EasyInstruct
1.0.0

大規模な言語モデル向けの使いやすい命令処理フレームワーク。
プロジェクト、論文、デモ、概要、インストール、クイックスタート、使用方法、ドキュメント、ビデオ、引用、貢献者
このリポジトリは KnowLM のサブプロジェクトです。
EasyInstruct は、研究実験で GPT-4、LLaMA、ChatGLM などの大規模言語モデル (LLM) 用の使いやすい命令処理フレームワークとして提案されている Python パッケージです。 EasyInstruct は、命令の生成、選択、プロンプトをモジュール化し、それらの組み合わせと相互作用も考慮します。
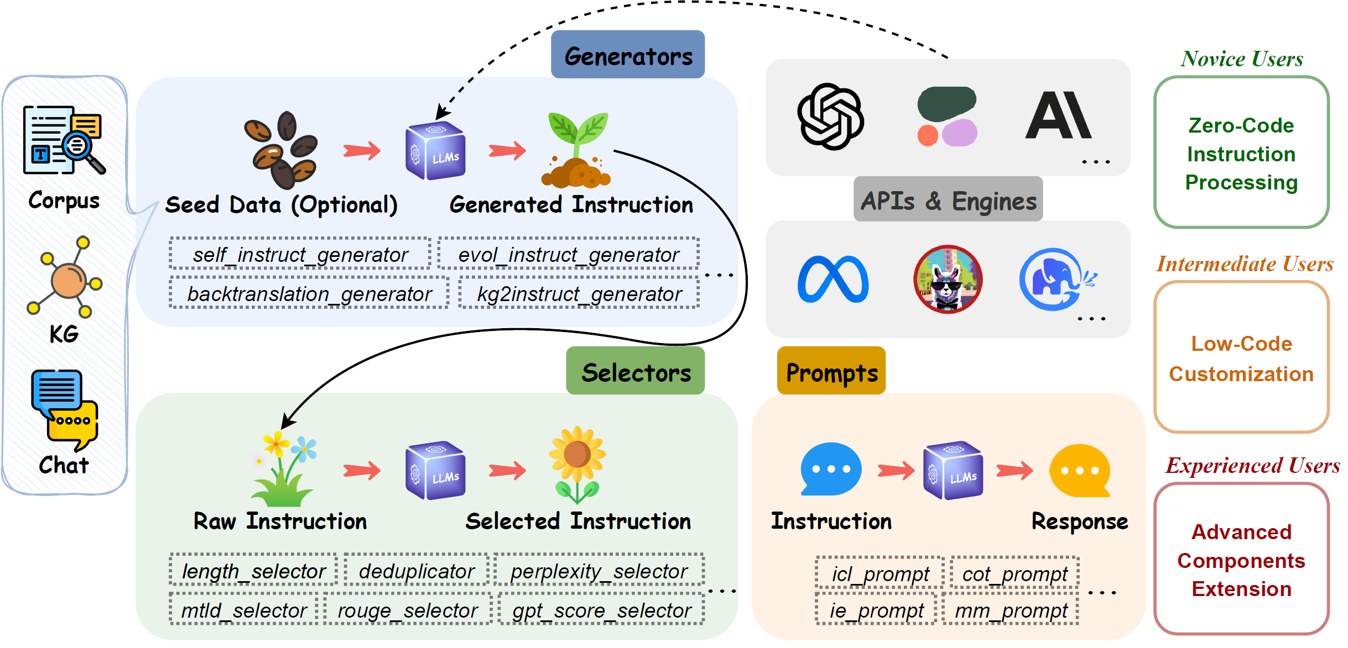
現在サポートされている命令生成手法は次のとおりです。
| メソッド | 説明 |
|---|---|
| 自己指導 | 人間が注釈を付けたシード タスク プールからデモンストレーションとしていくつかの命令をランダムにサンプリングし、LLM にさらに多くの命令と対応する入出力ペアを生成するよう促す方法。 |
| Evol-Instruct | LLM に特定のプロンプトを表示することで、初期の命令セットをより複雑な命令に段階的にアップグレードする方法。 |
| 逆翻訳 | コーパスの文書の一部によって正しく応答されるであろう命令を予測することによって、トレーニング インスタンスに続く命令を作成する方法。 |
| KG2指導 | コーパスの文書の一部によって正しく応答されるであろう命令を予測することによって、トレーニング インスタンスに続く命令を作成する方法。 |
現在サポートされている命令選択メトリックは次のとおりです。
| メトリクス | 表記 | 説明 |
|---|---|---|
| 長さ | 命令と応答の各ペアの制限された長さ。 | |
| 困惑 | 累乗された応答の平均負の対数尤度。 | |
| MTLD | テキストの語彙多様性の尺度。TTR スコアの最小しきい値を維持する、テキスト内の連続する単語の平均長。 | |
| ルージュ | 要旨評価のための想起指向のアンダースタディ。文間の類似性を評価するために使用される一連の指標。 | |
| GPTスコア | ChatGPT によって提供される、出力が AI アシスタントがユーザーの指示にどのように応答するかを示す良い例であるかどうかのスコア。 | |
| CIRS | 抽象構文ツリーを使用して構造的および論理的属性をエンコードし、コードと推論能力の間の相関関係を測定するスコア。 |
現在利用可能な API サービス プロバイダーとそれに対応する LLM 製品:
| モデル | 説明 | デフォルトのバージョン |
|---|---|---|
| OpenAI | ||
| GPT-3.5 | GPT-3 を改良し、自然言語やコードを理解し、生成できるモデルのセット。 | gpt-3.5-turbo |
| GPT-4 | GPT-3.5 を改良し、自然言語やコードを理解し、生成できるモデルのセット。 | gpt-4 |
| 人間的 | ||
| クロード | 有益で誠実で無害な AI システムのトレーニングに関する Anthropic の研究に基づいた次世代の AI アシスタント。 | claude-2.0 |
| クロード・インスタント | クロードよりも軽く、安価で、はるかに速いオプションです。 | claude-instant-1.2 |
| コヒア | ||
| 指示 | Cohereの主力テキスト生成モデルは、ユーザーのコマンドに従い、実際のビジネス・アプリケーションで即座に役立つようにトレーニングされています。 | command |
| コマンドライト | Command モデルの軽量バージョン。高速ですが、生成されるテキストの品質は低くなる可能性があります。 | command-light |
git リポジトリ ブランチからのインストール:
pip install git+https://github.com/zjunlp/EasyInstruct@main
ローカル開発用のインストール:
git clone https://github.com/zjunlp/EasyInstruct
cd EasyInstruct
pip install -e .
PyPI を使用したインストール (最新バージョンではありません):
