spelltest
v0.0.4
?このプロジェクトが役立つと思われる場合は、スターを付けることを検討してください。あなたのサポートが私にそれを改善し続ける動機を与えます! ?
今日の AI 駆動型アプリケーションは、革新的なソリューションを提供するために GPT-4 などの大規模言語モデル (LLM) に大きく依存しています。ただし、あらゆる状況で適切かつ正確な応答を提供することを保証するのは困難です。 Spelltest は、合成ユーザー ペルソナとこれらの応答を自動的に評価する評価手法を使用して LLM 応答をシミュレートすることでこの問題に対処します (ただし人間の監督は必要です)。
spellforge.yamlファイルにシミュレーションを記述します。 project_name : ...
# describe users
users :
...
# describe quality metrics
metrics :
...
# describe prompts of your LLM app
prompts :
...
# finally describe simulations
simulations :
...

Google Colab を介して、Web ベースのインタラクティブ環境でこのプロジェクトを試すことができるようになりました。インストールは必要ありません。
上のバッジをクリックして始めてください。
保証された品質: 最適な応答を得るためにユーザー インタラクションをシミュレートします。
効率と節約: 手動テストのコストを節約します。
スムーズなワークフロー統合: 開発プロセスにシームレスに適合します。
これは Spelltest の非常に初期のバージョンであることに注意してください。そのため、さまざまな環境やユースケースでの広範なテストはまだ行われていません。このバージョンの使用を決定すると、Spelltest フレームワークをご自身の責任で使用することに同意したものとみなされます。プロジェクトの改善に役立てるため、発生した問題やバグを報告することをユーザーに強くお勧めします。
運用コストに関しては、Spelltest でシミュレーションを実行すると、OpenAI API の使用量に基づいて料金が発生することに注意することが重要です。現時点では、コストの見積もりや予算の制限はありません。コンテキストとして、100 個のシミュレーションのバッチを実行すると、特定の LLM やシミュレーションの複雑さなどのいくつかの要因に応じて、約 0.7 ドルから 1.8 ドル (gpt-3.5-turbo) の費用がかかる場合があります。
これらのコストを考慮すると、初期コストを抑え、将来の費用をより正確に見積もるために、少ない数のシミュレーションから始めることを強くお勧めします。フレームワークとそのコストへの影響に慣れるにつれて、予算とニーズに応じてシミュレーションの数を調整できます。
Spelltest の目標は、AI の開発とテストのプロセスにおいて可能な限りコスト効率を維持しながら、LLM からの高品質な応答を保証することであることを忘れないでください。

Spelltest は、品質保証に対して独特のアプローチを採用しています。合成ユーザー ペルソナを使用することで、インタラクションをシミュレートするだけでなく、ユーザーの独自の期待も取り込み、コンテキストが豊富なテスト環境を提供します。このコンテキストの深さにより、現実世界のアプリケーションを忠実に反映した方法で LLM 応答の品質を評価できるようになります。
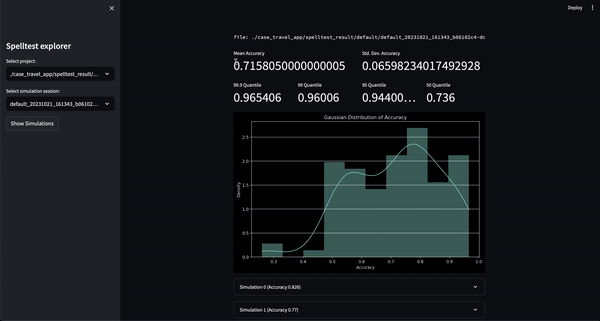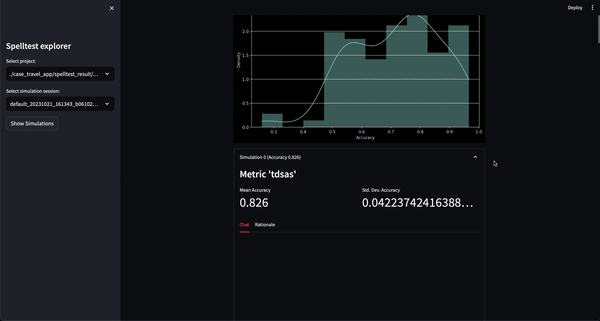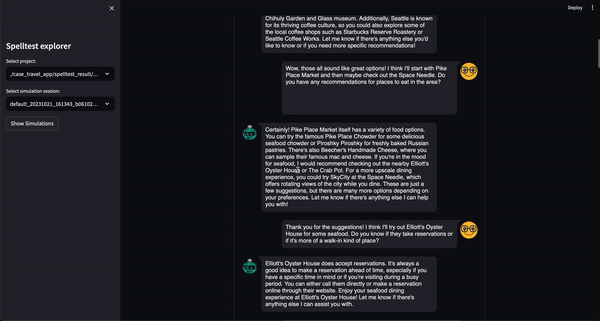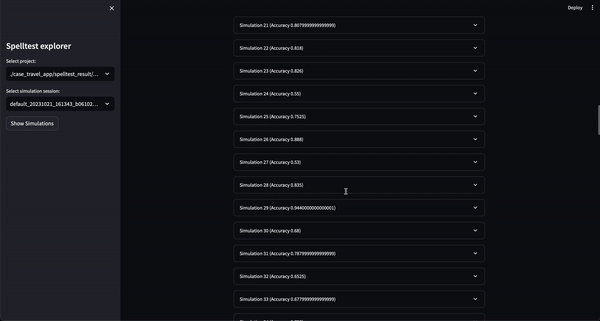
結果? 0.0 から 1.0 の範囲の品質スコア。アプリが実際のユーザーに出会う前の総合的な予行演習として機能します。チャット モードでも完了モードでも、Spelltest は LLM 応答がユーザーの期待と厳密に一致していることを確認し、全体的なユーザー満足度を向上させます。
