VideoX
1.0.0
これは私たちのビデオ理解作品のコレクションです
SeqTrack (
@CVPR'23): SeqTrack: 視覚オブジェクト追跡のためのシーケンスツーシーケンス学習
X-CLIP (
@ECCV'22 Oral):一般的なビデオ認識のための言語と画像の事前学習済みモデルの拡張
MS-2D-TAN (
@TPAMI'21):自然言語によるモーメントローカリゼーションのためのマルチスケール 2D 時間的隣接ネットワーク
2D-TAN (
@AAAI'20):自然言語によるモーメント位置特定のための 2D 時間的隣接ネットワークの学習
強力なコーディング スキルを持つ研究インターンの採用: [email protected] | [email protected]
2023 年 4 月: SeqTrackのコードがリリースされました。
2023 年 2 月: SeqTrackが CVPR'23 に承認されました
2022 年 9 月: X-CLIPが統合されました。
2022 年 8 月: X-CLIPのコードがリリースされました。
2022 年 7 月: X-CLIPが ECCV'22 に Oral として採択されました
2021 年 10 月: MS-2D-TANのコードがリリースされました。
2021年9月: MS-2D-TANがTPAMI'21に採択されました
2019 年 12 月: コード for 2D-TANがリリースされました。
2019年11月: 2D-TANがAAAI'20に採択されました
