datablations
1.0.0
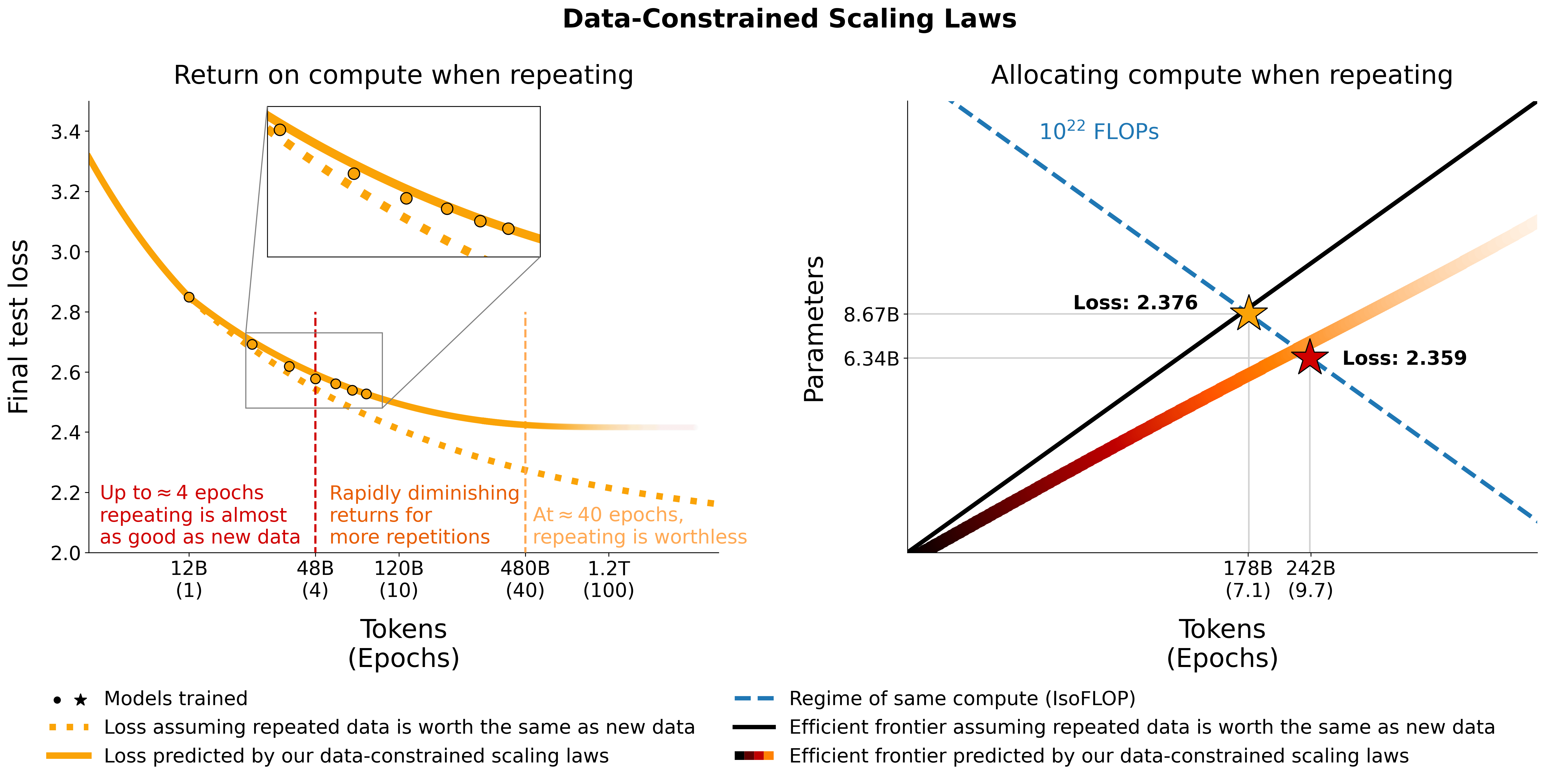
このリポジトリは、論文「Scaling Data-Constrained Language Models」のすべてのコンポーネントの概要を提供します。紙面での講演:
データ制約のある領域におけるスケーリング言語モデルを調査します。私たちは、最大 9,000 億のトレーニング トークンと 90 億のパラメーター モデルに及ぶ、データ繰り返しの範囲と計算予算を変化させる大規模な実験セットを実行します。実行に基づいて、繰り返されるトークンと過剰なパラメーターの値の減少を考慮した計算最適性のスケーリング則を提案し、経験的に検証します。また、トレーニング データセットをコード データで強化したり、パープレキシティ フィルタリングや重複排除など、データ不足を軽減するアプローチも実験しています。 400 回のトレーニング実行からのモデルとデータセットは、このリポジトリから入手できます。
C4 上の繰り返しデータと、OSCAR の重複排除されていない英語の分割を実験します。データセットごとに、データをダウンロードし、それぞれc4.jsonlとoscar_en.jsonlという単一の jsonl ファイルに変換します。
次に、一意のトークンの量と、データセットから必要なサンプルのそれぞれの数を決定します。 GPT2Tokenizer を使用すると、C4 にはサンプルあたり478.625834583トークンがあり、OSCAR には1312.0951072があることに注意してください。これは、データセット全体をトークン化し、トークン数をサンプル数で割ることによって計算されました。これらの数値を使用して、必要なサンプルを計算します。
たとえば、1.9B の一意のトークンの場合、C4 には1.9B / 478.625834583 = 3969697.96178サンプル、OSCAR には1.9B / 1312.0951072 = 1448065.76107サンプルが必要です。データをトークン化するには、まず Megatron-DeepSpeed リポジトリのクローンを作成し、そのセットアップ ガイドに従う必要があります。次に、これらのサンプルを選択し、次のようにトークン化します。
C4:
head -n 3969698 c4.jsonl > c4_1b9.jsonl
python Megatron-DeepSpeed/tools/preprocess_data_many_cores.py
--input c4_1b9.jsonl
--output-prefix gpt2tok_c4_en_1B9
--dataset-impl mmap
--tokenizer-type PretrainedFromHF
--tokenizer-name-or-path gpt2
--append-eod
--workers 64オスカー:
head -n 1448066 oscar_en.jsonl > oscar_1b9.jsonl
python Megatron-DeepSpeed/tools/preprocess_data_many_cores.py
--input oscar_1b9.jsonl
--output-prefix gpt2tok_oscar_en_1B9
--dataset-impl mmap
--tokenizer-type PretrainedFromHF
--tokenizer-name-or-path gpt2
--append-eod
--workers 64ここで、 gpt2 、https://huggingface.co/gpt2/tree/main のすべてのファイルを含むフォルダーを指します。 head使用することで、ランダム性を軽減するために、異なるサブセットに重複するサンプルが含まれるようになります。
トレーニング中の評価と最終評価には、C4 の検証セットを使用します。
from datasets import load_dataset
load_dataset ( "c4" , "en" , split = "validation" ). to_json ( "c4-en-validation.json" )python Megatron-DeepSpeed/tools/preprocess_data_many_cores.py
--input c4-en-validation.jsonl
--output-prefix gpt2tok_c4validation_rerun
--dataset-impl mmap
--tokenizer-type PretrainedFromHF
--tokenizer-name-or-path gpt2
--append-eod
--workers 2公式の検証セットがない OSCAR の場合、 tail -364608 oscar_en.jsonl > oscarvalidation.jsonl実行してトレーニング セットの一部を取得し、次のようにトークン化します。
