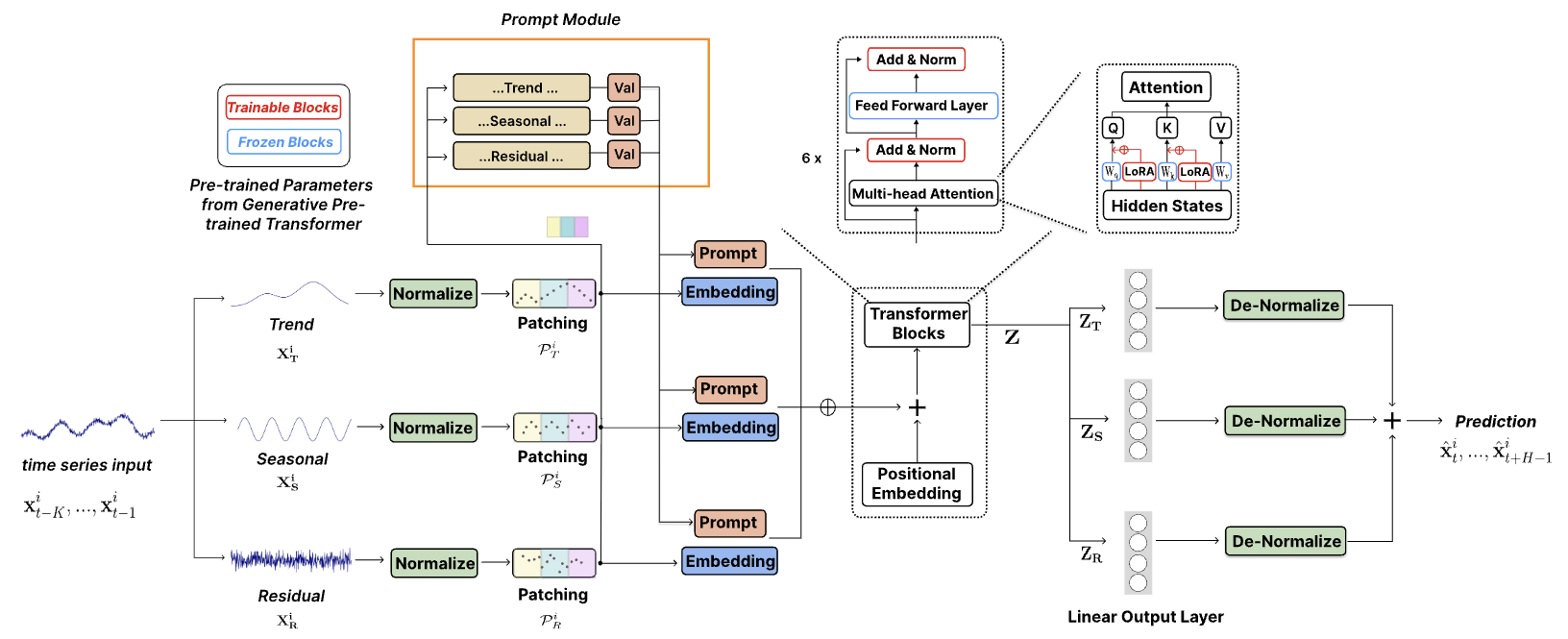
TEMPO は、予測タスク用の最初のオープンソースTime Series Foundation Models v1.0 バージョンの 1 つです。
2024 年 10 月: コード構造を合理化し、ユーザーが事前トレーニングされたモデルをダウンロードし、コード 1 行でゼロショット推論を実行できるようにしました。詳細については、デモをご覧ください。 HuggingFace でのモデルのダウンロード数が追跡できるようになりました。
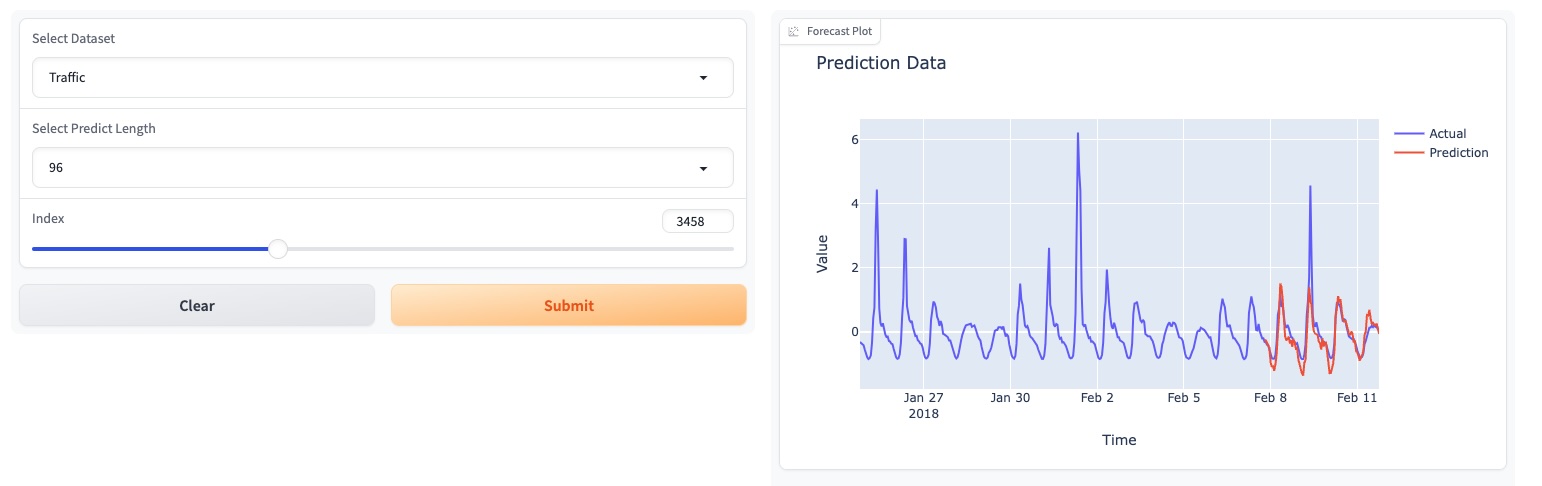
2024 年 6 月: Colab でゼロショット実験を再現するためのデモを追加しました。また、顧客データセットを構築し、事前トレーニングされた基盤モデルを介して直接推論を行うデモも追加しました: Colab
2024 年 5 月: TEMPO は GUI ベースのオンライン デモを開始し、ユーザーが当社の基礎モデルと直接対話できるようにしました。
2024 年 5 月: TEMPO が 80M の事前学習済み基礎モデルを HuggingFace に公開しました。
2024年5月:?事前トレーニングと推論 TEMPO モデルのコードを追加しました。このフォルダーには、事前トレーニング スクリプトのデモがあります。推論デモ用のスクリプトも追加しました。
2024年3月:? TEMPO のマルチモーダル実験で使用される S&P 500 の TETS データセットをリリースしました。
2024年3月:? TEMPO はプロジェクト コードと事前トレーニングされたチェックポイントをオンラインで公開しました。
2024年1月:TEMPO論文がICLRに受理されました!
