MedicalGPT
v2.2.0
??中文|英語|モデル/モデル

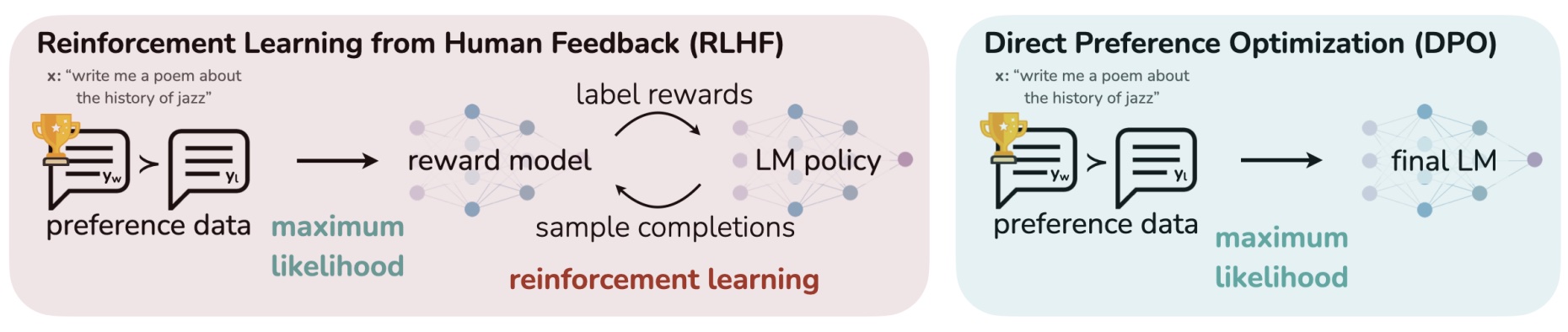
MedicalGPT は、ChatGPT トレーニング パイプラインを使用した医療 GPT モデルのトレーニング、事前トレーニング、教師あり微調整、RLHF (報酬モデリングと強化学習)、および DPO (直接優先最適化) の実装です。
MedicalGPT は、大規模な医療モデルをトレーニングし、増分事前トレーニング、教師あり微調整、RLHF (報酬モデリング、強化学習トレーニング)、および DPO (直接優先最適化) を実装します。
[2024/09/21] v2.3 バージョン: Qwen-2.5シリーズ モデルをサポート、詳細については Release-v2.3 を参照してください。
[2024/08/02] v2.2 バージョン: ロールプレイング モデルのトレーニングをサポートし、医師と患者の対話 SFT データ生成スクリプト role_play_data を追加しました。 詳細については、Release-v2.2 を参照してください。
[2024/06/11] v2.1 バージョン: Qwen-2シリーズ モデルをサポート、詳細については Release-v2.1 を参照してください。
[2024/04/24] v2.0 バージョン: Llama-3シリーズ モデルをサポート、詳細については Release-v2.0 を参照してください。
[2024/04/17] v1.9 バージョン: ORPO をサポートしました。詳しい使用方法はrun_orpo.shを参照してください。詳細については、リリース v1.9 を参照してください。
[2024/01/26] v1.8 バージョン: Mixtral ハイブリッド エキスパート MoE モデルMixtral 8x7Bの微調整をサポートしました。詳細については、リリース v1.8 を参照してください。
[2024/01/14] v1.7 バージョン: 検索拡張生成 (RAG) ベースのファイル Q&A ChatPDF 関数、コードchatpdf.pyを追加しました。これにより、ナレッジ ベース ファイル Q&A と組み合わせた微調整された LLM に基づいて業界の Q&A の精度を向上させることができます。詳細については、リリース v1.7 を参照してください。
[2023/10/23] v1.6 バージョン: GPT モデルのコンテキスト長を拡張するための RoPE 補間を追加、LLaMA モデルの FlashAttendant-2 と LongLoRA をサポート
[2023/08/28] バージョン v1.5: DPO (Direct Preference Optimization) メソッドを追加しました。DPO は言語モデルを直接最適化することで動作の正確な制御を実現し、人間の好みを効果的に学習できます。詳細については、リリース v1.5 を参照してください。
[2023/08/08] v1.4 バージョン: ShareGPT4 データセットの微調整に基づく中国語と英語の Vicuna-13B モデル shibing624/vicuna-baichuan-13b-chat と、対応する LoRA モデル shibing624/vicuna をリリースしました。 -baichuan-13b-chat-lora、詳細については、リリース v1.4 を参照してください。
[2023/08/02] v1.3 バージョン: LLaMA、LLaMA2、Bloom、ChatGLM、ChatGLM2、Baichuan モデルのマルチラウンド対話微調整トレーニングを追加、ドメイン語彙拡張機能を追加、中国語の事前トレーニング データ セットを追加しました。中国語 ShareGPT 微調整トレーニング セット、詳細については、リリース v1.3 を参照してください。
[2023/07/13] v1.1 バージョン: Ziya-LLaMA-13B-v1 モデルをベースにした中国医療 LLaMA-13B モデル shibing624/ziya-llama-13b-medical-merged をリリース、SFT が微調整したバージョン医療モデルの質問と回答の効果が改善され、微調整後の完全なモデルの重みが公開されました。 詳細については、Release-v1.1 を参照してください。