pip を使用してフレームワークをインストールします。
pip install spelltest.spellforge.yamlは Spelltest の中心であり、合成ユーザー プロファイル、メトリクス、プロンプト、シミュレーションが含まれています。以下はその構造の内訳です。
合成ユーザーは現実世界のユーザーを模倣し、それぞれがアプリに対する独自の背景、期待、理解を持っています。合成ユーザーの構成には次が含まれます。
サブ プロンプト: これらは、ユーザー プロファイルにコンテキストを提供する説明的な要素です。それらには次のものが含まれます。
description : 合成ユーザーに関する概要。expectation : ユーザーがインタラクションに期待するもの。user_knowledge_about_app : アプリの精通度。各合成ユーザーには次のものも含まれます。
name : 合成ユーザーの識別子。llm_name : 使用する LLM モデル (OpenAI モデルのみでテスト済み)。temperature : ...合成ユーザー構成の例:
...
nomad :
name : " Busy Nomad in Seattle "
llm_name : gpt-3.5-turbo
temperature : 0.7
description : " You're a very busy nomad who struggles with planning. You're moved to Seattle and looking at how to spend your first Saturday exploring the city "
expectation : " Well-planned objective, detailed, and comprehensive schedule that meets user's requirements "
user_knowledge_about_app : " The app receives text input about travel requirements (i.e., place, preferences, short description of the family and their interests) and returns a travel schedule that accommodates all family members’ needs and interests. "
metrics : __all__
...メトリクスは、LLM の応答を評価してスコアリングするために使用されます。各メトリクスには、メトリクスが評価する内容のコンテキストを提供するサブ プロンプトのdescriptionが含まれています。
単純なメトリック構成の例:
...
metrics :
accuracy :
description : " Accuracy "
...複雑/カスタム メトリック構成の例:
...
metrics :
tpas :
description : " TPAS - The Travel Plan Accuracy Score. This metric measures the accuracy of the generated response by evaluating the inclusion of the expected output, well-scheduled travel plan and nothing else. The TPAS is a numerical value between 0 and 100, with 100 representing a perfect match to the expected output and 0 indicating non-accurate result. "
...プロンプトは、アプリが提示する質問またはタスクです。これらは、LLM が適切な応答を生成する能力をテストするためにシミュレーションで使用されます。各プロンプトは、 descriptionと実際のpromptテキストまたはタスクで定義されます。
...
