distrifuser
v0.0.1beta0
[2024 年 7 月 29 日] ColossalAI で DistriFusion がサポートされました。
[2024 年 4 月 4 日] DistriFusion が CVPR 2024 のハイライトポスターに選ばれました!
[2024 年 2 月 29 日] DistriFusion が CVPR 2024 で承認されました。私たちのコードは公開されています。
 DistriFusion は、複数の GPU を利用して画質を犠牲にすることなく拡散モデル推論を高速化するトレーニング不要のアルゴリズムです。 Naïve Patch (概要 (b)) には、パッチの相互作用がないため、断片化の問題が発生します。提示された例は、解像度 1280 × 1920 で 50 ステップのオイラー サンプラーを使用して SDXL で生成され、レイテンシは A100 GPU で測定されています。
DistriFusion は、複数の GPU を利用して画質を犠牲にすることなく拡散モデル推論を高速化するトレーニング不要のアルゴリズムです。 Naïve Patch (概要 (b)) には、パッチの相互作用がないため、断片化の問題が発生します。提示された例は、解像度 1280 × 1920 で 50 ステップのオイラー サンプラーを使用して SDXL で生成され、レイテンシは A100 GPU で測定されています。
DistriFusion: 高解像度拡散モデルの分散並列推論
Muyang Li*、Tianle Cai*、Jiaxin Cao、Qinsheng Zhang、Han Cai、Junjie Bai、Yangqing Jia、Ming-Yu Liu、Kai Li、Song Han
MIT、プリンストン、Lepton AI、NVIDIA
CVPR 2024 では。
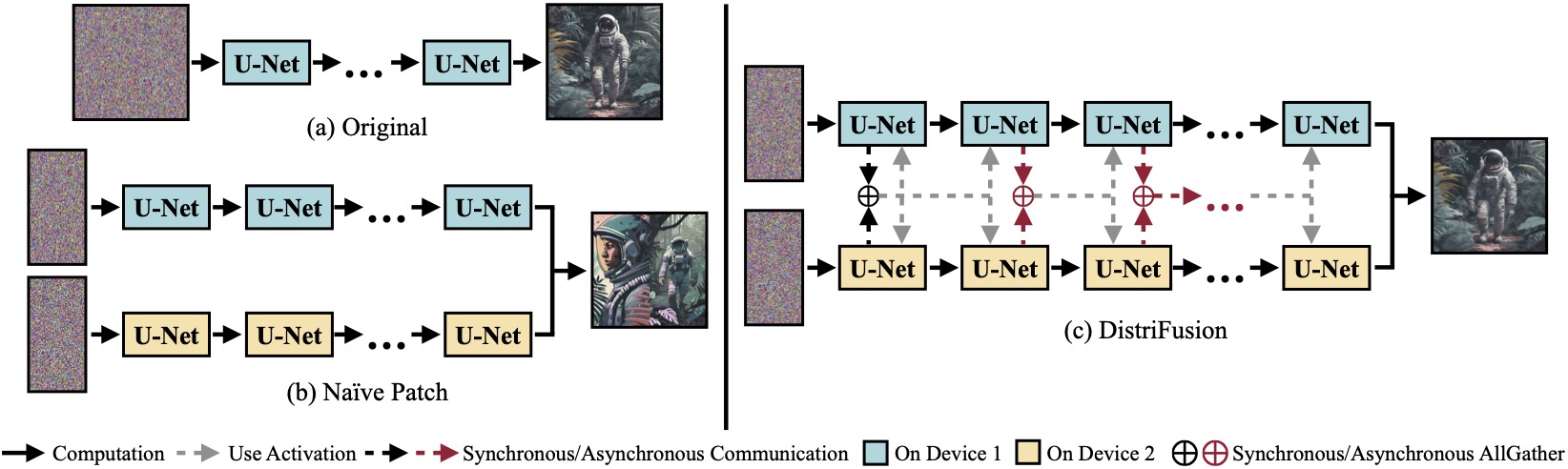 (a)単一デバイス上で実行されるオリジナルの拡散モデル。 (b)画像を 2 つの GPU にまたがる 2 つのパッチに単純に分割すると、パッチ間の相互作用が存在しないため、境界に明らかな継ぎ目が生じます。 (c)当社の DistriFusion では、最初のステップでパッチの対話に同期通信を採用しています。その後、非同期通信を介して前のステップのアクティベーションを再利用します。このようにして、通信オーバーヘッドを計算パイプラインに隠すことができます。
(a)単一デバイス上で実行されるオリジナルの拡散モデル。 (b)画像を 2 つの GPU にまたがる 2 つのパッチに単純に分割すると、パッチ間の相互作用が存在しないため、境界に明らかな継ぎ目が生じます。 (c)当社の DistriFusion では、最初のステップでパッチの対話に同期通信を採用しています。その後、非同期通信を介して前のステップのアクティベーションを再利用します。このようにして、通信オーバーヘッドを計算パイプラインに隠すことができます。
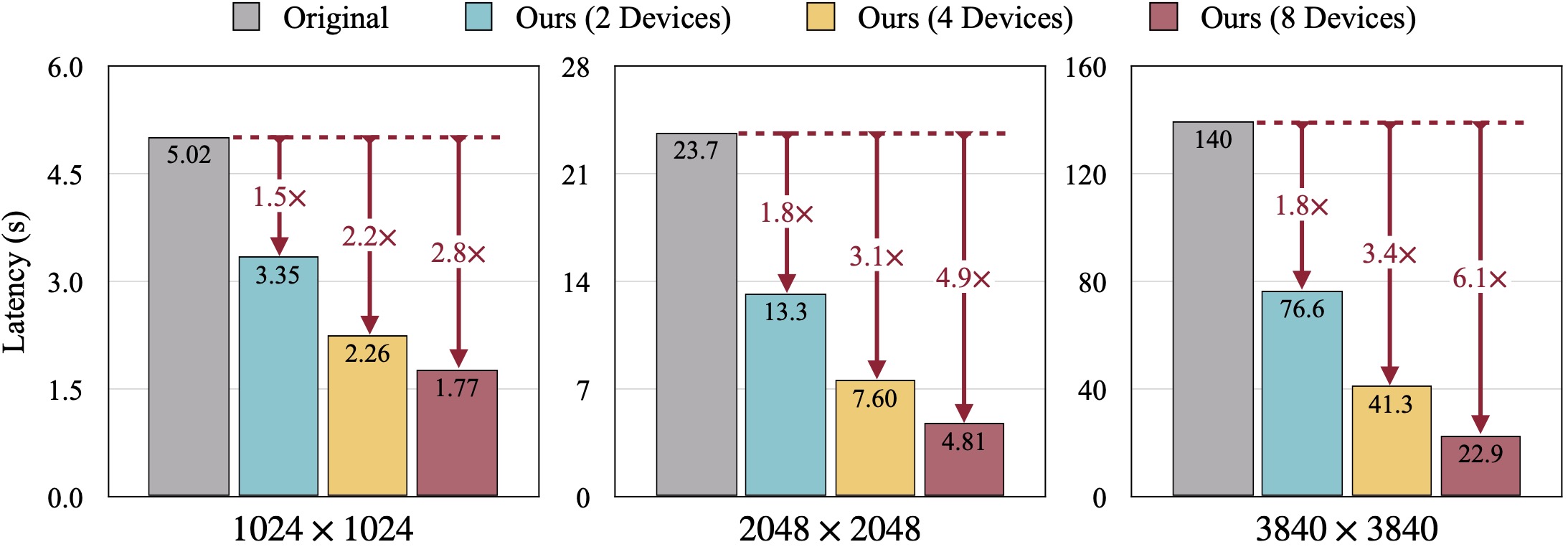
 SDXLの定性的結果。 FID はグラウンドトゥルース画像に対して計算されます。当社の DistriFusion は、視覚的な忠実性を維持しながら、使用するデバイスの数に応じて遅延を短縮できます。
SDXLの定性的結果。 FID はグラウンドトゥルース画像に対して計算されます。当社の DistriFusion は、視覚的な忠実性を維持しながら、使用するデバイスの数に応じて遅延を短縮できます。
参考文献:
PyTorch をインストールした後、PyPI を使用してdistrifuserインストールできるようになります。
pip install distrifuserまたは GitHub 経由:
pip install git+https://github.com/mit-han-lab/distrifuser.gitまたは開発のためにローカルで
git clone [email protected]:mit-han-lab/distrifuser.git
cd distrifuser