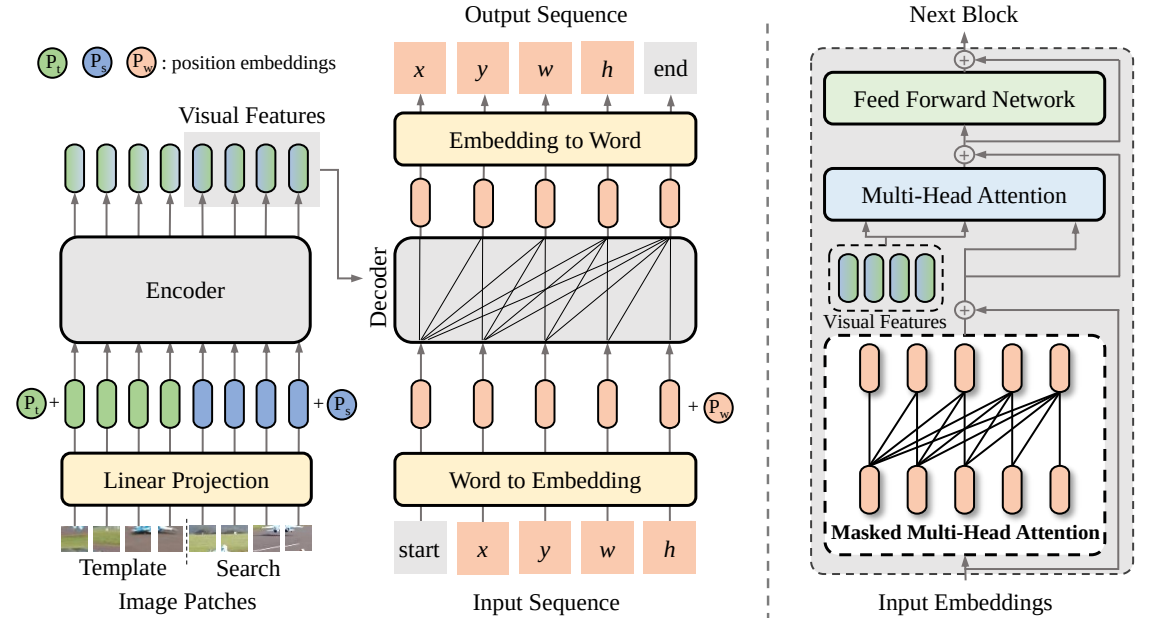
この論文では、SeqTrack と呼ばれる、視覚追跡のための新しいシーケンス間学習フレームワークを提案します。視覚的な追跡をシーケンス生成問題として投影し、自己回帰方式でオブジェクトの境界ボックスを予測します。 SeqTrack は、単純なエンコーダー/デコーダー トランスフォーマー アーキテクチャのみを採用しています。エンコーダーは双方向トランスフォーマーを使用して視覚的特徴を抽出し、デコーダーは因果デコーダーを使用して自己回帰的に一連の境界ボックス値を生成します。損失関数は単純なクロスエントロピーです。このようなシーケンス学習パラダイムは、追跡フレームワークを簡素化するだけでなく、多くのベンチマークで競争力のあるパフォーマンスを実現します。
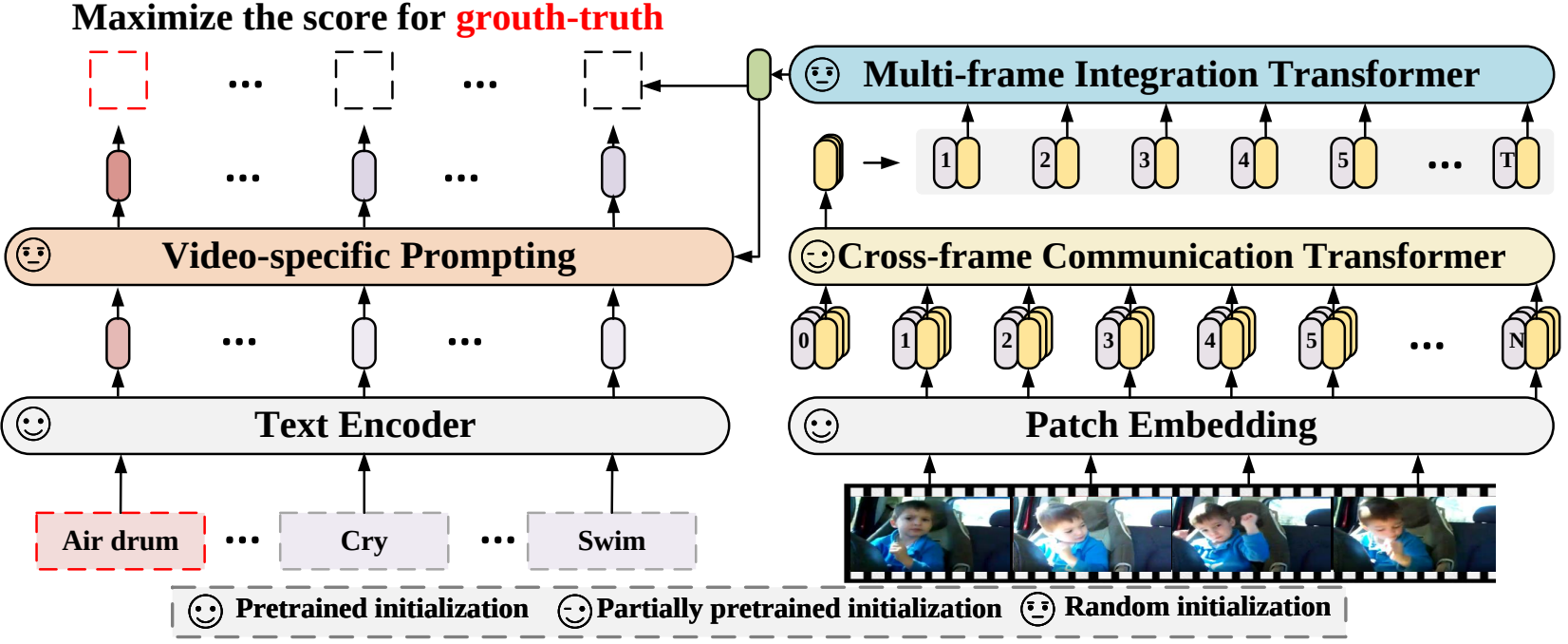
この論文では、事前訓練された言語画像モデルをビデオ認識に適応させる新しいビデオ認識フレームワークを提案します。具体的には、時間情報を取得するために、フレーム間で明示的に情報を交換するクロスフレーム アテンション メカニズムを提案します。ビデオ カテゴリのテキスト情報を利用するために、インスタンス レベルで識別可能なテキスト表現を生成できるビデオ固有のプロンプト手法を設計します。広範な実験により、私たちのアプローチが効果的であり、完全教師あり、少数ショット、ゼロショットなどのさまざまなビデオ認識シナリオに一般化できることが実証されています。
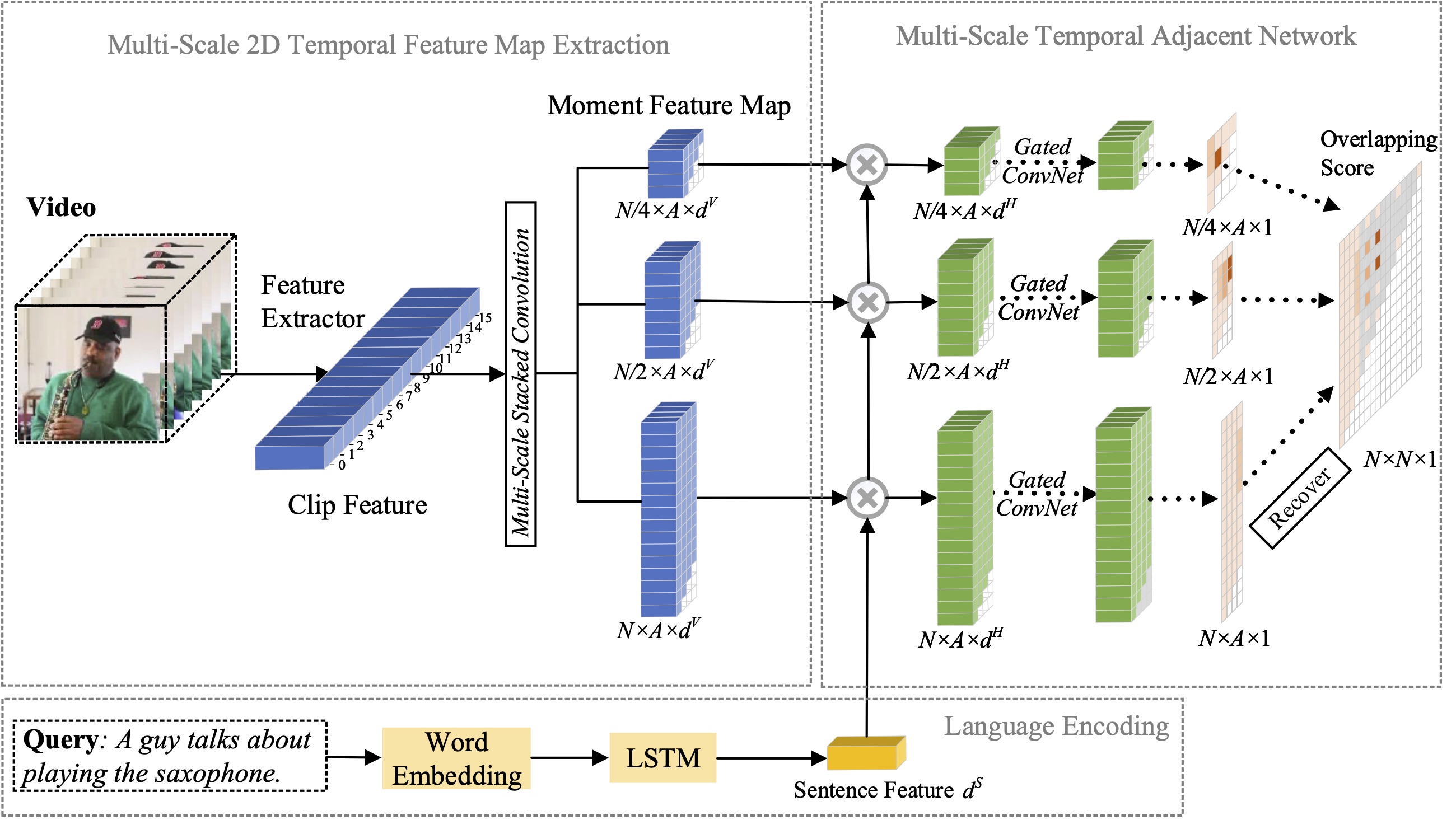