prompts :
book_flight :
file : book-flight-prompt.txt
...シミュレーションはテスト シナリオを指定します。主要な要素には、 prompt 、 users 、 llm_name 、 temperature 、 size 、 chat_mode 、およびquality_thresholdが含まれます。
project_name : " Travel schedule app "
# describe users
users :
nomad :
name : " Busy Nomad in Seattle "
llm_name : gpt-3.5-turbo
temperature : 0.7
description : " You're a very busy nomad who struggles with planning. You're moved to Seattle and looking at how to spend your first Saturday exploring the city "
expectation : " Well-planned objective, detailed, and comprehensive schedule that meets user's requirements "
user_knowledge_about_app : " The app receives text input about travel requirements (i.e., place, preferences, short description of the family and their interests) and returns a travel schedule that accommodates all family members’ needs and interests. "
metrics : __all__
family_weekend :
name : " The Adventurous Family from Chicago "
llm_name : gpt-3.5-turbo
temperature : 0.7
description : " You're a family of four (two adults and two children) based in Chicago looking to plan an exciting, yet relaxed weekend getaway outside the city. The objective is to explore a new environment that is kid-friendly and offers a mix of adventure and downtime. "
expectation : " A balanced travel schedule that combines fun activities suitable for children and relaxation opportunities for the entire family, considering travel times and kid-friendly amenities. "
user_knowledge_about_app : " The app receives text input about travel requirements (i.e., place, preferences, short description of the family and their interests) and returns a travel schedule that accommodates all family members’ needs and interests. "
metrics : __all__
retired_couple :
name : " Retired Couple Exploring Berlin "
llm_name : gpt-3.5-turbo
temperature : 0.7
description : " You're a retired couple from the US, wanting to explore Berlin and soak in its rich history and culture over a 10-day vacation. You’re looking for a mixture of sightseeing, cultural experiences, and leisure activities, with a comfortable pace suitable for your age. "
expectation : " A comprehensive travel plan that provides a relaxed pace, ensuring enough time to explore and enjoy each location, and includes historical and cultural experiences. It should also consider comfort and accessibility. "
user_knowledge_about_app : " The app accepts text input detailing travel requirements (i.e., destination, preferences, duration, and a brief description of travelers) and returns a well-organized travel itinerary tailored to those specifics. "
metrics : __all__
# describe quality metrics
metrics :
tpas : # name of your metric
description : " TPAS - The Travel Plan Accuracy Score. This metric measures the accuracy of the generated response by evaluating the inclusion of the expected output, well-scheduled travel plan and nothing else. The TPAS is a numerical value between 0 and 100, with 100 representing a perfect match to the expected output and 0 indicating non-accurate result. "
# describe prompts
prompts :