[2023/06/15] v1.0 バージョン: 中国の医療 LoRA モデル shibing624/ziya-llama-13b-medical-lora をリリース、Ziya-LLaMA-13B-v1 モデルに基づいて、SFT が医療モデルのバージョンを微調整しました、医療質疑応答の効果が改善され、微調整された LoRA 重みがリリースされました。詳細については、Release-v1.0 を参照してください。
[2023/06/05] バージョン v0.2: 医療を例に挙げると、トレーニング分野の大規模モデルは、二次事前トレーニング、教師あり微調整、報酬モデリング、強化学習トレーニングを含む 4 段階のトレーニングを実装します。 。詳細については、リリース v0.2 を参照してください。
ChatGPT トレーニング パイプラインに基づいて、このプロジェクトはドメイン モデル、つまり医療業界における大規模な言語モデルのトレーニングを実装します。
| モデル | ベースモデル | 導入 |
|---|---|---|
| shibing624/ziya-llama-13b-medical-lora | IDEA-CCNL/Ziya-LLaMA-13B-v1 | SFT は、240 万件の中国語と英語の医療データ セット shibing624/medical に基づいて Ziya-LLaMA-13B モデルのバージョンを微調整しました。医療質疑応答の効果が向上し、LoRA の重みが微調整されました (シングルラウンドの対話)。 )を公開しました。 |
| shibing624/ziya-llama-13b-medical-merged | IDEA-CCNL/Ziya-LLaMA-13B-v1 | SFT は、240 万の中国語と英語の医療データ セット shibing624/medical で Ziya-LLaMA-13B モデルのバージョンを微調整しました。医療質疑応答の効果が向上し、微調整後の完全なモデルの重みがリリースされました。 1 ラウンドの対話) |
| shibing624/vicuna-baichuan-13b-chat-lora | baichuan-inc/baichuan-13B-チャット | SFT は、100,000 の多言語 ShareGPT GPT4 マルチラウンド会話データ セット shibing624/sharegpt_gpt4 および医療データ セット shibing624/medical のバージョンの baichuan-13b-chat マルチラウンド質問と回答モデルを微調整しました。 Q&Aと医療Q&Aが改善され、LoRAウェイトの微調整がリリースされました。 |
| shibing624/vicuna-baichuan-13b-chat | baichuan-inc/baichuan-13B-チャット | SFT は、100,000 の多言語 ShareGPT GPT4 マルチラウンド会話データ セット shibing624/sharegpt_gpt4 および医療データ セット shibing624/medical のバージョンの baichuan-13b-chat マルチラウンド質問と回答モデルを微調整しました。 Q&Aと医療Q&Aを改善し、微調整後の完成モデル重量を公開しました。 |
| shibing624/llama-3-8b-instruct-262k-chinese | ラマ-3-8B-命令-262k | 20,000 の中国語と英語の嗜好データセット shibing624/DPO-En-Zh-20k-Preference で ORPO メソッドを微調整することによって得られた超長文マルチターン対話モデルは、RAG およびマルチターン対話に適しています。 |
shibing624/vicuna-baichuan-13b-chat モデルの効果を実証します。 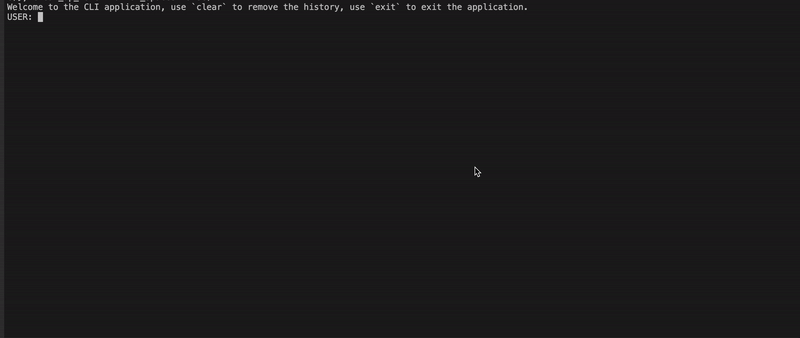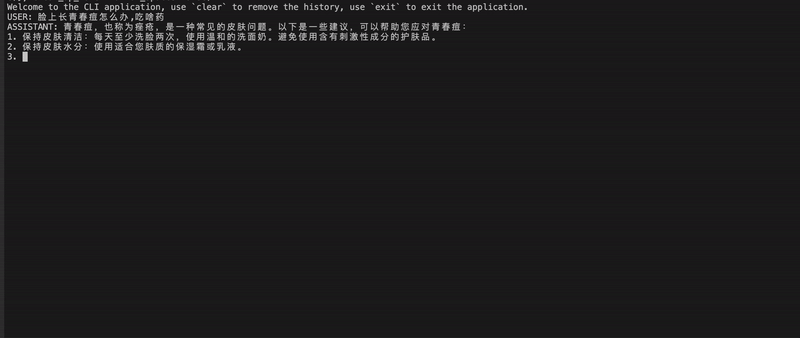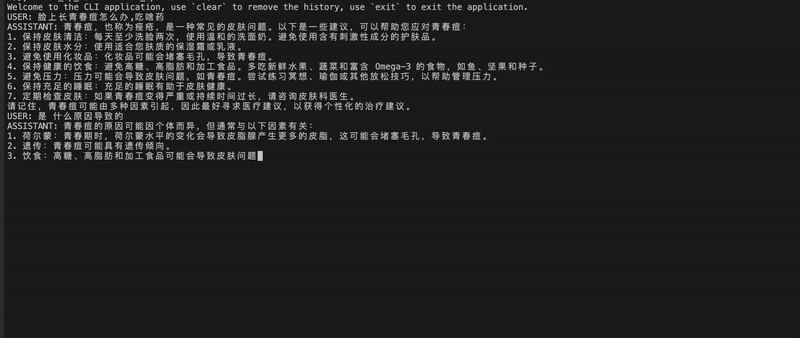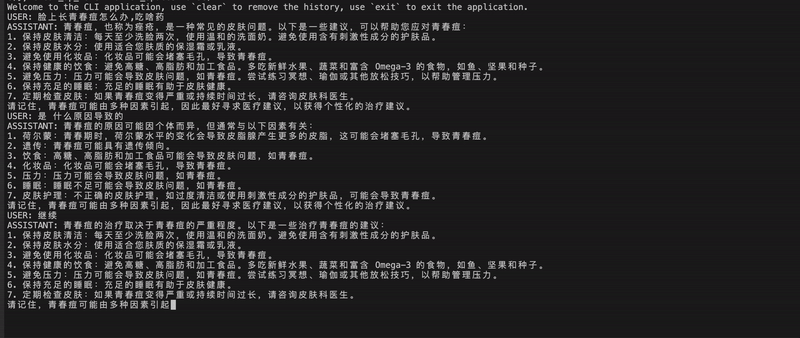 特定のケースについては、「推論の例」を参照してください。
