DiGIT
1.0.0
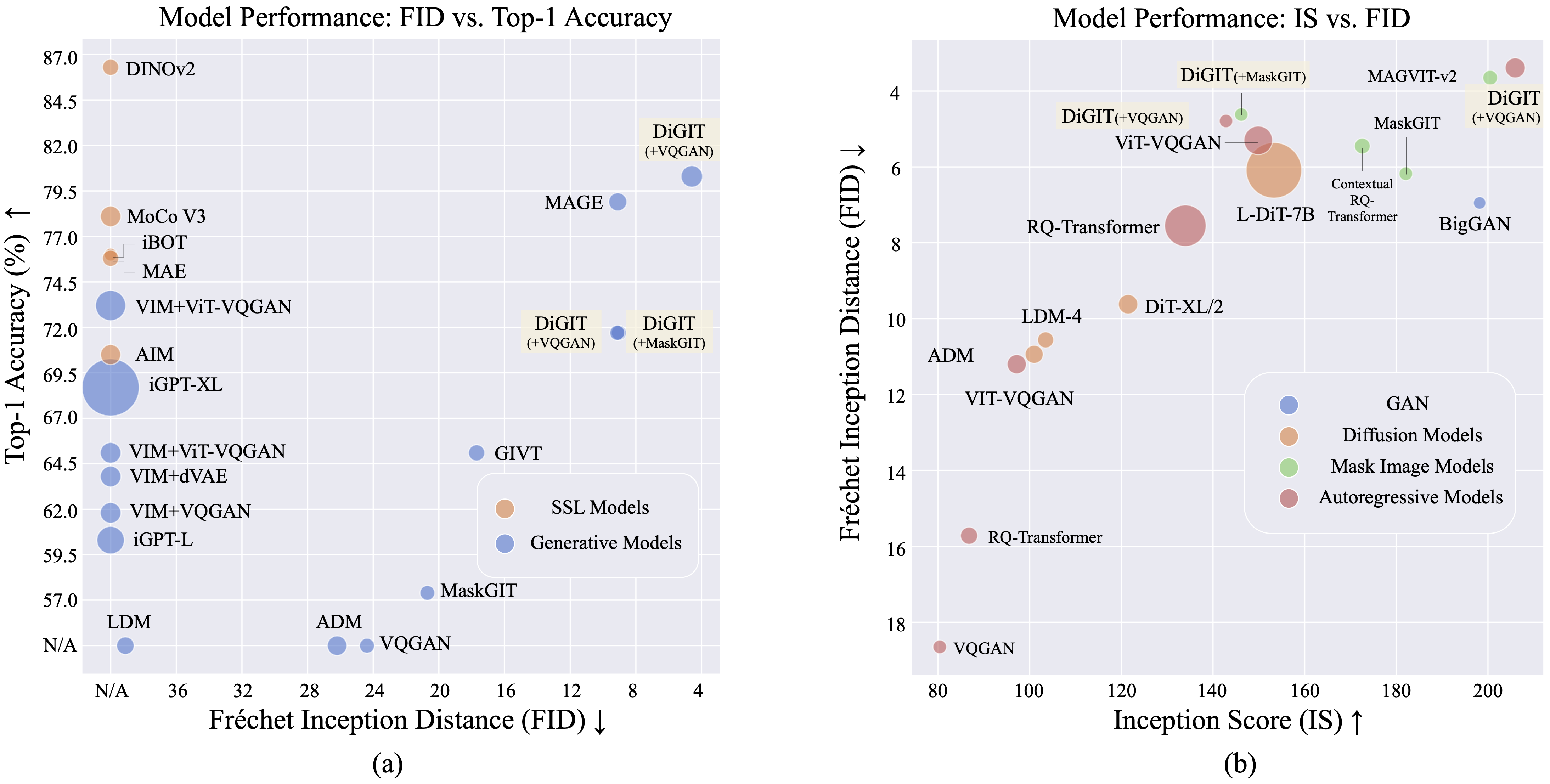
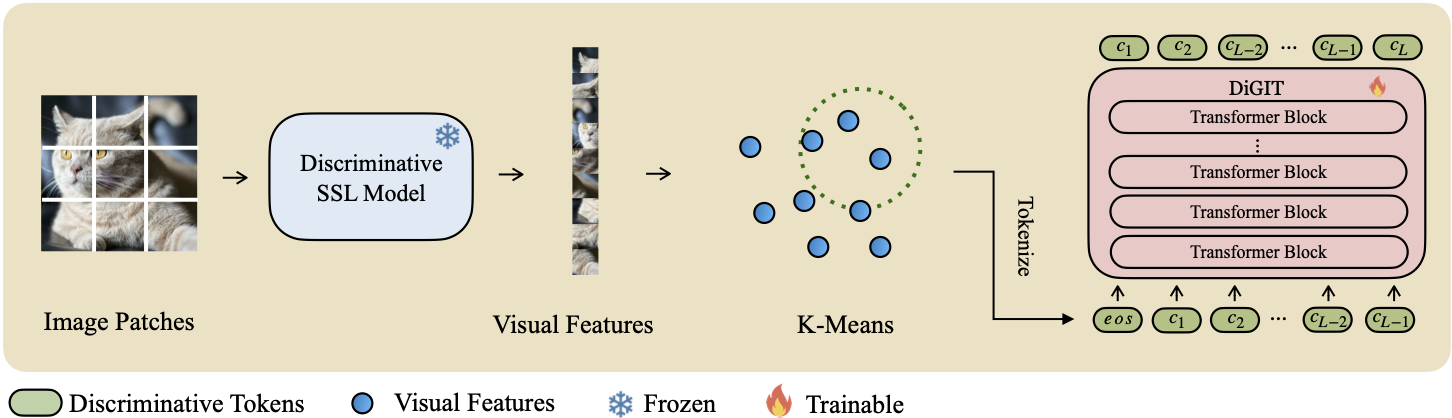
自己教師あり学習 (SSL) モデルから派生した抽象潜在空間で次のトークン予測を実行する自己回帰生成モデルDiGIT を紹介します。 DINOv2 モデルの隠れ状態に K-Means クラスタリングを採用することで、新しい離散トークナイザーを効果的に作成します。この方法により、ImageNet データセットでの画像生成パフォーマンスが大幅に向上し、クラス無条件タスクの FID スコア 4.59 、クラス条件付きタスクの FID スコア 3.39を達成しました。さらに、このモデルは画像の理解を強化し、 80.3 のリニアプローブ精度を達成します。
| メソッド | # トークン | 特徴 | # パラメータ | トップ1のアクセス |
|---|---|---|---|---|
| iGPT-L | 32 | 1536年 | 1362M | 60.3 |
| iGPT-XL | 64 | 3072 | 6801M | 68.7 |
| VIM+VQGAN | 32 | 1024 | 650M | 61.8 |
| VIM+dVAE | 32 | 1024 | 650M | 63.8 |
| VIM+ViT-VQGAN | 32 | 1024 | 650M | 65.1 |
| VIM+ViT-VQGAN | 32 | 2048年 | 1697M | 73.2 |
| 標的 | 16 | 1536年 | 0.6B | 70.5 |
| DiGIT(当社) | 16 | 1024 | 219M | 71.7 |
| DiGIT(当社) | 16 | 1536年 | 732M | 80.3 |
| タイプ | メソッド | # パラメータ | # エポック | FID | は |
|---|---|---|---|---|---|
| ガン | BigGAN | 70M | - | 38.6 | 24.70 |
| 差分。 | LDM | 395M | - | 39.1 | 22.83 |
| 差分。 | ADM | 554M | - | 26.2 | 39.70 |
| MIM | メイジ | 200M | 1600 | 11.1 | 81.17 |
| MIM | メイジ | 463M | 1600 | 9.10 | 105.1 |
| MIM | マスクGIT | 227M | 300 | 20.7 | 42.08 |