python Megatron-DeepSpeed/tools/preprocess_data_many_cores.py --input oscarvalidation.jsonl --output-prefix gpt2tok_oscarvalidation --dataset-impl mmap --tokenizer-type PretrainedFromHF --tokenizer-name-or-path gpt2 --append-eod --workers 2メガトロンで使用するために、いくつかの前処理されたサブセットをアップロードしました。
一部の bin ファイルは git には大きすぎるため、 split --number=l/40 gpt2tok_c4_en_1B9.bin gpt2tok_c4_en_1B9.bin. split --number=l/40 gpt2tok_oscar_en_1B9.bin gpt2tok_oscar_en_1B9.bin. 。これらをトレーニングに使用するには、 cat gpt2tok_c4_en_1B9.bin.* > gpt2tok_c4_en_1B9.binとcat gpt2tok_oscar_en_1B9.bin.* > gpt2tok_oscar_en_1B9.binを使用して、それらを再度 cat する必要があります。
the-stack-dedup から分割された Python を使用して、コードと自然言語データを混合する実験を行います。データをダウンロードし、それを単一の jsonl ファイルに変換し、上で概説したのと同じアプローチを使用して前処理します。
メガトロンで使用するための前処理バージョンをここにアップロードしました: https://huggingface.co/datasets/datablations/python-megatron。 split --number=l/40 gpt2tok_python_content_document.bin gpt2tok_python_content_document.bin.したがって、トレーニングのためにcat gpt2tok_python_content_document.bin.* > gpt2tok_python_content_document.bin使用して、それらをもう一度まとめて猫にする必要があります。
パープレキシティおよび重複排除関連のフィルタリング メタデータを使用して、C4 および OSCAR のバージョンを作成します。
これらのメタデータ データセットを再作成するにはfiltering/README.mdに手順があります。
Megatron のトレーニングに使用できるトークン化されたバージョンを次の場所で提供します。
.binファイルはsplit --number=l/10 gpt2tok_oscar_en_perplexity_25_text_document.bin gpt2tok_oscar_en_perplexity_25_text_document.bin.したがって、 cat gpt2tok_oscar_en_perplexity_25_text_document.bin. > gpt2tok_oscar_en_perplexity_25_text_document.bin 。
メタデータ データセットを指定してトークン化されたバージョンを再作成するには、
filtering/deduplication/filter_oscar_jsonl.pyを参照してください。困惑パーセンタイルを作成するには、以下の手順に従ってください。
C4:
from datasets import load_dataset
import numpy as np
ds = load_dataset ( "datablations/c4-filter" , streaming = False , num_proc = 128 )
p_25 = np . percentile ( ds [ "train" ][ "perplexity" ], 25 )
p_50 = np . percentile ( ds [ "train" ][ "perplexity" ], 50 )
p_75 = np . percentile ( ds [ "train" ][ "perplexity" ], 75 )
# 25 - 75th percentile
ds [ "train" ]. filter ( lambda x : p_25 < x [ "perplexity" ] < p_75 , num_proc = 128 ). to_json ( "c4_perplexty2575.jsonl" , num_proc = 128 , force_ascii = False )
# 25th percentile
ds [ "train" ]. filter ( lambda x : x [ "perplexity" ] < p_25 , num_proc = 128 ). to_json ( "c4_perplexty25.jsonl" , num_proc = 128 , force_ascii = False )