pip install -e .scripts/sdxl_example.pyには、DistriFusion で SDXL を実行するための最小限のスクリプトが提供されています。
import torch
from distrifuser . pipelines import DistriSDXLPipeline
from distrifuser . utils import DistriConfig
distri_config = DistriConfig ( height = 1024 , width = 1024 , warmup_steps = 4 )
pipeline = DistriSDXLPipeline . from_pretrained (
distri_config = distri_config ,
pretrained_model_name_or_path = "stabilityai/stable-diffusion-xl-base-1.0" ,
variant = "fp16" ,
use_safetensors = True ,
)
pipeline . set_progress_bar_config ( disable = distri_config . rank != 0 )
image = pipeline (
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k" ,
generator = torch . Generator ( device = "cuda" ). manual_seed ( 233 ),
). images [ 0 ]
if distri_config . rank == 0 :
image . save ( "astronaut.png" )具体的には、 distrifuserディフューザーと同じ API を共有しており、同様の方法で使用できます。 DistriConfig定義し、ラップされたDistriSDXLPipelineを使用して事前トレーニングされた SDXL モデルをロードするだけです。次に、ディフューザーでStableDiffusionXLPipelineのような画像を生成できます。実行コマンドは
torchrun --nproc_per_node= $N_GPUS scripts/sdxl_example.py $N_GPUSは、使用する GPU の数です。
また、DistriFusion で SD1.4/2 を実行するための最小限のスクリプトもscripts/sd_example.pyに提供されています。使い方は同じです。
ベンチマーク結果は、PyTorch 2.2 とディフューザー 0.24.0 を使用しています。まず、追加の依存関係をインストールする必要がある場合があります。
pip install git+https://github.com/zhijian-liu/torchprofile datasets torchmetrics dominate clean-fidscripts/generate_coco.py使用して、COCO キャプション付きの画像を生成できます。コマンドは
torchrun --nproc_per_node=$N_GPUS scripts/generate_coco.py --no_split_batch
$N_GPUSは、使用する GPU の数です。デフォルトでは、生成された結果はresults/cocoに保存されます。 --output_rootを使用してカスタマイズすることもできます。調整が必要な追加の引数は次のとおりです。
--num_inference_steps : 推論ステップの数。デフォルトでは 50 を使用します。--guidance_scale : 分類子を使用しないガイダンス スケール。デフォルトでは 5 を使用します。--scheduler : 拡散サンプラー。デフォルトでは DDIM サンプラーを使用します。オイラー サンプラーにはeuler 、DPM ソルバーにはdpm-solver使用することもできます。--warmup_steps : 追加のウォームアップ ステップの数 (デフォルトでは 4)。--sync_mode : 異なる GroupNorm 同期モード。デフォルトでは、修正された非同期 GroupNorm が使用されます。--parallelism : 使用する並列処理パラダイム。デフォルトでは、パッチ並列処理です。テンソル並列処理にはtensor 、ナイーブ パッチにはnaive_patch使用できます。すべてのイメージを生成したら、スクリプトscripts/compute_metrics.py使用して PSNR、LPIPS、および FID を計算できます。使い方は、