この論文では、自然言語によるモーメント位置特定の問題を研究し、以前に提案した 2D-TAN 手法をマルチスケール バージョンに拡張することを提案します。中心となるアイデアは、異なる時間スケールで 2 次元時間マップからモーメントを取得することであり、隣接するモーメント候補を時間コンテキストとして考慮します。拡張バージョンでは、ビデオの瞬間を参照表現と照合するための識別特徴を学習しながら、異なるスケールで隣接する時間的関係をエンコードできます。私たちのモデルは設計がシンプルで、3 つのベンチマーク データセットで最先端の手法と比較して競争力のあるパフォーマンスを実現します。
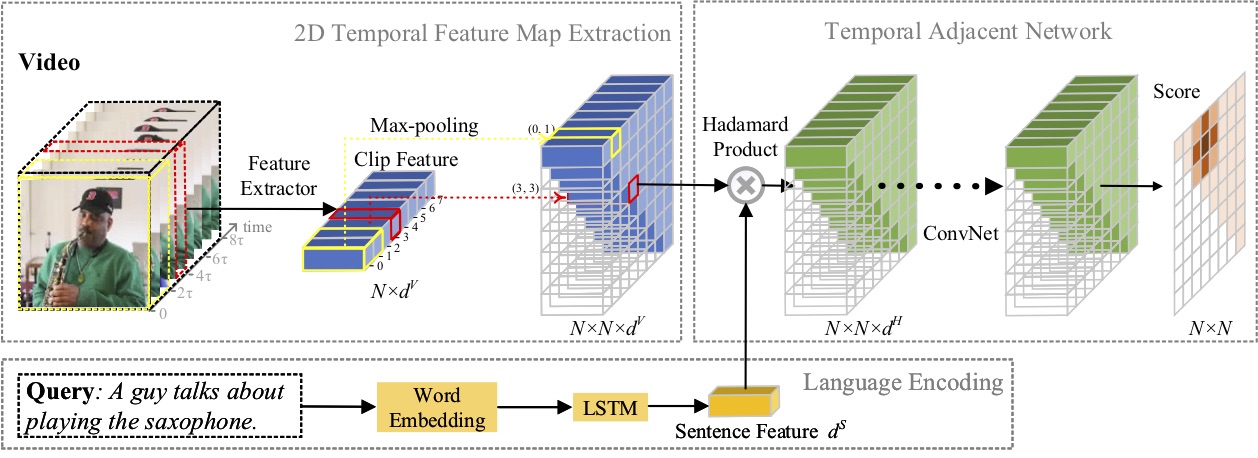
本論文では,自然言語によるモーメント位置特定の問題を研究し,新しい2D時間隣接ネットワーク(2D-TAN)法を提案した。中心的なアイデアは、隣接するモーメント候補を時間的コンテキストとして考慮する、2 次元時間マップ上のモーメントを取得することです。 2D-TAN は、ビデオの瞬間を参照表現と照合するための識別特徴を学習しながら、隣接する時間的関係をエンコードできます。私たちのモデルは設計がシンプルで、3 つのベンチマーク データセットで最先端の手法と比較して競争力のあるパフォーマンスを実現します。