# 50th percentile
ds [ "train" ]. filter ( lambda x : x [ "perplexity" ] < p_50 , num_proc = 128 ). to_json ( "c4_perplexty50.jsonl" , num_proc = 128 , force_ascii = False )オスカー:
from datasets import load_dataset
import numpy as np
ds = load_dataset ( "datablations/oscar-filter" , use_auth_token = True , streaming = False , num_proc = 128 )
p_25 = np . percentile ( ds [ "train" ][ "perplexity_score" ], 25 )
p_50 = np . percentile ( ds [ "train" ][ "perplexity_score" ], 50 )
# 25th percentile
ds [ "train" ]. filter ( lambda x : x [ "perplexity_score" ] < p_25 , num_proc = 128 ). remove_columns ([ 'meta' , 'perplexity_score' , 'text_length' , 'url' , 'domain' , 'dup_ratio' , 'pairs' , 'repetitions' , 'included_in_dedup' , 'cluster' , 'id' ]). to_json ( "oscar_perplexity25.jsonl" , num_proc = 128 , force_ascii = False )
# 50th percentile
ds [ "train" ]. filter ( lambda x : x [ "perplexity_score" ] < p_50 , num_proc = 128 ). remove_columns ([ 'meta' , 'perplexity_score' , 'text_length' , 'url' , 'domain' , 'dup_ratio' , 'pairs' , 'repetitions' , 'included_in_dedup' , 'cluster' , 'id' ]). to_json ( "oscar_perplexity50.jsonl" , num_proc = 128 , force_ascii = False )その後、「繰り返し」セクションで説明されているように、Megatron でトレーニングするために結果の jsonl ファイルをトークン化できます。
C4: C4 の場合は、たとえば、 repetitionsフィールドが設定されているすべてのサンプルを削除する必要があります。
from datasets import load_dataset
import numpy as np
ds = load_dataset ( "datablations/c4-dedup" , use_auth_token = True , streaming = False , num_proc = 128 )
ds . filter ( lambda x : not ( x [ "repetitions" ]). to_json ( 'c4_dedup.jsonl' , num_proc = 128 , force_ascii = False ) OSCAR: OSCAR の場合、フィルタリング メタデータを含むデータセットを指定して重複排除されたデータセットを作成するスクリプトをfiltering/filter_oscar_jsonl.pyで提供します。
その後、「繰り返し」セクションで説明されているように、Megatron でトレーニングするために結果の jsonl ファイルをトークン化できます。
すべてのモデルは https://huggingface.co/datablations からダウンロードできます。
通常、モデルには次のような名前が付けられます: lm1-{parameters}-{tokens}-{unique_tokens}具体的には、フォルダー内の個々のモデルの名前は次のようになります: {parameters}{tokens}{unique_tokens}{optional specifier} 。たとえば、 1b12b8100m次のようになります。 11 億パラメータ、28 億トークン、1 億の一意のトークン。 xby ( 1b1 、 2b8など) 規則では、数値がパラメーターに属するかトークンに属するかが多少曖昧になりますが、いつでもそれぞれのフォルダーにある sbatch スクリプトをチェックして、正確なパラメーター、トークン、一意のトークンを確認できます。まだhuggingface/transformersに変換されていないモデルを変換したい場合は、トレーニングの手順に従ってください。
単一のモデルをダウンロードする最も簡単な方法は次のとおりです。
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/datablations/lm1-misc
