ffhq dataset
1.0.0

Flickr-Faces-HQ (FFHQ) は人間の顔の高品質画像データセットで、もともと敵対的生成ネットワーク (GAN) のベンチマークとして作成されました。
敵対的生成ネットワークのためのスタイルベースのジェネレーター アーキテクチャ
Tero Karras (NVIDIA)、Samuli Laine (NVIDIA)、Timo Aila (NVIDIA)
https://arxiv.org/abs/1812.04948
このデータセットは、解像度 1024×1024 の 70,000 枚の高品質 PNG 画像で構成されており、年齢、民族、画像の背景に関してかなりのバリエーションが含まれています。眼鏡、サングラス、帽子などのアクセサリーも十分にカバーしています。画像は Flickr からクロールされ、その Web サイトのすべてのバイアスを継承し、dlib を使用して自動的に配置およびトリミングされます。許可されたライセンスに基づく画像のみが収集されました。セットを整理するためにさまざまな自動フィルターが使用され、最終的には Amazon Mechanical Turk を使用して、時折登場する彫像、絵画、または写真が削除されました。
このデータセットは、顔認識技術の開発または改善を目的としたものではなく、そのために使用すべきではないことに注意してください。ビジネスに関するお問い合わせについては、弊社 Web サイトにアクセスし、次のフォームを送信してください: NVIDIA Research Licensing
個々の画像は、Creative Commons BY 2.0、Creative Commons BY-NC 2.0、Public Domain Mark 1.0、Public Domain CC0 1.0、または US Government Works ライセンスに基づいて、それぞれの作成者によって Flickr で公開されました。これらのライセンスはすべて、非営利目的での自由な使用、再配布、翻案を許可します。ただし、それらの中には、元の作成者に適切なクレジットを与えること、および画像に加えられた変更を示すことを必要とするものもあります。各画像のライセンスとオリジナルの作者はメタデータに示されています。
データセット自体 (JSON メタデータ、ダウンロード スクリプト、ドキュメントを含む) は、NVIDIA Corporation のクリエイティブ コモンズ BY-NC-SA 4.0 ライセンスに基づいて利用可能です。 (a)論文を引用することで適切なクレジットを示し、(b) 行った変更を示し、(c) 派生作品を配布する限り、非営利目的で使用、再配布、改変することができます。同じライセンスの下で。
すべてのデータは Google ドライブでホストされます。
| パス | サイズ | ファイル | 形式 | 説明 |
|---|---|---|---|---|
| ffhq-データセット | 2.56TB | 210,014 | メインフォルダー | |
| § ffhq-dataset-v2.json | 255MB | 1 | JSON | 著作権情報、URL などのメタデータ |
| § 画像1024x1024 | 89.1GB | 70,000 | PNG | 1024×1024 で位置合わせおよびトリミングされた画像 |
| § サムネイル128x128 | 1.95GB | 70,000 | PNG | サムネイルは128×128 |
| § 野生の画像 | 955GB | 70,000 | PNG | Flickr からの元の画像 |
| § tfrecords | 273GB | 9 | tfrecords | StyleGAN および StyleGAN2 のマルチ解像度データ |
| ━ ジッパー | 1.28TB | 4 | ジップ | 各フォルダーの内容を ZIP アーカイブとして保存します。 |
高レベルの統計:
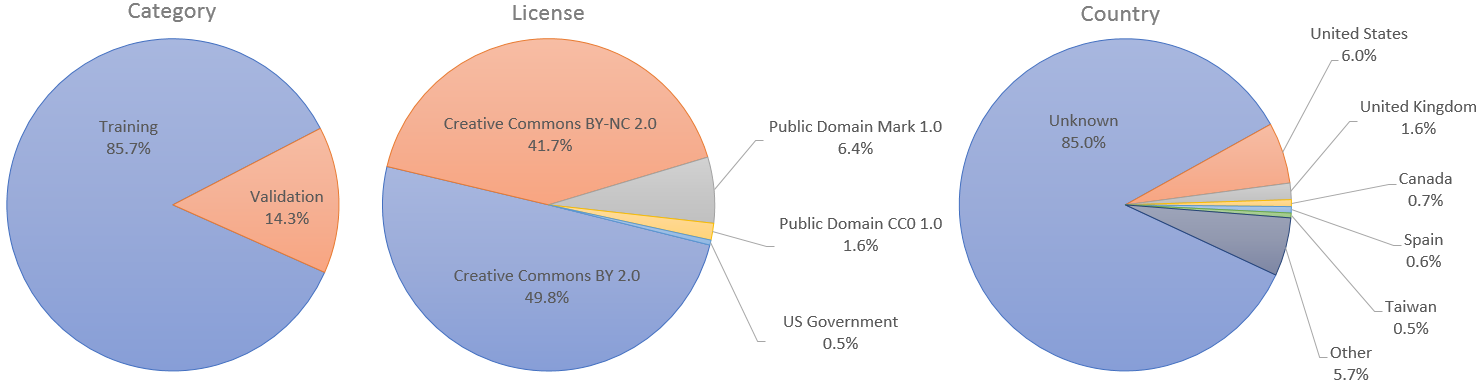
個別のトレーニング セットと検証セットを必要とするユースケースの場合、最初の 60,000 枚の画像をトレーニングに使用し、残りの 10,000 枚を検証に使用するように指定しました。ただし、StyleGAN の論文では、70,000 枚の画像すべてをトレーニングに使用しました。