python scripts/compute_metrics.py --input_root0 $IMAGE_ROOT0 --input_root1 $IMAGE_ROOT1ここで、 $IMAGE_ROOT0と$IMAGE_ROOT1は、比較しようとしている画像フォルダーへのパスです。 IMAGE_ROOT0がグラウンド トゥルース フォルダーである場合は、サイズ変更用に--is_gtフラグを追加してください。また、グラウンドトゥルース画像をダンプするためのスクリプトscripts/dump_coco.pyも提供しています。
scripts/run_sdxl.py使用して、さまざまな方法のレイテンシをベンチマークできます。コマンドは
torchrun --nproc_per_node= $N_GPUS scripts/run_sdxl.py --mode benchmark --output_type latent $N_GPUSは、使用する GPU の数です。 scripts/generate_coco.pyと同様に、いくつかの引数を変更することもできます。
--num_inference_steps : 推論ステップの数。デフォルトでは 50 を使用します。--image_size : 生成される画像のサイズ。デフォルトでは 1024×1024 です。--no_split_batch : 分類子を使用しないガイダンスのためのバッチ分割を無効にします。--warmup_steps : 追加のウォームアップ ステップの数 (デフォルトでは 4)。--sync_mode : 異なる GroupNorm 同期モード。デフォルトでは、修正された非同期 GroupNorm が使用されます。--parallelism : 使用する並列処理パラダイム。デフォルトでは、パッチ並列処理です。テンソル並列処理にはtensor 、ナイーブ パッチにはnaive_patch使用できます。--warmup_times / --test_times : ウォームアップ/テストの実行数。デフォルトでは、それぞれ 5 と 20 です。 このコードを研究に使用する場合は、論文を引用してください。
@inproceedings { li2023distrifusion ,
title = { DistriFusion: Distributed Parallel Inference for High-Resolution Diffusion Models } ,
author = { Li, Muyang and Cai, Tianle and Cao, Jiaxin and Zhang, Qinsheng and Cai, Han and Bai, Junjie and Jia, Yangqing and Liu, Ming-Yu and Li, Kai and Han, Song } ,
booktitle = { Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) } ,
year = { 2024 }
}私たちのコードは、huggingface/diffusers と lmxyy/sige に基づいて開発されています。 MAC 測定については torchprofile、FID 計算については clean-fid、PSNR と LPIPS については Lightning-AI/torchmetrics に感謝します。
Jun-Yan Zhu 氏と Ligeng Zhu 氏の有益な議論と貴重なフィードバックに感謝します。このプロジェクトは、MIT-IBM Watson AI Lab、Amazon、MIT Science Hub、および National Science Foundation によって支援されています。