特定のケースについては、「推論の例」を参照してください。
Gradio をベースにしたシンプルなインタラクティブな Web インターフェイスを提供します。サービスを開始したら、ブラウザーからアクセスして質問を入力すると、モデルが回答を返します。
次のコマンドでサービスを開始します。
CUDA_VISIBLE_DEVICES=0 python gradio_demo.py --model_type base_model_type --base_model path_to_llama_hf_dir --lora_model path_to_lora_dirパラメータの説明:
--model_type {base_model_type} : ラマ、ブルーム、チャットグラムなどの事前トレーニングされたモデル タイプ。--base_model {base_model} : LLaMA モデルの重みと構成ファイルを HF 形式で保存するディレクトリ。HF モデル ハブ モデルの呼び出し名も使用できます。--lora_model {lora_model} : LoRA ファイルが配置されているディレクトリ。HF Model Hub モデルの呼び出し名も使用できます。 lora の重みが事前トレーニングされたモデルにマージされている場合は、--lora_model パラメーターを削除します。--tokenizer_path {tokenizer_path} : 対応するトークナイザーが保存されているディレクトリ。このパラメータが指定されていない場合、デフォルト値は --base_model と同じになります。--template_name : テンプレート名 ( vicuna 、 alpacaなど)。このパラメータが指定されていない場合、デフォルト値は vicuna です。--only_cpu : 推論にのみ CPU を使用します--resize_emb : 埋め込みサイズを調整するかどうか。調整しない場合は、事前トレーニングされたモデルの埋め込みサイズを使用します。デフォルトでは調整しません。 requirements.txt最新の機能に適応するために随時更新されます。次のコマンドを使用して依存関係を更新します。
git clone https://github.com/shibing624/MedicalGPT
cd MedicalGPT
pip install -r requirements.txt --upgrade*見積もり
| トレーニング方法 | 正確さ | 7B | 13B | 30B | 70B | 110B | 8x7B | 8x22B |
|---|---|---|---|---|---|---|---|---|
| 完全なパラメータ | AMP(自動混合精度) | 120GB | 240GB | 600GB | 1200GB | 2000GB | 900GB | 2400GB |
| 完全なパラメータ | 16 | 60GB | 120GB | 300GB | 600GB | 900GB | 400GB | 1200GB |
| LoRA | 16 | 16ギガバイト | 32GB | 64GB | 160GB | 240GB | 120GB | 320GB |
| QLoRA | 8 | 10GB | 20GB | 40GB | 80GB | 140GB | 60GB | 160GB |
| QLoRA | 4 | 6GB | 12GB | 24GB | 48GB | 72GB | 30GB | 96GB |
| QLoRA | 2 | 4ギガバイト | 8GB | 16ギガバイト | 24GB | 48GB | 18GB | 48GB |
トレーニング段階:
| ステージ | 導入 | Python スクリプト | シェルスクリプト |
|---|---|---|---|
| 事前トレーニングを継続する | 段階的な事前トレーニング | 事前トレーニング.py | run_pt.sh |
| 監視付き微調整 | 監視付き微調整 | supervised_finetuning.py | run_sft.sh |