データセット自体に重複した画像がないことを明示的に確認しました。ただし、同じ画像から複数の異なる顔を抽出した場合、 in-the-wildフォルダーには同じ画像の複数のコピーが含まれる可能性があることに注意してください。
Google ドライブから直接データを取得することも、提供されているダウンロード スクリプトを使用することもできます。このスクリプトは、要求されたすべてのファイルを自動的にダウンロードし、チェックサムを確認し、エラーが発生した場合は各ファイルを数回再試行し、帯域幅を最大化するために複数の同時接続を採用することにより、作業を大幅に簡素化します。
> python download_ffhq.py -h
usage: download_ffhq.py [-h] [-j] [-s] [-i] [-t] [-w] [-r] [-a]
[--num_threads NUM] [--status_delay SEC]
[--timing_window LEN] [--chunk_size KB]
[--num_attempts NUM]
Download Flickr-Face-HQ (FFHQ) dataset to current working directory.
optional arguments:
-h, --help show this help message and exit
-j, --json download metadata as JSON (254 MB)
-s, --stats print statistics about the dataset
-i, --images download 1024x1024 images as PNG (89.1 GB)
-t, --thumbs download 128x128 thumbnails as PNG (1.95 GB)
-w, --wilds download in-the-wild images as PNG (955 GB)
-r, --tfrecords download multi-resolution TFRecords (273 GB)
-a, --align recreate 1024x1024 images from in-the-wild images
--num_threads NUM number of concurrent download threads (default: 32)
--status_delay SEC time between download status prints (default: 0.2)
--timing_window LEN samples for estimating download eta (default: 50)
--chunk_size KB chunk size for each download thread (default: 128)
--num_attempts NUM number of download attempts per file (default: 10)
--random-shift SHIFT standard deviation of random crop rectangle jitter
--retry-crops retry random shift if crop rectangle falls outside image (up to 1000
times)
--no-rotation keep the original orientation of images
--no-padding do not apply blur-padding outside and near the image borders
--source-dir DIR where to find already downloaded FFHQ source data
> python ..download_ffhq.py --json --images
Downloading JSON metadata...
100.00% done 2/2 files 0.25/0.25 GB 43.21 MB/s ETA: done
Parsing JSON metadata...
Downloading 70000 files...