pip install easyinstruct -i https://pypi.org/simple
ユーザーが EasyInstruct をすぐに使い始めるための 2 つの方法を提供します。特定のニーズに基づいて、シェル スクリプトまたは Gradio アプリを使用できます。
ユーザーは、YAML スタイルのファイルで EasyInstruct のパラメータを簡単に設定することも、提供される設定ファイルのデフォルト パラメータをすぐに使用することもできます。以下は、Self-Instruct の構成ファイルの例です。
generator :
SelfInstructGenerator :
target_dir : data/generations/
data_format : alpaca
seed_tasks_path : data/seed_tasks.jsonl
generated_instructions_path : generated_instructions.jsonl
generated_instances_path : generated_instances.jsonl
num_instructions_to_generate : 100
engine : gpt-3.5-turbo
num_prompt_instructions : 8その他の設定ファイルの例は configs にあります。
ユーザーはまず構成ファイルを指定し、独自の OpenAI API キーを指定する必要があります。次に、次のシェル スクリプトを実行して、命令の生成または選択プロセスを開始します。
config_file= " "
openai_api_key= " "
python demo/run.py
--config $config_file
--openai_api_key $openai_api_key ユーザーが EasyInstruct をすぐに使い始めることができるように、Gradio アプリを提供しています。次のコマンドを実行して、ポート8080 (使用可能な場合) でローカルに Gradio アプリを起動できます。
python demo/app.pyまた、HuggingFace Spaces で実行中の gradio アプリもホストしています。ここで試してみることができます。
詳細については、ドキュメントを参照してください。
Generatorsモジュールは、命令データ生成のプロセスを合理化し、シード データに基づいて命令データを生成できるようにします。特定のニーズに基づいて、適切なジェネレーターを選択できます。
BaseGenerator、すべてのジェネレーターの基本クラスです。
この基本クラスを簡単に継承して、独自のジェネレーター クラスをカスタマイズすることもできます。
__init__をオーバーライドしてメソッドgenerateだけです。
SelfInstructGenerator、Self-Instruct の命令生成メソッドのクラスです。詳細については、「Self-Instruct: 言語モデルと自己生成命令の調整」を参照してください。
例
from easyinstruct import SelfInstructGenerator
from easyinstruct . utils . api import set_openai_key
# Step1: Set your own API-KEY
set_openai_key ( "YOUR-KEY" )
# Step2: Declare a generator class
generator = SelfInstructGenerator ( num_instructions_to_generate = 10 )
# Step3: Generate self-instruct data
generator . generate ()
BacktranslationGenerator、命令逆変換の命令生成メソッドのクラスです。詳細については、「命令逆変換による自己調整」を参照してください。
from easyinstruct import BacktranslationGenerator
from easyinstruct . utils . api import set_openai_key
# Step1: Set your own API-KEY
set_openai_key ( "YOUR-KEY" )