2023 年 10 月: TEMPO 論文が Arxiv でリリースされました。
conda create -n tempo python=3.8
conda activate tempo
pip install -r requirements.txt
TEMPO を使用して予測を実行する方法を示す合理化された例:
# Third-party library imports
import numpy as np
import torch
from numpy . random import choice
# Local imports
from models . TEMPO import TEMPO
model = TEMPO . load_pretrained_model (
device = torch . device ( 'cuda:0' if torch . cuda . is_available () else 'cpu' ),
repo_id = "Melady/TEMPO" ,
filename = "TEMPO-80M_v1.pth" ,
cache_dir = "./checkpoints/TEMPO_checkpoints"
)
input_data = np . random . rand ( 336 ) # Random input data
with torch . no_grad ():
predicted_values = model . predict ( input_data , pred_length = 96 )
print ( "Predicted values:" )
print ( predicted_values )ETTh2 [ここ Colab] でゼロショット実験を再現してみてください。
次の Colab ページを使用して、顧客データセットの構築のデモを示し、事前トレーニングされた基礎モデルを介して推論を直接実行します。
基礎モデルのデモ [こちら] をお試しください。
HuggingFace のモデル [Melady/TEMPO] も更新しました。
[Google Drive]または[Baidu Drive]からデータをダウンロードし、ダウンロードしたデータをフォルダー./datasetに配置します。 [Google ドライブ]から STL 結果をダウンロードし、ダウンロードしたデータをフォルダー./stlに配置することもできます。
bash [ecl, etth1, etth2, ettm1, ettm2, traffic, weather].sh
トレーニング後、ゼロショット設定で TEMPO モデルをテストできます。
bash [ecl, etth1, etth2, ettm1, ettm2, traffic, weather]_test.sh
