StableDiffusionEndToEndGuide
1.0.0
私は SD を使用して軍事用途向けの画像を生成することに興味を持ちました。アノンは SD を使用してエロアニメを作成するため、リソースのほとんどは 4chan の NSFW ボードから取得されています。興味深いことに、正規の SD WebUI にはアニメ/エロアニメ画像ボードの機能が組み込まれています...DALL-E 直後の SD の最初の使用例の 1 つはアニメの女の子を生成することであったため、エロアニメへのジャンプは驚くべきことではありません。
とにかく、これらの変人たちのテクニックはさまざまなアプリケーション、特にモデルの微調整機能のような LoRA に適用できます。このアイデアは、特定の LoRA (軍用車両、航空機、武器など) と連携して、視覚モデルをトレーニングするための合成画像データを生成することです。新しい有用な LoRA のトレーニングも興味深いものです。後の作業には、摂動の修復が含まれる可能性があります。
Every link here may contain NSFW content, as most of the cutting-edge work on SD and LoRAs is with porn or hentai. So, please be wary when you are working with these resources. ALSO, Rentry.org pages are the main resources linked to in this guide. If any of the rentry pages do not work, change the .org to .co and the link should work. Otherwise, use the Wayback machine.
-TP
SDでは実際に何ができるのでしょうか? Huggingface やその他の企業では、ブラウザー内にいくつかのアプリを用意しています。遊んでみてその威力を見てみましょう!このガイドで行うことは、必要なことを何でもできるようにする完全な拡張可能な WebUI を入手することです。
これに入るのは少し気が遠くなります...しかし、4channer はこれを親しみやすくするために良い仕事をしました。以下は、私が行った手順を最も簡単な言葉で示したものです。あなたの目的は、Stable Diffusion WebUI (Gradio で構築) をローカルで実行して、プロンプトの表示とイメージの作成を開始できるようにすることです。
後で Google Colab Pro のセットアップを行うので、どこでも好きなデバイスで SD を実行できます。まずは、PC で WebUI をセットアップしましょう。 16 GB RAM、2 GB VRAM を備えた GPU、Windows 7 以降、および 20 GB 以上のディスク容量が必要です。
127.0.0.1:7860 )(このコマンドにより CLI が閉じられる可能性があるため、Ctrl + C は使用しないでください)。stable-diffusion-webuioutputstxt2img-images<date>に自動的に保存されます。git pullを入力するだけです。 
Windows を使用している場合は、これを完全に無視してください。少し複雑ですが、Linux でも実行することができました。私はこのガイドに従って作業を開始しましたが、かなり貧弱に書かれているため、Linux で実行するために私が行った手順を以下に示します。私は Ubuntu 20 ディストリビューションである Linux Mint 20 を使用していました。
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.gitstable-diffusion-webui/models/Stable-diffusionに置きます。sudo apt install python3 python3-pip python3-virtualenv wget git wget https://repo.anaconda.com/miniconda/Minconda3-latest-Linux-x86_64.sh