cd lm1-misc ; git lfs pull --include 146m14b400m/global_step21553これに時間がかかりすぎる場合は、 wget使用してフォルダーから個々のファイルを直接ダウンロードすることもできます。例:
wget https://huggingface.co/datablations/lm1-misc/resolve/main/146m14b400m/global_step21553/bf16_zero_pp_rank_0_mp_rank_00_optim_states.pt論文内の実験に対応するモデルについては、次のリポジトリを参照してください。
lm1-misc/*dedup* (付録の 100M の一意のトークンでの重複排除の比較)論文で分析されていない他のモデル:
AMD GPU (ROCm 経由) で動作する Megatron-DeepSpeed のフォークを使用してモデルをトレーニングします: https://github.com/TurkuNLP/Megatron-DeepSpeed NVIDIA GPU (cuda 経由) を使用したい場合は、元のライブラリ: https://github.com/bigscience-workshop/Megatron-DeepSpeed
環境を作成するには、いずれかのリポジトリのセットアップ手順に従う必要があります (LUMI に固有のセットアップについては、 training/megdssetup.mdで詳しく説明されています)。
各モデル フォルダーには、モデルのトレーニングに使用された sbatch スクリプトが含まれています。これらを参照として使用して、必要な環境変数を適応させて独自のモデルをトレーニングできます。 sbatch スクリプトは、いくつかの追加ファイルを参照します。
*txtファイル。これらはutils/datapaths/*にありますが、データセットを指すようにパスを調整する必要がある場合があります。model_params.sh : utils/model_params.shにあり、アーキテクチャのプリセットが含まれています。launch.shはtraining/launch.shにあります。これには、セットアップに固有のコマンドが含まれているため、削除することもできます。トレーニング後、たとえばpython Megatron-DeepSpeed/tools/convert_checkpoint/deepspeed_to_transformers.py --input_folder global_step52452 --output_folder transformers --target_tp 1 --target_pp 1を使用してモデルをトランスフォーマーに変換できます。
繰り返しモデルの場合、トレーニング後にtensorboard dev upload --logdir tensorboard_8b7178b88boscar --name "tensorboard_8b7178b88boscar"使用してテンソルボードもアップロードします。これにより、論文での視覚化に簡単に使用できるようになります。
付録の muP アブレーションでは、 training_scripts/mup.pyにあるスクリプトを使用します。セットアップ手順が含まれています。
次のように、私たちの公式を使用して、パラメータ、データ、および一意のトークンを指定して予想される損失を計算できます。
import numpy as np
func = r"$L(N,D,R_N,R_D)=E + frac{A}{(U_N + U_N * R_N^* * (1 - e^{(-1*R_N/(R_N^*))}))^alpha} + frac{B}{(U_D + U_D * R_D^* * (1 - e^{(-1*R_D/(R_D^*))}))^beta}$"
a , b , e , alpha , beta , rd_star , rn_star = [ 6.255414 , 7.3049974 , 0.6254804 , 0.3526596 , 0.3526596 , 15.387756 , 5.309743 ]
A = np . exp ( a )
B = np . exp ( b )
E = np . exp ( e )
G = (( alpha * A ) / ( beta * B )) ** ( 1 / ( alpha + beta ))
def D_to_N ( D ):
return ( D * G ) ** ( beta / alpha ) * G
def scaling_law ( N , D , U ):
"""
N: number of parameters
D: number of total training tokens
U: number of unique training tokens
"""
assert U <= D , "Cannot have more unique tokens than total tokens"
RD = np . maximum (( D / U ) - 1 , 0 )