| 100.00% done 70001/70001 files 89.19 GB/89.19 GB 59.87 MB/s ETA: done
このスクリプトは、画像の位置合わせとトリミングに使用した自動化スキームのリファレンス実装としても機能します。 python download_ffhq.py --wildsを使用して野生の画像をダウンロードしたら、 python download_ffhq.py --alignを実行して、メタデータに含まれる顔のランドマークの位置を使用して、位置合わせされた 1024×1024 画像の正確なレプリカを再現できます。 。
Alias-Free Generative Adversarial Networks の論文で使用されている「非整列 FFHQ」データセットを再現するには、次のオプションを使用します。
python download_ffhq.py
--source-dir <path/to/downloaded/ffhq>
--align --no-rotation --random-shift 0.2 --no-padding --retry-crops
ffhq-dataset-v2.jsonファイルには、各イメージに関する次の情報が機械可読形式で含まれています。
{
"0": { # Image index
"category": "training", # Training or validation
"metadata": { # Info about the original Flickr photo:
"photo_url": "https://www.flickr.com/photos/...", # - Flickr URL
"photo_title": "DSCF0899.JPG", # - File name
"author": "Jeremy Frumkin", # - Author
"country": "", # - Country where the photo was taken
"license": "Attribution-NonCommercial License", # - License name
"license_url": "https://creativecommons.org/...", # - License detail URL
"date_uploaded": "2007-08-16", # - Date when the photo was uploaded to Flickr
"date_crawled": "2018-10-10" # - Date when the photo was crawled from Flickr
},
"image": { # Info about the aligned 1024x1024 image:
"file_url": "https://drive.google.com/...", # - Google Drive URL
"file_path": "images1024x1024/00000/00000.png", # - Google Drive path
"file_size": 1488194, # - Size of the PNG file in bytes
"file_md5": "ddeaeea6ce59569643715759d537fd1b", # - MD5 checksum of the PNG file
"pixel_size": [1024, 1024], # - Image dimensions
"pixel_md5": "47238b44dfb87644460cbdcc4607e289", # - MD5 checksum of the raw pixel data
"face_landmarks": [...] # - 68 face landmarks reported by dlib
},
"thumbnail": { # Info about the 128x128 thumbnail:
"file_url": "https://drive.google.com/...", # - Google Drive URL
"file_path": "thumbnails128x128/00000/00000.png", # - Google Drive path
"file_size": 29050, # - Size of the PNG file in bytes
"file_md5": "bd3e40b2ba20f76b55dc282907b89cd1", # - MD5 checksum of the PNG file
"pixel_size": [128, 128], # - Image dimensions
"pixel_md5": "38d7e93eb9a796d0e65f8c64de8ba161" # - MD5 checksum of the raw pixel data
},
"in_the_wild": { # Info about the in-the-wild image:
"file_url": "https://drive.google.com/...", # - Google Drive URL
"file_path": "in-the-wild-images/00000/00000.png", # - Google Drive path
"file_size": 3991569, # - Size of the PNG file in bytes
"file_md5": "1dc0287e73e485efb0516a80ce9d42b4", # - MD5 checksum of the PNG file
"pixel_size": [2016, 1512], # - Image dimensions
"pixel_md5": "86b3470c42e33235d76b979161fb2327", # - MD5 checksum of the raw pixel data
"face_rect": [667, 410, 1438, 1181], # - Axis-aligned rectangle of the face region
"face_landmarks": [...], # - 68 face landmarks reported by dlib
"face_quad": [...] # - Aligned quad of the face region
}
},
...
}
詳細な議論と有益なコメントを提供してくれた Jaakko Lehtinen、David Luebke、Tuomas Kynkäänniemi に感謝します。 Janne Hellsten、Tero Kuosmanen、Pekka Jänis がコンピューティング インフラストラクチャを担当し、コード リリースを支援しました。
また、最初にデータを収集できるようにしてくれた自動顔検出と位置合わせの取り組みについて、Vahid Kazemi 氏と Josephine Sullivan 氏にも感謝します。
回帰ツリーのアンサンブルを使用した 1 ミリ秒の顔の位置合わせ
ヴァヒド・カゼミ、ジョセフィン・サリバン
手順CVPR 2014
https://www.cv-foundation.org/openaccess/content_cvpr_2014/papers/Kazemi_One_Millisecond_Face_2014_CVPR_paper.pdf
データを収集する際、私たちが知る限り、それぞれの作者による自由な使用と再配布を目的とした写真のみを含めるように注意しました。とはいえ、私たちは写真の掲載を希望しない個人のプライバシーを保護することに全力で取り組んでいます。
あなたの写真が Flickr-Faces-HQ データセットに含まれているかどうかを確認するには、このリンクをクリックして、Flickr ユーザー名でデータセットを検索してください。
Flickr-Faces-HQ データセットから写真を削除するには:
no_cvのタグを付けて、コンピューター ビジョンの研究に使用したくないことを示します。None (無断転載禁止)、またはNoDerivsを含むクリエイティブ コモンズ ライセンスに変更して、再配布したくないことを示します。