chmod +x Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh
conda create --name sdwebui python=3.10.6conda activate sdwebui./webui.shと入力します。 sudo apt update
sudo apt purge *nvidia*
sudo add-apt-repository ppa:graphics-drivers/ppaと入力します。sudo apt-get updateで更新するsudo apt-get install nvidia-driver-530を使用してターミナルにインストールします。nvidia-smiを入力します。成功した場合は、表を出力する必要があります。そうでない場合は、「GPU に接続できませんでした。最新のドライバーがインストールされていることを確認してください」のようなメッセージが表示されます。 sudo apt update
sudo apt install apt-transport-https ca-certificates gnupg
sudo apt install nvidia-cuda-toolkit
nvcc-version
python3 -c 'import venv'
python3 -m venv venv/
次に、 /stable-diffusion-webuiフォルダーに移動して、以下を実行します。
rm -rf venv/
python3 -m venv venv/
その後はうまくいきました。
プロンプト内の単語の順序には影響があり、前の単語が優先されます。優れたプロンプトの一般的な構造は次のとおりです。
<general positives> <descriptors of subject> <descriptors of background> <post-processing, camera, etc.>
また、別の優れたガイドでは、プロンプトは次の構造に従う必要があると述べています。
<subject> <medium> <style> <artist> <website> <resolution> <additional details> <color> <lighting>
プロンプト エンジニアリング txt2img モデルに関する独創的な論文はここにあります。 LLM プロンプトに関する決定的なリソースはこちらです。
何を要求しても、プロセスを複製できるように、ある種の構造に従うようにしてください。必要なプロンプト構文要素は次のとおりです。
1girl standing on grass in front of castle AND castle in background デフォルトのモデルは非常にきちんとしていますが、歴史上よくあることですが、ほとんどのことは性欲によって引き起こされます。 NovelAI (NAI) はアニメに特化した SD コンテンツ生成サービスであり、その主要モデルが漏洩されました。あなたが見るアニメの男性と女性の SD 生成画像 (NSFW かどうかに関係なく) のほとんどは、この流出したモデルから来ています。
いずれにせよ、これは人々を生成するのに非常に優れており、アニメ画像でトレーニングされているため、マージしてプレイするモデルや LoRA のほとんどはこれと互換性があります。また、人間は、プロの目的で使用したい LoRA を正確に微調整するための非常に優れた開始ユースケースを提供します。多くのトラブルシューティングを行うことになりますが、世に出ているガイドのほとんどは女性の画像に関するものです。後で、モデルに真のリアリズムをもたらす変数自動エンコーダー (VAE) について説明します。
