paperchat
1.0.0
arXivchat へようこそ!
arXivchat は、arXiv で出版された論文について会話形式で話すことができる LLM ベースのソフトウェアです。これは、cli ツール、API プロバイダー、および ChatGPT プラグインとして機能します。
フォワードオペレーターズ製。私たちは、LLM および ML 関連のプロジェクトで最も賢い人々と協力しています。
奮って投稿をお願いいたします。
arXiv プラグインをすばやくセットアップして実行するには、次の手順に従ってください。
Python 3.10 がまだインストールされていない場合は、インストールします。
リポジトリのクローンを作成します: git clone https://github.com/Forward-Operators/arxivchat.git
クローンされたリポジトリ ディレクトリに移動します: cd /path/to/arxivchat
詩をインストールする: pip install poetry
Python 3.10 で新しい仮想環境を作成する: poetry env use python3.10
仮想環境をアクティブ化する: poetry shell
アプリの依存関係をインストールします: poetry install
必要な環境変数を設定します。
export DATABASE= < your_datastore >
export OPENAI_API_KEY= < your_openai_api_key >
# Add the environment variables for your chosen vector DB.
# Pinecone
export PINECONE_API_KEY= < your_pinecone_api_key >
export PINECONE_ENVIRONMENT= < your_pinecone_environment >
export PINECONE_INDEX= < your_pinecone_index >
# Qdrant
export QDRANT_URL= < your_qdrant_url >
export QDRANT_PORT= < your_qdrant_port >
export QDRANT_GRPC_PORT= < your_qdrant_grpc_port >
export QDRANT_API_KEY= < your_qdrant_api_key >
export QDRANT_COLLECTION= < your_qdrant_collection >
# Chroma
export CHROMA_HOST= < your_chroma_host >
export CHROMA_PORT= < your_chroma_port >
export CHROMA_COLLECTION= < your_chroma_collection >
# Embeddings
export EMBEDDINGS= < openai or huggingface >
export CUDA_ENABLED= < True or False > - needed for huggingface
API をローカルで実行します: cd app/; gunicorn --worker-class uvicorn.workers.UvicornWorker --config ./gunicorn_conf.py main:app
http://0.0.0.0:8000/docs にある API ドキュメントにアクセスし、API エンドポイントをテストします。
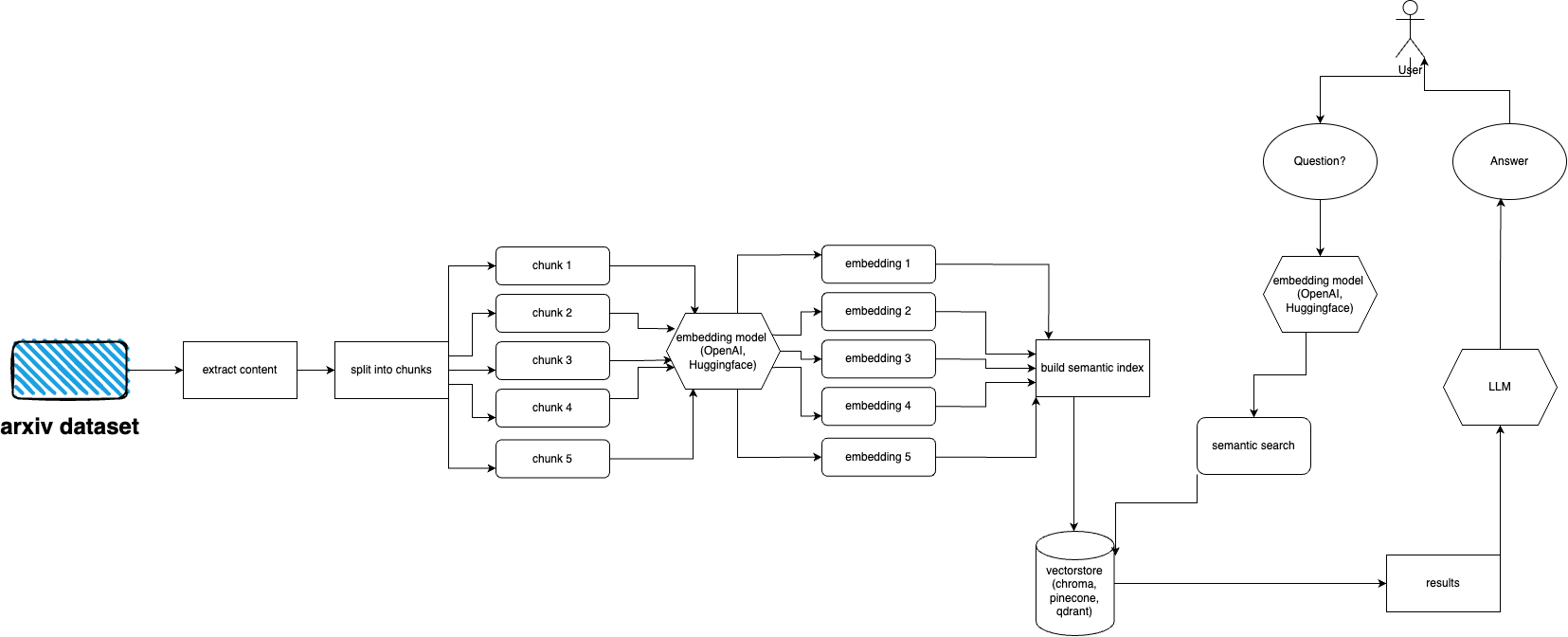