# Step2: Declare a generator class
generator = BacktranslationGenerator ( num_instructions_to_generate = 10 )
# Step3: Generate backtranslation data
generator . generate ()
EvolInstructGenerator、EvolInstructの命令生成メソッドのクラスです。詳細については、「WizardLM: 大規模言語モデルが複雑な命令に従うことができるようにする」を参照してください。
from easyinstruct import EvolInstructGenerator
from easyinstruct . utils . api import set_openai_key
# Step1: Set your own API-KEY
set_openai_key ( "YOUR-KEY" )
# Step2: Declare a generator class
generator = EvolInstructGenerator ( num_instructions_to_generate = 10 )
# Step3: Generate evolution data
generator . generate ()
KG2InstructGenerator、KG2Instructの命令生成メソッドのクラスです。詳細については、「InstructIE: 中国語の命令ベースの情報抽出データセット」を参照してください。
Selectorsモジュールは命令選択プロセスを標準化し、生の未処理の命令データから高品質の命令データセットを抽出できるようにします。生データは、公開されている命令データセットから取得することも、フレームワーク自体によって生成することもできます。特定のニーズに基づいて適切なセレクターを選択できます。
BaseSelectorすべてのセレクターの基本クラスです。
この基本クラスを簡単に継承して、独自のセレクター クラスをカスタマイズすることもできます。
__init__メソッドと__process__メソッドをオーバーライドするだけです。
Deduplicatorは、トレーニング前の安定性と LLM のパフォーマンスの両方に悪影響を及ぼす可能性がある重複した命令サンプルを排除するためのクラスです。Deduplicator使用すると、ストレージ領域の効率的な使用と最適化も可能になります。
LengthSelectorは、命令の長さに基づいて命令サンプルを選択するためのクラスです。命令が長すぎたり短すぎたりすると、データの品質に影響が出る可能性があり、命令のチューニングには役に立ちません。
RougeSelectorは、テキストの自動生成の品質を評価するためによく使用される ROUGE メトリックに基づいて命令サンプルを選択するためのクラスです。
GPTScoreSelectorは、ChatGPT によって提供される、出力が AI アシスタントがユーザーの指示にどのように応答するかを示す良い例であるかどうかを反映する GPT スコアに基づいて指示サンプルを選択するためのクラスです。
PPLSelectorは、応答の累乗平均負対数尤度であるパープレキシティに基づいて命令サンプルを選択するためのクラスです。
MTLDSelector、MTLD (Measure of Textual Lexical Diversity の略) に基づいて命令サンプルを選択するためのクラスです。
CodeSelector、コードと推論能力の間の相関関係を測定するために、構造的属性と論理的属性を組み合わせた Complexity-Impacted Reasoning Score (CIRS) に基づいてコード命令サンプルを選択するためのクラスです。 「思考プログラムが推論に役立つのはどのような場合ですか?」を参照してください。詳細については。
from easyinstruct import CodeSelector
# Step1: Specify your source file of code instructions
src_file = "data/code_example.json"
# Step2: Declare a code selecter class
selector = CodeSelector (
source_file_path = src_file ,