| 直接的なプリファレンスの最適化 | 直接的なプリファレンスの最適化 | dpo_training.py | run_dpo.sh |
| 報酬モデリング | 報酬モデルのモデリング | 報酬_モデリング.py | run_rm.sh |
| 強化学習 | 強化学習 | ppo_training.py | run_ppo.sh |
| オルポ | 確率的選好の最適化 | orpo_training.py | run_orpo.sh |
| モデル名 | モデルサイズ | 対象モジュール | テンプレート |
|---|---|---|---|
| 白川 | 7B/13B | W_パック | 白川 |
| バイチュアン2 | 7B/13B | W_パック | バイチュアン2 |
| ブルームズ | 560M/1.1B/1.7B/3B/7.1B/176B | クエリキー値 | ビキューナ |
| チャットGLM | 6B | クエリキー値 | チャットグラム |
| チャットGLM2 | 6B | クエリキー値 | チャットグラム2 |
| チャットGLM3 | 6B | クエリキー値 | チャットグラム3 |
| コヒア | 104B | q_proj、v_proj | 一致する |
| ディープシーク | 7B/16B/67B | q_proj、v_proj | ディープシーク |
| インターンLM2 | 7B/20B | wxya | インターン2 |
| ラマ | 7B/13B/33B/65B | q_proj、v_proj | アルパカ |
| LLaMA2 | 7B/13B/70B | q_proj、v_proj | ラマ2 |
| LLaMA3 | 8B/70B | q_proj、v_proj | ラマ3 |
| ミストラル | 7B/8x7B | q_proj、v_proj | ミストラル |
| オリオン | 14B | q_proj、v_proj | オリオン |
| クウェン | 1.8B/7B/14B/72B | c_attn | クウェン |
| クウェン1.5 | 0.5B/1.8B/4B/14B/32B/72B/110B | q_proj、v_proj | クウェン |
| クウェン2 | 0.5B/1.5B/7B/72B | q_proj、v_proj | クウェン |
| クロスバース | 13B | クエリキー値 | エックスバース |
| イー | 6B/34B | q_proj、v_proj | イー |
トレーニングが完了したら、トレーニングされたモデルをロードし、モデルによって生成されたテキストの効果を検証します。
CUDA_VISIBLE_DEVICES=0 python inference.py
--model_type base_model_type
--base_model path_to_model_hf_dir
--tokenizer_path path_to_model_hf_dir
--lora_model path_to_lora
--interactiveパラメータの説明:
--model_type {base_model_type} : ラマ、ブルーム、チャットグラムなどの事前トレーニングされたモデル タイプ。--base_model {base_model} : LLaMA モデルの重みと設定ファイルを HF 形式で保存するディレクトリ--tokenizer_path {base_model} : LLaMA モデルの重みと設定ファイルを HF 形式で保存するディレクトリ--lora_model {lora_model} : LoRA 解凍されたファイルが配置されているディレクトリ。HF Model Hub モデルの呼び出し名も使用できます。 LoRA 重みが事前トレーニングされたモデルに組み込まれている場合、このパラメーターを指定する必要はありません。--tokenizer_path {tokenizer_path} : 対応するトークナイザーが保存されているディレクトリ。このパラメータが指定されていない場合、デフォルト値は --base_model と同じになります。--template_name : テンプレート名 ( vicuna 、 alpacaなど)。