arXiv には、約 200 万件の出版物のデータセットがあります。 arXiv の Web サイトから大量のデータを取得することは (負荷がかかるため) arXiv の ToS に違反します。幸いなことに、kaggle の有能な人々がコーネル大学と協力して、一般に使用できるデータセットを作成しました。データセットは Google Cloud Storage バケット経由で無料で利用でき、毎週更新されます。
ここでの主な問題は、5 テラバイトを超える PDF ファイルを取り込みたくない場合に、データセット全体のサブセットのみを取得する方法です。データセットは月ごと、年ごとのディレクトリに分割されているため、2021 年 9 月のすべての出版物を取得したい場合は、次を実行するだけです: gsutil cp -r gs://arxiv-dataset/arxiv/pdf/2109/ ./local_directory
データセット全体を取得したい場合: gsutil cp -r gs://arxiv-dataset/arxiv/pdf/ ./a_local_directory/
ただし、(特定のカテゴリと日付の) サブセットのみを取得したい場合は、 download.pyファイルを調べてください。
デフォルトでは、インジェスターはこのファイルが/mnt/dataset/arxiv/pdfにあり、すべての PDF ファイルがそこにあることを想定しています。
python scripy.pyチェックアウトして実行し、データを取り込みます。何かが動作しない場合は、そこでデバッグを有効にすることもできます。
TODO: これをディレクトリローダーに変更するかもしれませんTODO: celery デプロイメントを実装し、取り込みにワーカーを使用します
python cli.py 
以前にデータベースに入力したトピックについて質問します。ソースに関する情報も返し、継続的に実行されます。別のオプションは、REST API を使用する ( appディレクトリからuvicorn main:app --reload --host 0.0.0.0 --port 8000実行する) か、ChatGPT プラグインとして使用する (デプロイ後) ことです。
deploymentディレクトリに terraform ファイルがあります。自分に合ったものを使用してください。それぞれに説明が記載された README ファイルがあります。 Docker イメージを構築して、必要な場所で実行することもできます。ただし、画像ファイルはかなり大きいです。
現時点では、docker イメージを使用して Cloud Run としてデプロイできるため、API のみのデプロイになります。データの取り込みは他のマシンで実行する必要があります(特に Hugging Face 埋め込みを使用したい場合、およびgcsfuse使用して Google ストレージからデータを直接マウントできるため、GPU 対応の Compute Engine をお勧めします) クラウドで GCS バケットを使用するための潜在的なソリューション走る
現時点では、コンテナ アプリとしてデプロイできます (API のみのデプロイ。取り込みには別のデプロイが必要です)。
AWS はまだサポートされていません。近日公開。
arxivchat はデフォルトで OpenAI にtext-embedding-ada-002使用します。これはapp/tools/factory.pyで変更できます。
今のところ、 sentence_transformersで動作する任意のモデルを使用できます。 app/tools/factory.pyでモデルを変更できます
問題がある場合は、GitHub の問題を使用して報告してください。
arXivchat をより良いものにするために、ぜひご協力をお願いいたします。貢献するには、次の手順に従ってください。
arXivchat は MIT ライセンスに基づいてリリースされています。