stable-diffusion-webuimodelsStable-diffusionに取得し、そこでモデルを選択したら、CLI が VAE 重みをロードするまで数分待つ必要があります。低ランク適応 (LoRA) により、特定のモデルを微調整できます。 LoRA の詳細については、こちらをご覧ください。 WebUI では、ケーキの上に飾るように LoRA をモデルに追加できます。新しい LoRA のトレーニングも非常に簡単です。他にも「先祖代々の」微調整手段 (テキスト反転やハイパーネットワークなど) はありますが、LoRA は最先端のものです。
ガイド全体を通してタンク LoRA を使用します。これはアニメ スタイルの画像を目的としているため、あまり優れた LoRA ではないことに注意してください。しかし、遊ぶには問題ありません。
stable-diffusion-webuiextensionssd-webui-additional-networksmodelsloraに配置します。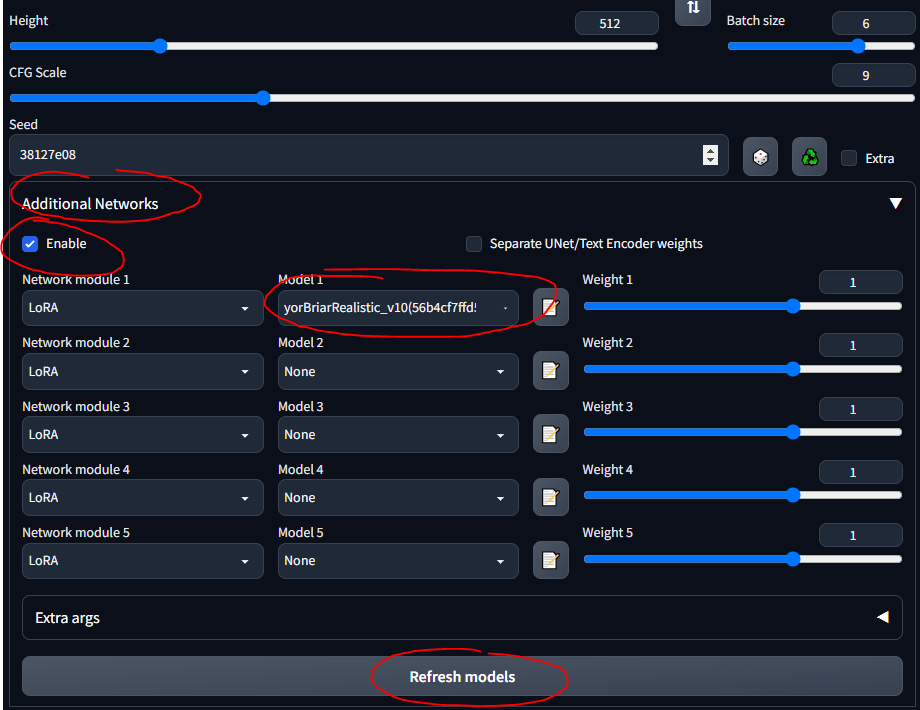
前のセクションに基づいて構築します...モデルが異なれば、トレーニング データとトレーニング キーワードも異なります...そのため、一部のモデルで booru タグを使用すると、あまりうまく機能しません。以下は私が遊んだモデルの一部とその「説明書」です。
SDG モデル マザーロードは、ほとんどのモデルを取得するために使用されます。ここでは、簡単な参照のために手順を要約しています。ほとんどのモデルは文字通りのポルノ用ですが、私はリアルなものに焦点を当てました。リンクをクリックすると、プロンプトの例、画像、およびそれぞれの使用に関する詳細な注意事項が表示されます。
他のすべてを取得するために CivitAI が使用されました。アカウントを作成する必要があります。そうしないと、武器や軍事装備を含む NSFW 関連のコンテンツを見ることができなくなります。 CivitAI では、一部のモデル (チェックポイント) に VAE が含まれています。これが記載されている場合は、それもダウンロードしてモデルの横に置きます。
可変オートエンコーダーにより、画像の見栄えが良くなり、鮮明になり、白飛びが少なくなります。手や顔を固定するものもあります。しかし、それは主に彩度とシェーディングの問題です。こことここ (NSFW) で説明されています。 NovelAI / Anything VAE がよく使われます。これは基本的に、LoRA と同様に、モデルへのアドオンです。
VAE リストで VAE を検索します。
stable-diffusion-webuimodelsVAEに配置してください。ここでは、このガイドの時系列の流れとは必ずしも一致しない、途中で学んだ一般的な注意事項と役に立つことをいくつか紹介します。
学習する良い方法は、CivitAI、AIbooru、または他の SD サイト (4chan、Reddit など) でクールな画像を参照し、気に入った画像を開いて、生成パラメータを WebUI にコピーすることです。完全な開示: ここで説明するように、イメージを正確に再作成することが常に可能であるとは限りません。しかし、通常はかなり近づくことができます。実際に遊んでみるには、モデルがよりクリエイティブになるように CFG を低くします。バッチを試し、コンピュータから離れてロットに戻って選択します。
WebUI ワークフローの一般的なプロセスは次のとおりです。
find/pick models/LoRAs -> txt2img (repeat, change params, etc.) -> img2img -> inpainting -> extra ->
画像を貼り付けたり、最初から作成したりせずに、プロンプトに戻りたい場合があります。プロンプトを保存して、WebUI で再利用できます。
このセクションは、多かれ少なかれ、このガイドの情報のダイジェストです。
すでに存在する SD で生成されたイメージから作業する場合。誰かがあなたに送ってくれたか、自分が作ったものを再作成したいかもしれません。
stable-diffusion-webuioutputstxt2img-images<date>に保存されます。一部のサイト (4chan など) では、画像がアップロードされると PNG メタデータが削除されるため、完全な画像への URL を探すか、CivitAI や AIbooru などの SD メタデータを保持するサイトを使用することに注意してください。