このパラメータが指定されていない場合、デフォルト値は vicuna です。--interactive : ストリーミング推論を使用して、複数ラウンドの Q&A を対話的に開始します。--data_file {file_name} : 非対話モードで開始すると、バッチ予測のために file_name の内容を読み取ります。--output_file {file_name} : 非対話モードでは、予測結果を jsonl 形式で file_name に書き込みます--resize_emb : 埋め込みサイズを調整するかどうか。調整しない場合は、事前トレーニングされたモデルの埋め込みサイズを使用します。デフォルトでは調整しません。--only_cpu : 推論にのみ CPU を使用します--gpus {gpu_ids} : 使用する GPU デバイス番号を指定します。デフォルトは 0 です。複数の GPU を使用する場合は、0、1、2 のようにカンマで区切ります。 マルチカードデータ並列処理、バッチ推論
CUDA_VISIBLE_DEVICES=0,1 torchrun --nproc_per_node 2 inference_multigpu_demo.py --model_type baichuan --base_model shibing624/vicuna-baichuan-13b-chatbash run_Multi-GPUs-deployment.shshibing624/vicuna-baichuan-13b-chat 推論の例:
| 人間 | アシスタント |
|---|---|
| 子供が熱を出した場合の対処法 | 発熱は、感染症やその他の病気に対する体の自然な反応です。発熱の症状を軽減するためのヒントをいくつか紹介します。 1. 水分を補給する: 発熱すると体から水分が失われるため、水分を補給する必要があります。 2. アイスパックを使用する: 額や首にアイスパックを置くと、体温を下げることができます。 3. 解熱剤を使用する: 解熱剤は体温を下げるのに役立ちます。 4. 体温を維持する: 体温を維持すると、体温を下げることができます。 5. 水またはぬるま湯で体を拭く:水またはぬるま湯で体を拭くと、体温を下げることができます。 6. 解熱剤を使用する: 解熱剤は体温を下げるのに役立ちます。 7. 体温を維持する: 体温を維持すると、体温を下げることができます。 8. 水またはぬるま湯で体を拭く:水またはぬるま湯で体を拭くと、体温を下げることができます。 9. 解熱剤を使用する: 解熱剤は体温を下げるのに役立ちます。 10. 体温を維持する: 体温を維持すると、体温を下げることができます。 |
| 1歳の赤ちゃんが発熱した場合に服用できる薬は何ですか? | 1 歳の赤ちゃんが発熱した場合は、次の薬の使用を検討できます。 1. 解熱剤: イブプロフェンやパラセタモールなど。これらの薬は体温を下げ、発熱の症状を和らげるのに役立ちます。 2. 抗生物質: 発熱が細菌感染によって引き起こされている場合は、抗生物質の投与が検討されることがあります。ただし、必ず医師の指導のもとでご使用ください。 3. 抗ウイルス薬: 発熱がウイルス感染によって引き起こされている場合は、抗ウイルス薬の使用が検討されることがあります。ただし、必ず医師の指導のもとでご使用ください。 4. 解熱鎮痛薬:アスピリンやパラセタモールなど。これらの薬は発熱の症状を軽減するのに役立ちます。 5. 抗ヒスタミン薬: ジフェンヒドラミンまたはフェキソフェナジン (ナプロキセン) など。これらの薬は発熱の症状を軽減するのに役立ちます。 これらの薬は必ず医師の指導の下、添付文書に記載されている用法用量に従って使用してください。同時に、赤ちゃんに十分な水分を与え、十分な休息を確保してください。 |