UN = np . minimum ( N , D_to_N ( U ))
RN = np . maximum (( N / UN ) - 1 , 0 )
L = E + A / ( UN + UN * rn_star * ( 1 - np . exp ( - 1 * RN / rn_star ))) ** alpha + B / ( U + U * rd_star * ( 1 - np . exp ( - 1 * RD / ( rd_star )))) ** beta
return L
# Models in Figure 1 (right):
print ( scaling_law ( 6.34e9 , 242e9 , 25e9 )) # 2.2256440889984477 # <- This one is better
print ( scaling_law ( 8.67e9 , 178e9 , 25e9 )) # 2.2269634075087867実際の損失値は役に立たない可能性が高く、むしろ、パラメータ数の増加や上記の例のように 2 つのモデルの比較など、損失の傾向が役立つことに注意してください。最適な割り当てを計算するには、単純なグリッド検索を使用できます。
def chinchilla_optimal_N ( C ):
a = ( beta ) / ( alpha + beta )
N_opt = G * ( C / 6 ) ** a
return N_opt
def chinchilla_optimal_D ( C ):
b = ( alpha ) / ( alpha + beta )
D_opt = ( 1 / G ) * ( C / 6 ) ** b
return D_opt
def optimal_allocation ( C , U_BASE ):
"""Compute optimal number of parameters and tokens to train for given a compute & unique data budget"""
N_BASE = chinchilla_optimal_N ( C )
D_BASE = chinchilla_optimal_D ( C )
min_l = float ( "inf" )
for i in np . linspace ( 1.0001 , 3 , 500 ):
D = D_BASE * i
U = min ( U_BASE , D )
N = N_BASE / i
new_l = scaling_law ( N , D , U )
if new_l < min_l :
min_l , min_t , min_s = new_l , D , N
D = D_BASE / i
U = min ( U_BASE , D )
N = N_BASE * i
new_l = scaling_law ( N , D , U )
if new_l < min_l :
min_l , min_t , min_s = new_l , D , N
return min_l , min_t , min_s
_ , min_t , min_s = optimal_allocation ( 10 ** 22 , 25e9 )
print ( f"Optimal configuration: { min_t } tokens, { min_t / 25e9 } epochs, { min_s } parameters" )
# -> 237336955477.55075 tokens, 9.49347821910203 epochs, 7022364735.879969 parameters
# We went more extreme in Figure 1 to really put our prediction of "many epochs, fewer params" to the test上記のグリッド検索の代わりに最適な割り当てのための閉形式を導出した場合は、お知らせください:) この colab と同等のutils/parametric_fit.ipynbにあるコードを使用して、データ制約のあるスケーリング則と C4 スケーリング係数を当てはめます。 。
Training > Regular modelsセクションの指示に従って、トレーニング環境をセットアップします。pip install git+https://github.com/EleutherAI/lm-evaluation-harness.git 。ここではバージョン 0.2.0 を使用しましたが、新しいバージョンでも同様に動作するはずです。sbatch utils/eval_rank.shを実行します。python Megatron-DeepSpeed/tasks/eval_harness/report-to-csv.py outfile.jsonを使用して各ファイルを CSV に変換します。addtasksブランチを複製します: git clone -b addtasks https://github.com/Muennighoff/lm-evaluation-harness.gitcd lm-evaluation-harness; pip install -e ".