@InProceedings{SeqTrack, title={SeqTrack: 視覚オブジェクト追跡のためのシーケンスからシーケンスへの学習}、著者={Chen、Xin と Peng、Houwen と Wang、Dong と Lu、Huchuan と Hu、Han}、booktitle={CVPR}, year={2023}}@InProceedings{XCLIP, title={一般ビデオ向けの言語と画像の事前トレーニング済みモデルの拡張Recognition}、著者 = {Ni、Bolin と Peng、Houwen と Chen、Minghao と Zhang、Songyang と Meng、Gaofeng と Fu、Jianlong と Xiang、Shiming と Ling、Haibin}、booktitle={欧州コンピュータ ビジョン会議 (ECCV) }、年={2022}}@InProceedings{Zhang2021MS2DTAN、
著者 = {Zhang、Songyang と Peng、Houwen と Fu、Jianlong と Lu、Yijuan と Luo、Jiebo}、
title = {自然言語によるモーメント位置特定のためのマルチスケール 2D 時間的隣接ネットワーク},
書籍のタイトル = {TPAMI}、
年 = {2021}}@InProceedings{2DTAN_2020_AAAI、
著者 = {Zhang、Songyang と Peng、Houwen と Fu、Jianlong と Luo、Jiebo}、
title = {自然言語によるモーメントローカリゼーションのための 2D 時間的隣接ネットワークの学習},
本のタイトル = {AAAI}、
年 = {2020}}MIT ライセンスに基づくライセンス。