| 肛門病変はどのような病気の症状である可能性がありますか | 肛門病変は、感染、炎症、腫瘍、その他の疾患など、さまざまな原因によって引き起こされる可能性があります。一般的な肛門病変には次のようなものがあります。 1. 裂肛: これは肛門の皮膚の裂傷で、通常は便秘やその他のストレス要因によって引き起こされます。 2. 痔瘻:これは、肛門の皮膚と直腸の間に瘻孔が形成される肛門感染症です。 3. 肛門いぼ:これは肛門の皮膚に形成されるいぼのような病変で、通常はヒトパピローマウイルス(HPV)によって引き起こされます。 4. 肛門膿瘍:これは、肛門の皮膚の下に膿瘍が形成される肛門感染症です。 5. 肛門腫瘍:肛門の皮膚や直腸にできる腫瘍です。 6. 肛門潰瘍: これは肛門の皮膚に形成される潰瘍で、通常は感染または炎症によって引き起こされます。 7. 肛門のかゆみ:これは肛門の皮膚のかゆみの症状であり、感染、炎症、または他の病気によって引き起こされる可能性があります。 肛門病変の症状がある場合は、適切な診断と治療について医療専門家に相談してください。 |
| こんにちは、先生、帯下が増えて黄色くなっているのはなぜですか? | こんにちは、黄色がかったおりものの増加は、感染症、ホルモンの変化、膣の乾燥、その他の婦人科系の問題など、さまざまな理由によって引き起こされる可能性があります。考えられる理由は次のとおりです。 1. 感染症: 膣分泌物の増加と黄色がかったおりものは、膣または尿路の感染症によって引き起こされる可能性があります。感染症は細菌、ウイルス、真菌によって引き起こされる可能性があります。 2. ホルモンの変化: 月経周期や閉経などのホルモンの変化により、おりものが増加し、黄色くなることがあります。 3. 膣の乾燥:膣の乾燥により、おりものが増加し、黄色くなることがあります。 4. その他の婦人科疾患: 子宮頸管炎、子宮内膜炎、子宮内膜症などの他の婦人科疾患も、黄色のおりものの増加を引き起こす可能性があります。 帯下が心配な場合は、婦人科医に検査と診断を依頼することをお勧めします。医師はあなたの症状と検査結果に基づいて原因を特定し、適切な治療を提供します。 |
| 薬による中絶後にチョコレート帯下が発生した場合、それは中絶が不潔だからでしょうか? | 薬による中絶後にチョコレート帯下が発生したとしても、必ずしも中絶が不潔であったことを意味するわけではありません。チョコレート白帯下は子宮内膜の脱落と出血によって引き起こされ、通常は薬による中絶後の一定期間内に発生します。 薬による中絶後のチョコレート帯下には次のような原因が考えられます。 1. 子宮内膜の脱落:薬による中絶後、子宮内膜が脱落し、出血が起こります。この出血はチョコレート帯下として現れる場合があります。 2. 感染症:薬による中絶後は、子宮内膜や子宮頸部に外傷があり、細菌感染しやすくなっている可能性があります。感染するとチョコレートの膣分泌物が発生することがあります。 3. ホルモンレベルの変化:薬による中絶後、ホルモンレベルが変化し、チョコレート性帯下を引き起こす可能性があります。 チョコレート帯下が長期間続く場合、または腹痛、発熱、分泌物の独特の臭いなどの他の症状を伴う場合は、早めに医師の診察を受け、婦人科検診などの関連検査を受けることをお勧めします。 B超音波検査などにより、感染症やその他の問題があるかどうかを判断します。医師の指導のもと、適切な治療を行ってください。 |
| ビタミンEクリームはどのような病気を治療できますか? | ビタミンEクリームは、主にニキビや脂漏性皮膚炎などの皮膚疾患の治療に使用される外用薬です。皮脂の生成を抑え、炎症を軽減し、皮膚の修復を促進します。 ビタミンEクリームは万能薬ではないため、特定の皮膚疾患には適さない場合があることに注意してください。ご使用前に医師または薬剤師に相談し、適応症、禁忌、用法・用量などをご理解いただくことをお勧めします。同時に、薬物を使用する場合は医師の指示に従って、自己流の乱用を避ける必要があります。 |
| ニキビの原因は何ですか? | 面皰としても知られるニキビは、皮膚の毛穴の詰まりによって引き起こされます。毛穴の詰まりには次のようなさまざまな原因があります。 1. 過剰な皮脂腺: 皮脂腺は過剰な油を生成し、毛穴の詰まりを引き起こします。 2. 毛穴の詰まり:皮膚表面の死んだ皮膚細胞、油分、細菌が毛穴を詰まらせます。 3. 炎症:ニキビには炎症が伴うことが多く、皮膚感染症やニキビに対する免疫系の反応によって引き起こされる場合があります。 4. 遺伝的要因: おそらく遺伝的要因により、ニキビができやすい人もいます。 