時々いくつかのエラーが発生します。主にメモリ不足 (VRAM) エラーが発生し、一部のパラメータの値を下げることで修正されました。時にはリストアの顔や採用者もいます。設定を修正するとこの問題が発生する可能性があります。ファイルstable-diffusion-webuiwebui-user.batのset COMMANDLINE_ARGS=行に、一般的なエラーを修正するいくつかのフラグを置くことができます。
--disable-nan-checkを追加します--no-halfを追加してください--medvramを追加します。ポテト コンピュータの場合は、 --lowvram追加します。よくある問題の 1 つは、Python のバージョンまたは Torch のバージョンが間違っていることに起因します。 「Torch をインストールできません」または「Torch が GPU を見つけられません」などのエラーが発生します。最も簡単な修正は次のとおりです。
PythonフォルダーとPython/Scriptsフォルダーの両方) に追加してください。stable-diffusion-webuiフォルダー内のvenvフォルダーを削除します。stable-diffusion-webuiwebui-user.batを実行し、venv を適切に再構築します。すべてのコマンドライン引数はここにあります。
一部の拡張機能を使用すると、WebUI をより使いやすくできます。 Github リンクを取得し、[拡張機能] タブに移動し、URL からインストールします。オプションで、[拡張機能] タブで [利用可能] をクリックし、[ロード元] をクリックすると、拡張機能をローカルで参照できます。これは、拡張機能の Github Wiki を反映しています。
これで、いくつかのモデル、LoRA、プロンプトができました。何が最も効果的かをテストするにはどうすればよいでしょうか? [追加ネットワーク] ペインの下に、[スクリプト] ドロップダウンがあります。ここで、X/Y/Z プロットをクリックします。 X タイプで、チェックポイント名を選択します。 X 値で、右側のボタンをクリックしてすべてのモデルを貼り付けます。 Y タイプでは、VAE、あるいはシード、または CFG スケールを試してください。どの属性を選択しても、グラフにしたい値を貼り付け (または入力) します。たとえば、5 つのモデルと 5 つの VAE がある場合、25 個の画像のグリッドを作成し、各モデルが各 VAE でどのように出力するかを比較します。これは非常に多用途であり、何を使用するかを決定するのに役立ちます。 X 軸または Y 軸が VAE のモデルである場合、すべての組み合わせに対してモデルまたは VAE の重みをロードする必要があるため、時間がかかる可能性があることに注意してください。
SD 比較に関する非常に優れたリソースは、ここ (NSFW) にあります。フォローすべきリンクがたくさんあります。さまざまなモデル、VAE、LoRA、パラメータ値などが画像生成にどのように影響するかを理解し始めることができます。
ここからテスト プロンプトを採用し、タンク LoRA を使用してこの X/Y グリッドを作成しました。さまざまなモデルとサンプラーがどのように相互に連携するかを確認できます。このテストから、次のことが評価できます。

これらの戦車画像のそれぞれに使用される正確なパラメーター (モデルやサンプラーは含まれません) を以下に示します (こちらもここから引用)。
このセクションでは、WebUI の txt2image タブでモデル、LoRA、VAE、プロンプト、パラメータ、スクリプト、および拡張機能の使用に慣れてきたら、実行できるより高度な操作について説明します。
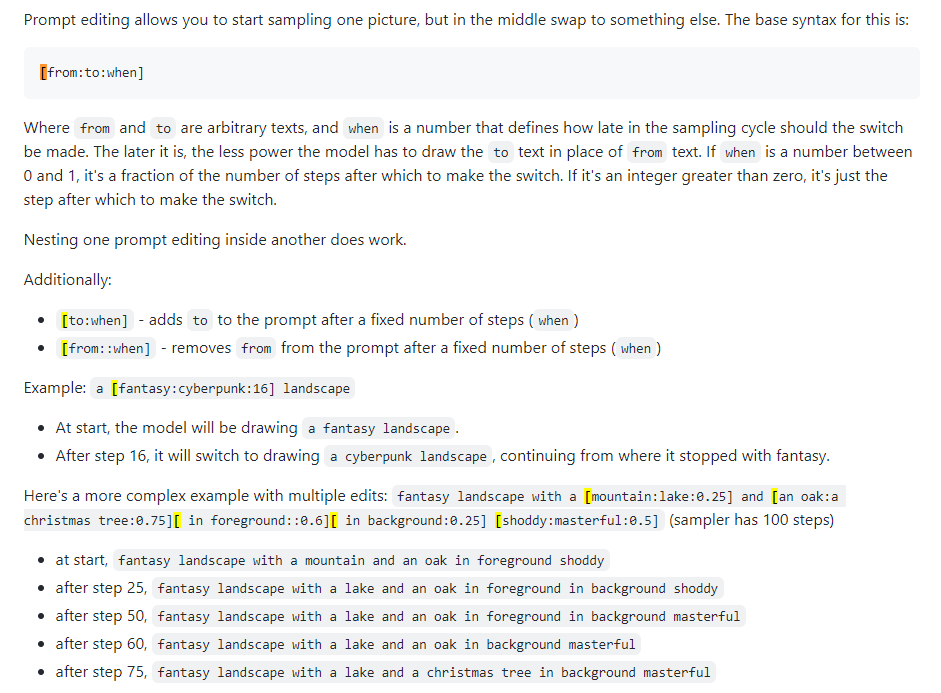
プロンプトブレンディングとも呼ばれます。プロンプト編集を使用すると、指定したステップでモデルのプロンプトを変更できます。下の画像は 4chan の投稿から取ったもので、このテクニックについて説明しています。たとえば、このガイドで説明されているように、プロンプト編集を使用して面をブレンドできます。