smart-prompt :
file : ./smart-prompt # expected that prompt located in this file
# finally describe simulations
simulations :
test1 :
prompt : smart-prompt
users : __all__
llm_name : gpt-3.5-turbo
temperature : 0.7
size : 5
chat_mode : true # completion mode if `false`
quality_threshold : 80
プロンプトファイルを含む完全な設定はここにあります。
OpenAI のコスト: このフレームワークを使用すると、特に大規模なシミュレーションを実行する場合、OpenAI への大量のリクエストが発生する可能性があります。これにより、OpenAI アカウントに多額のコストがかかる可能性があります。 OpenAI の予算に留意し、価格モデルを理解してください。発生した費用については一切の責任を負いません。
早期リリース: このバージョンの Spelltest は初期段階にあり、安定性の保証はありません。慎重に使用していただき、お気軽にフィードバックを提供したり、問題を報告したりしてください。
export OPENAI_API_KEYS= < your api keys >
spelltest --config_file .spellforge.yamlシミュレーションの結果を確認します。
spelltest --analyzeSpelltest をリリース パイプラインに統合すると、一貫した自動テストが組み込まれ、導入戦略が強化されます。この重要な手順により、リリース前にユーザー インタラクションを系統的にシミュレートおよび評価することで、LLM ベースのアプリケーションが高水準の品質を維持できるようになります。これにより、時間を大幅に節約し、手動エラーを減らし、変更や新機能がユーザー エクスペリエンスにどのような影響を与えるかについて重要な洞察を得ることができます。
このガイドでは、プロジェクトの継続的インテグレーションを設定および自動化するプロセスについて説明します。
始める前に、次の前提条件が満たされていることを確認してください。
プロジェクトを含む GitHub リポジトリ。
API キーを使用して SpellForge にアクセスします。お持ちでない場合は、SpellForge Web サイトから入手できます。
OpenAI サービスを使用するための OpenAI API キー。お持ちでない場合は、OpenAI Web サイトから入手できます。
.spellforge.yamlを作成して構成するプロジェクトのルート ディレクトリに.spellforge.yamlファイルを作成します。このファイルには Spelltest の手順が含まれます。
GitHub Actions ワークフロー ファイル (例: .github/workflows/.spelltest.yaml) を作成して、SpellForge テストを自動化します。このファイルに次のコードを挿入します。
# .spelltest.yaml
name : Spelltest CI
on :
push :
branches : [ "main" ]
env :
SPELLTEST_CONFIG_PATH : ${{ env.SPELLTEST_CONFIG_PATH }}
OPENAI_API_KEY : ${{ secrets.OPENAI_API_KEY }}
jobs :
test :
runs-on : ubuntu-latest
steps :
- uses : actions/checkout@v3
- name : Install SpellTest library
run : pip install spelltest
- name : Run tests
run : spelltest --config_file $SPELLTEST_CONFIG_PATHこのワークフローは、メイン ブランチにプッシュされるたびにトリガーされ、SpellForge テストを実行します。
GitHub リポジトリに移動し、[設定] タブに移動します。
「シークレット」の下に 2 つの新しいシークレットを追加します。
OPENAI_API_KEY : このシークレットを OpenAI API キーに設定します。
GitHub 環境変数を追加します。
SPELLTEST_CONFIG_PATH : この変数を、リポジトリ内の .spellforge.yaml ファイルへのフル パスに設定します。
これらは、特定の特性と期待を伴う実際のユーザーのインタラクションをシミュレートしています。
ユーザーの背景( .spellforge.yamlのdescriptionフィールド): この合成ユーザーが誰であるか、およびアプリを使用して解決したい問題 (スケジュールを管理する旅行者など) の概要を提供するサブ プロンプト。
ユーザーの期待( expectationフィールド): アプリの使用による成功したインタラクションまたはソリューションとして合成ユーザーが何を期待するかを定義するサブ プロンプト。
環境認識( user_knowledge_about_appフィールド): 合成ユーザーがアプリケーションのコンテキストを理解し、現実的なテスト シナリオを保証するサブ プロンプト。
シミュレーションで LLM によって生成された応答を評価およびスコアリングするために使用される標準または基準を表すサブ プロンプト。メトリクスは、一般的な測定値から、よりアプリケーション固有のカスタム メトリクスまで多岐にわたります。
一般的なメトリクスの例:
意味的類似性: 提供された回答が意味の点で期待される回答にどの程度似ているかを測定します。
毒性: 不適切または有害とみなされる可能性のある言語またはコンテンツに対する反応を評価します。
構造的類似性: 生成された応答の構造と形式を、事前定義された標準または予期される出力と比較します。
その他のカスタム メトリクスの例:
TPAS (旅行計画精度スコア) : 「この指標は、予想される成果の包含と提案された旅行計画の品質を評価することによって、生成された応答の精度を測定します。TPAS は 0 ~ 100 の数値で、100 は完璧を表します。は期待される出力と一致し、0 は不正確な結果を示します。」
EES (共感エンゲージメント スコア) : 「EES は、LLM の応答の共感的な共鳴を評価します。メッセージ内の理解、検証、および支援要素を評価することにより、伝わった共感レベルをスコア化します。EES の範囲は 0 ~ 100 で、100 は共感度を示します。非常に共感的な反応である一方、0 は共感的な関与の欠如を示します。」
Spelltest を使用して LLM ベースのアプリケーションを改善しましょう。