5. ホルモンの変化: ニキビは思春期や月経期によく発生しますが、これはホルモンの変化によって引き起こされる可能性があります。 6. ライフスタイル要因: ストレス、偏った食事、運動不足などの特定のライフスタイル要因もニキビの原因となる可能性があります。 7. 化粧品およびスキンケア製品: 特定の化粧品およびスキンケア製品、特に刺激性の成分を含むものはニキビの原因となる可能性があります。 8. 薬: 経口避妊薬などの特定の薬もニキビの原因となる可能性があります。 ニキビを予防するには、肌を清潔に保つ、刺激の少ないスキンケア製品を使用する、化粧品やスキンケア製品の過剰な使用を避ける、健康的なライフスタイルと食生活を維持する、ストレスやホルモンの変化を避けるなどの対策を講じることができます。ニキビがひどい場合は、皮膚科医の助けを求める必要があるかもしれません。 |
| 顔にニキビができた場合の対処法、飲める薬、注意点は? | 座瘡としても知られる座瘡は、一般的な皮膚疾患です。ニキビの治療には食事、生活習慣、薬などさまざまな面を総合的に考慮する必要があります。以下にいくつかの提案を示します。 1. 食事: ※ファストフード、デザート、揚げ物など糖分、脂肪分、油分を多く含む食べ物は避けてください。 * 繊維の摂取量を増やし、腸の蠕動運動を促進するために、より多くの新鮮な野菜、果物、全粒穀物を食べてください。 ※カフェイン、アルコール、辛い食べ物、その他刺激の強い食べ物の過剰摂取は避けてください。 2. 生活習慣: * 適切な睡眠スケジュールを維持し、十分な睡眠を確保してください。 ※皮膚への放射線刺激を避けるため、パソコンや携帯電話などの電子製品の長時間使用は避けてください。 * 肌を清潔に保ち、毎日朝晩、刺激の少ない洗顔料を使用してください。 *感染や傷跡を避けるために、ニキビを圧迫しないようにしてください。 3. 薬物: * 局所薬: サリチル酸、安息香酸、アゼライン酸などの成分を含むスキンケア製品を使用すると、皮膚表面の死んだ皮膚細胞を除去し、ニキビの形成を減らすことができます。 ※内服薬:ニキビがひどい場合には、抗生物質の内服やビタミンB群、亜鉛などが考えられますが、医師の指導の下で使用する必要があります。 4. 注: ※肌への刺激を避けるため、化粧品やスキンケア製品をむやみに使用しないでください。 ※肌バリアを傷つけないように、肌を過剰に洗浄しないでください。 * 気分を快適に保ち、不安や憂鬱などのネガティブな感情を避けます。 つまり、ニキビの治療は食事、生活習慣、薬など多くの面を総合的に考慮する必要があるのです。治療の過程では、忍耐強く自信を持って医師の推奨に従い、徐々に皮膚の状態を改善してください。 |
| 精管の詰まりは男性不妊の原因になりますか?こんにちは、先生、私の同僚が最近機嫌が悪いのですが、どうしたのかと尋ねると、夫の精管が詰まっているので、子供を産みたくないということではありませんでした。精液が男性不妊の原因? | 精管の閉塞は男性不妊の原因となる可能性があります。精管は睾丸と尿道を繋ぎ、精子を睾丸から尿道まで運ぶ管です。精管が詰まると精子が精管を通って尿道に到達できなくなり、不妊症の原因となります。 精管の閉塞には、先天性発育異常、炎症、腫瘍、外傷など、さまざまな理由があります。精管閉塞の治療法には、外科的な閉塞の解除と薬物治療があります。精管が重度に閉塞している場合は、それを除去するために手術が必要になる場合があります。 精子を女性の体内に運ぶ他の方法があるため、精管の閉塞が必ずしも不妊症につながるわけではないことに注意することが重要です。たとえば、精子は精巣上体や前立腺などの組織を通って女性の体に到達します。したがって、精管が詰まった場合は、すぐに治療を受け、専門の医師の助けを求めることをお勧めします。 |