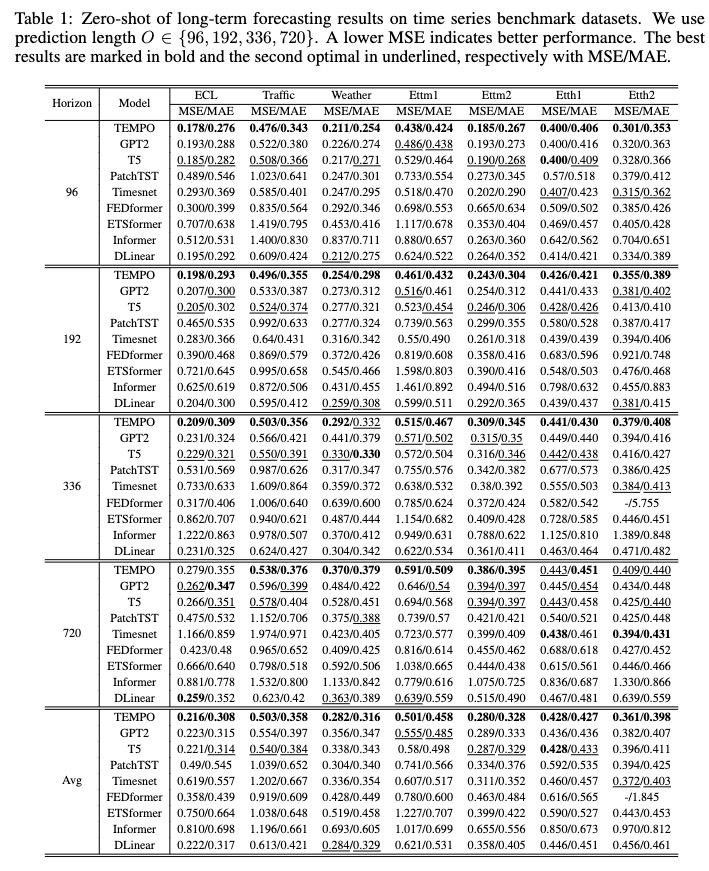
[Google ドライブ] から事前トレーニングされたモデルをダウンロードして、テスト スクリプトを実行して楽しむことができます。
[OPENAI ChatGPT-3.5 API] 経由で時系列の対応するテキスト情報を生成するために使用するプロンプトは次のとおりです。

時系列データは [S&P 500] から取得されています。データセットからの 1 つの企業の EBITDA のケースは次のとおりです。
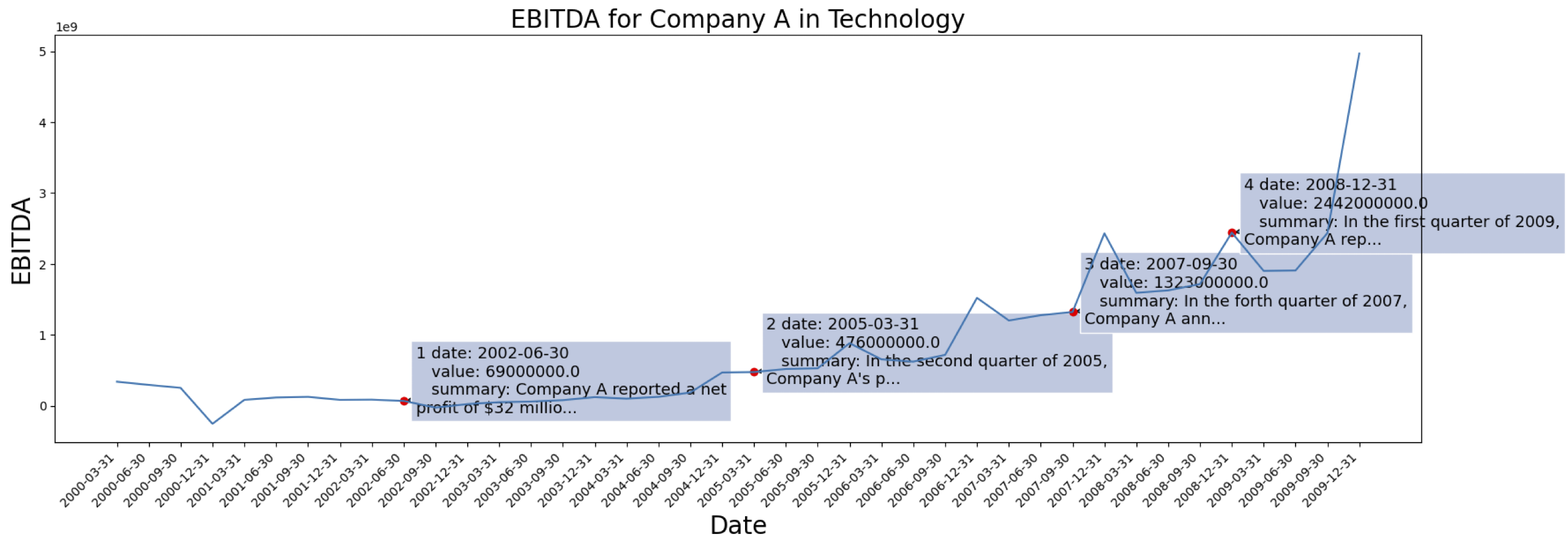
上記でマークされた会社について生成されたコンテキスト情報の例:
GPT2 からテキストが埋め込まれた処理済みデータは、[TETS] からダウンロードできます。
TEMPO を実際のアプリケーションに適用することに興味がある場合は、お気軽に [email protected] / [email protected] に連絡してください。
@inproceedings{
cao2024tempo,
title={{TEMPO}: Prompt-based Generative Pre-trained Transformer for Time Series Forecasting},
author={Defu Cao and Furong Jia and Sercan O Arik and Tomas Pfister and Yixiang Zheng and Wen Ye and Yan Liu},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=YH5w12OUuU}
}
@article{
Jia_Wang_Zheng_Cao_Liu_2024,
title={GPT4MTS: Prompt-based Large Language Model for Multimodal Time-series Forecasting},
volume={38},
url={https://ojs.aaai.org/index.php/AAAI/article/view/30383},
DOI={10.1609/aaai.v38i21.30383},
number={21},
journal={Proceedings of the AAAI Conference on Artificial Intelligence},
author={Jia, Furong and Wang, Kevin and Zheng, Yixiang and Cao, Defu and Liu, Yan},
year={2024}, month={Mar.}, pages={23343-23351}
}