Xformers、またはクロスアテンション層。 Nvidia GPU でのイメージ生成 (秒/反復、または s/it で測定) を高速化する方法は、VRAM の使用量を減らしますが、非決定性を引き起こします。強力な GPU を使用している場合にのみ、これを考慮してください。現実的にはQuadroが必要です。
実際にはあまり使用されず、ややこしいタブです。 Huggingface Image to Image SD Playground のように、スケッチから画像を生成するために使用できます。このタブには修復というサブタブがあります。これは次のセクションの主題であり、WebUI の非常に重要な機能です。このセクションを使用して、既に作成した画像 ( stable-diffusion-webuioutputsimg2img-imagesへの出力) に基づいて変更された画像を生成することができますが、私にとってその機能にはむらがあります... 非常に大量のメモリを使用するようです。かろうじて機能させることができます。以下の次のセクションに進んでください。
これは、コンテンツ作成者または画像の摂動に興味のある人にとって力がある場所です。出力はstable-diffusion-webuioutputsimg2img-imagesにあります。
アウトペイントはかなり複雑なセマンティック プロセスです。アウトペイントを使用すると、画像を取得して何度でも拡大することができ、基本的に画像の境界線を拡大することができます。ここではそのプロセスについて説明します。画像を一度に拡大できるのは 64 ピクセルだけです。これには 2 つの UI ツールがあります (私が見つけたものは):
この WebUI タブはアップスケーリング専用です。本当に気に入った画像が見つかった場合は、ワークフローの最後にここで画像をアップスケールできます。アップスケールされたイメージはstable-diffusion-webuioutputsextras-imagesに保存されます。 txt2img タブでの生成中に、より強力なアップスケーラーによるアップスケーリングに関連するメモリの問題の一部 (例: 4x+ のもの) は、新しいイメージを生成せず、静的なイメージのみをアップスケーリングするため、ここでは発生しません。
ControlNet の機能を理解する最良の方法は、「ステロイドを使った修復」と言うのと同じです。入力イメージ (SD 生成かどうかに関係なく) を与えると、全体を変更できます。 ControlNet ではポーズも可能です。人物の基準ポーズを指定し、典型的なプロンプトに応じて対応する画像を生成できます。 ControlNet を理解するための良いスタートはここからです。
stable-diffusion-webuiextensionssd-webui-controlnetmodelsに配置します。

これはすべて良いことですが、プロのユースケースでは、より優れたモデルや LoRA が必要になる場合があります。 SD コンテンツのほとんどは文字通り女性やポルノを生成することを目的としているため、特定のモデルや LoRA をトレーニングする必要がある場合があります。
DreamBooth のセクションを参照してください。
TODO
WebUI のチェックポイント結合タブを使用すると、鍋で 2 つのソースを混ぜるなど、2 つのモデルを組み合わせることができます。出力は、両方を組み合わせた新しいソースになります。
TODO
LoRA のトレーニングは必ずしも難しいわけではなく、十分なデータを収集するだけの問題です。
リグから離れて作業する必要がある場合、これは重要なステップです。 Google Colab Pro は月額 10 ドルで、89 GB の RAM と優れた GPU へのアクセスを提供するため、技術的には携帯電話からプロンプトを実行し、それを Timbuktu のサーバー上で動作させることができます。多少の追加料金を気にしない場合は、Google Colab Pro+ が月額 50 ドルでさらにお得です。