| 心筋梗塞は治療できるのでしょうか? | 心筋梗塞は重篤な状態であり、迅速に治療すれば命を救い、長期にわたる障害を防ぐことができます。心筋梗塞の治療の鍵は、早期発見と治療です。 心筋梗塞の治療には通常、次の手順が含まれます。 1. 直ちに医師の診察を受けてください。胸痛、息切れ、失神などの症状が現れた場合は、直ちに医師の診察を受けてください。 2. 薬物療法: 症状を緩和し、さらなる損傷を防ぐために、医師はニトログリセリンやアスピリンなどの薬物を処方する場合があります。 3. 血栓溶解療法: 患者が病院に到着する前に心筋梗塞を起こした場合、医師は血栓を溶解して血流を回復する薬を注射する血栓溶解療法を実行することがあります。 4. 外科的治療: 薬物療法や血栓溶解療法が失敗した場合、医師は冠動脈バイパス手術や心臓ステント移植などの外科手術を推奨する場合があります。 5. リハビリテーションと予防: 心筋梗塞の治療には、患者が身体機能を回復し、将来の心臓イベントを予防するためのリハビリテーション プログラムが含まれることがよくあります。さらに、患者は心臓病のリスクを軽減するために医師の推奨に従う必要があります。 心筋梗塞の治療は患者の特定の状態や症状によって異なることに注意することが重要です。したがって、あなたまたはあなたの知人が心筋梗塞の症状を発症した場合は、すぐに医師の診察を受けてください。 |
| 自分を元気に保つ方法、5つの提案をご紹介します | 1. 十分な睡眠をとる: 睡眠はエネルギーレベルを高く保つために非常に重要です。毎晩7〜9時間の質の高い睡眠をとるようにしてください。 2. バランスの取れた食事を摂る:エネルギーレベルを維持するには、バランスの取れた食事が不可欠です。タンパク質、炭水化物、健康的な脂肪を十分に摂取するようにしてください。 3. 定期的に運動する: 定期的に運動すると、エネルギー レベルが高まります。ウォーキング、ランニング、サイクリングなどの有酸素運動を毎日少なくとも 30 分間行うようにしましょう。 4. ストレスを管理する: ストレスはエネルギーを消耗するため、エネルギーレベルを高く保つにはストレスを管理することが重要です。瞑想、ヨガ、深呼吸など、リラックスしてストレスを軽減する方法を見つけてください。 5. 水分補給を続ける:脱水症状によりエネルギーレベルが低下する可能性があります。毎日十分な量の水を飲み、必要に応じて水分補給するようにしてください。 |
| 春の詩を書こう | 春、 地球が目覚める季節です 万物復活の季節です 生命が花開く季節です。 春、 晴れの季節ですね、 鳥のさえずり、花の香りの季節です。 新緑の季節ですね、 無限の希望の季節です。 春、 人が笑う季節です 子どもたちが遊ぶ季節ですので、 恋人たちが抱き合う季節です 人々が夢を追いかける季節です。 |
| なぜ南極にはホッキョクグマがいないのでしょうか? | 南極大陸にホッキョクグマがいないのは、ホッキョクグマは北極圏に生息しているのに対し、南極大陸は南半球に位置し、北極圏とは気候や環境が大きく異なるためです。南極大陸は非常に寒冷な気候で、一年中氷と雪に覆われていますが、北極にはホッキョクグマが生息しており、海洋生物や陸上哺乳類が豊富に生息しています。さらに、南極の生態系は北極とは異なり、ホッキョクグマが必要とする生存条件を備えていません。 |


このプロジェクトは研究目的でのみ使用でき、プロジェクト開発者は、このプロジェクトの使用によって引き起こされる損害や損失(データ、モデル、コードなどを含みますがこれらに限定されません)に対して責任を負いません。詳細については免責事項をご覧ください。
MedicalGPT プロジェクト コードのライセンス契約は Apache License 2.0 です。コードは商用目的で無料で使用でき、モデルの重みとデータは研究目的でのみ使用できます。 MedicalGPT へのリンクと使用許諾契約を製品説明に添付してください。
研究で MedicalGPT を使用する場合は、次の形式で引用してください。
@misc{MedicalGPT,
title={MedicalGPT: Training Medical GPT Model},
author={Ming Xu},
year={2023},
howpublished={ url {https://github.com/shibing624/MedicalGPT}},
}プロジェクトのコードはまだ非常にラフです。コードに改善点があれば、このプロジェクトに提出してください。提出する前に、次の 2 つの点に注意してください。
testsに追加するpython -m pytest使用してすべての単体テストを実行し、すべての単体テストが合格することを確認します。その後、PR を送信できます。
彼らの素晴らしい仕事に感謝します!