[dev]"; pip uninstall -y promptsource; pip install git+https://github.com/Muennighoff/promptsource.git@tr13つまり、正しいプロンプトを含むフォークからインストールされるプロンプトソースを除くすべての要件sbatch utils/eval_generative.shを実行します。python utils/merge_generative.py使用して生成ファイルをマージし、 python utils/csv_generative.py merged.jsonを使用して CSV に変換します。babiブランチのクローンを作成します: git clone -b babi https://github.com/Muennighoff/lm-evaluation-harness.git (このブランチは、生成タスクのaddtasksブランチと互換性がないことに注意してください。 EleutherAI/lm-evaluation-harness 、 addtasksはbigscience/lm-evaluation-harnessに基づいています)cd lm-evaluation-harness; pip install -e ".[dev]"sbatch utils/eval_babi.shを実行します。 plotstables/return_alloc.pdf 、 plotstables/return_alloc.ipynb 、colabplotstables/dataset_setup.pdf 、 plotstables/dataset_setup.ipynb 、colabplotstables/contours.pdf 、 plotstables/contours.ipynb 、colabplotstables/isoflops_training.pdf 、 plotstables/isoflops_training.ipynb 、colabplotstables/return.pdf 、 plotstables/return.ipynb 、colabplotstables/strategies.pdf 、 plotstables/strategies.drawioplotstables/beyond.pdf 、 plotstables/beyond.ipynb 、colabplotstables/cartoon.pdf 、 plotstables/cartoon.pptxplotstables/isoloss_400m1b5.pdf & 図 3 と同じ colabplotstables/mup.pdf 、 plotstables/dd.pdf 、 plotstables/dedup.pdf 、 plotstables/mup_dd_dd.ipynb 、colabplotstables/isoloss_alphabeta_100m.pdf & 図 3 と同じ colabplotstables/galactica.pdf 、 plotstables/galactica.ipynb 、colabtraining_c4.pdf 、 validation_c4oscar.pdf 、 training_oscar.pdf 、 validation_epochs_c4oscar.pdf & 図 4 と同じ colabplotstables/perplexity_histogram.pdf 、 plotstables/perplexity_histogram.ipynbplotstabls/validation_c4py.pdf 、 plotstables/training_validation_filter.pdf 、 plotstables/beyond_losses.ipynb 、colabutils/parametric_fit.ipynbにあります。plotstables/repetition.ipynbおよび colabplotstables/python.ipynbおよび colabplotstables/filtering.ipynbおよび colabすべてのモデルとコードは Apache 2.0 に基づいてライセンスされています。フィルタリングされたデータセットは、そのデータセットの元となるデータセットと同じライセンスでリリースされます。
@article { muennighoff2023scaling ,
title = { Scaling Data-Constrained Language Models } ,
author = { Muennighoff, Niklas and Rush, Alexander M and Barak, Boaz and Scao, Teven Le and Piktus, Aleksandra and Tazi, Nouamane and Pyysalo, Sampo and Wolf, Thomas and Raffel, Colin } ,
journal = { arXiv preprint arXiv:2305.16264 } ,
year = { 2023 }
}