target_dir = "data/selections/" ,
manually_partion_data = True ,
min_boundary = 0.125 ,
max_boundary = 0.5 ,
automatically_partion_data = True ,
k_means_cluster_number = 2 ,
)
# Step3: Process the code instructions
selector . process ()
MultiSelectorは、特定のニーズに基づいて複数の適切なセレクターを組み合わせるためのクラスです。
Promptsモジュールは、指示プロンプトのステップを標準化します。このステップでは、ユーザー要求が指示プロンプトとして作成され、応答を取得するために特定の LLM に送信されます。特定のニーズに基づいて、適切なプロンプト方法を選択できます。
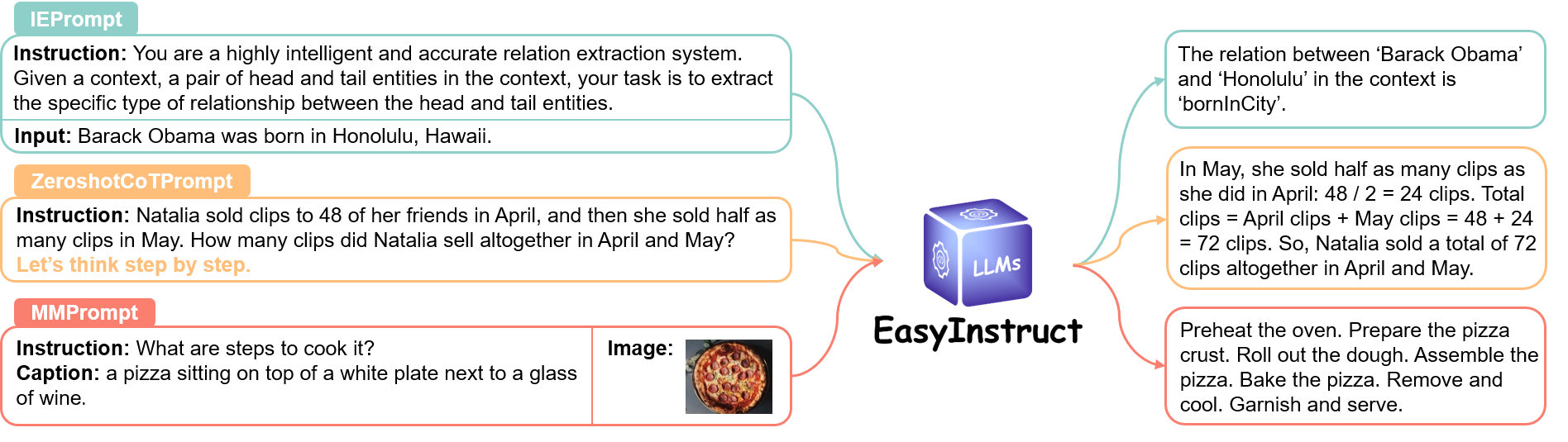
詳細についてはリンクをご覧ください。
Enginesモジュールは命令実行プロセスを標準化し、ローカルに展開された特定の LLM 上で命令プロンプトを実行できるようにします。特定のニーズに基づいて適切なエンジンを選択できます。
詳細についてはリンクをご覧ください。
仕事で EasyInstruct を使用する場合は、リポジトリを引用してください。
@article { ou2024easyinstruct ,
title = { EasyInstruct: An Easy-to-use Instruction Processing Framework for Large Language Models } ,
author = { Ou, Yixin and Zhang, Ningyu and Gui, Honghao and Xu, Ziwen and Qiao, Shuofei and Bi, Zhen and Chen, Huajun } ,
journal = { arXiv preprint arXiv:2402.03049 } ,
year = { 2024 }
}
@misc { knowlm ,
author = { Ningyu Zhang and Jintian Zhang and Xiaohan Wang and Honghao Gui and Kangwei Liu and Yinuo Jiang and Xiang Chen and Shengyu Mao and Shuofei Qiao and Yuqi Zhu and Zhen Bi and Jing Chen and Xiaozhuan Liang and Yixin Ou and Runnan Fang and Zekun Xi and Xin Xu and Lei Li and Peng Wang and Mengru Wang and Yunzhi Yao and Bozhong Tian and Yin Fang and Guozhou Zheng and Huajun Chen } ,
title = { KnowLM: An Open-sourced Knowledgeable Large Langugae Model Framework } ,
year = { 2023 } ,
url = { http://knowlm.zjukg.cn/ } ,
}
@article { bi2023program ,
title = { When do program-of-thoughts work for reasoning? } ,
author = { Bi, Zhen and Zhang, Ningyu and Jiang, Yinuo and Deng, Shumin and Zheng, Guozhou and Chen, Huajun } ,
journal = { arXiv preprint arXiv:2308.15452 } ,
year = { 2023 }
}バグ修正や問題解決、新たなご要望にお応えするための長期メンテナンスを行っております。何か問題がある場合は、私たちに問題を提出してください。
その他の関連プロジェクト
?私たちのプロジェクトでは Self-Instruct のソース コードの一部を利用しており、Self-Instruct の貢献に心から感謝の意を表します。