gdrive/MyDrive/sd/stable-diffusion-webui 。このベース フォルダーから、ローカルで行っていたのと同じフォルダー構造を使用できます。 WebUIGoogle Colab は常に無料で永久に使用できますが、少し遅くなる場合があります。月額 10 ドルで Colab Pro にアップグレードすると、さらに強力になります。しかし、本当に楽しいのは月額 50 ドルの Colab Pro+ です。 Pro+ では、タブを閉じた後でも 24 時間コードを実行できます。
TODOランタイム -> ルーンタイム タイプのノートブック設定をプレミアム GPU クラスと高 RAM に設定すると、Pro サブスクリプションを中断する奇妙なエラーが発生します。それは、xFormers が CUDA サポートを使用して構築されていないためです。これは、代わりに TPU を使用するか、xFormer を無効にすることで解決できる可能性がありますが、現時点では忍耐力がありません。 Colab の問題を試してください。
MJはアーティストにとって本当に良い存在だ。 WebUI の SD ほど拡張性や強力さはまったくありません (NSFW は不可能) が、かなり素晴らしいものを生成できます。 MJ Discord (サイトでサインアップ) で数回のプロンプトを表示するまでは無料で使用できます。または、月額 8 ドルを支払うベーシック プランを使用することもでき、その後は自分のプライベート サーバーで使用できます。すべての Discord コマンドはこことここにあります。 MJ のプロンプト構造は次のとおりです。
/imagine <optional image prompt> <prompt> --parameters
これらは MJ V4 用であり、MJ 5 でもほとんど同じです。ここではすべてのモデルについて説明します。
TODO
Dreamstudio(Dreamboothではない)は、安定性AI会社のフラッグシッププラットフォームです。彼らのサイトはプラットフォームであるDreambooth Studioで、そこから画像を生成できます。オープン機能の観点から、ミディジョニーとWebUIの間にあるようなものです。 Dreambooth Studioは、invoke.aiプラットフォームの上に構築されているようです。これは、WebUIのように地元でインストールして実行できます。
TODO
安定したHordeは、すべての人に安定した拡散を自由にするためのコミュニティの努力です。基本的には、トレントやビットコインハッシュのように機能します。そこでは、誰もがGPUパワーの一部を寄付してSDコンテンツを生成します。 Hordeアプリにアクセスできます。
TODO
DreamBooth(Dreamstudioではない)は、Googleが安定した拡散モデルの微調整技術の実装でした。要するに、それを使用して、独自の写真でモデルをトレーニングできます。ここまたはここから直接使用できます。モデルをダウンロードしてWebUIをクリックするよりも複雑です。実際に新しいモデルのトレーニングとシリアル化に取り組んでいるからです。いくつかのビデオはそれを行う方法を要約します:
そしていくつかの良いガイド:
DreamboothのGoogleコラブ:
EveryDreamと呼ばれるモデルトレーナーもあります。 DreamboothとEverydreamの完全な比較は、ここにあります。
TODO
2023年3月の時点で、ビデオを生成するために安定した拡散を使用することが可能です。現在(2023年4月)、ビデオはフレームごとに類似の画像から生成され、ビデオに一種の「フリップブック」の外観を与えるため、機能はかなり単純です。使用できるWebUIには2つの主要な拡張機能があります。
あまり知らないが、調べる必要があるもの
何度も良い結果を得るために従うことができるプロセスがあります...これは時間の経過とともに洗練されます。
chatgpt統合?
上塗り
Dall-E 2
deforum https://deforum.github.io/