| MIM | DiGIT (+マスクGIT) | 219M | 200 | 9.04 | 75.04 |
| AR | VQGAN | 214M | 200 | 24.38 | 30.93 |
| AR | DiGIT (+VQGAN) | 219M | 400 | 9.13 | 73.85 |
| AR | DiGIT (+VQGAN) | 732M | 200 | 4.59 | 141.29 |
| タイプ | メソッド | # パラメータ | # エポック | FID | は |
|---|---|---|---|---|---|
| ガン | BigGAN | 160M | - | 6.95 | 198.2 |
| 差分。 | ADM | 554M | - | 10.94 | 101.0 |
| 差分。 | LDM-4 | 400M | - | 10.56 | 103.5 |
| 差分。 | DiT-XL/2 | 675M | - | 9.62 | 121.50 |
| 差分。 | L-ディット-7B | 7B | - | 6.09 | 153.32 |
| MIM | CQRトランス | 371M | 300 | 5.45 | 172.6 |
| MIM+AR | VAR | 310M | 200 | 4.64 | - |
| MIM+AR | VAR | 310M | 200 | 3.60* | 257.5* |
| MIM+AR | VAR | 600M | 250 | 2.95* | 306.1* |
| MIM | マグビット-v2 | 307M | 1080 | 3.65 | 200.5 |
| AR | VQVAE-2 | 13.5B | - | 11月31日 | 45 |
| AR | RQトランス | 480M | - | 15.72 | 86.8 |
| AR | RQトランス | 3.8B | - | 7.55 | 134.0 |
| AR | ViTVQGAN | 650M | 360 | 11.20 | 97.2 |
| AR | ViTVQGAN | 1.7B | 360 | 5.3 | 149.9 |
| MIM | マスクGIT | 227M | 300 | 6.18 | 182.1 |
| MIM | DiGIT (+マスクGIT) | 219M | 200 | 4.62 | 146.19 |
| AR | VQGAN | 227M | 300 | 18.65 | 80.4 |
| AR | DiGIT (+VQGAN) | 219M | 400 | 4.79 | 142.87 |
| AR | DiGIT (+VQGAN) | 732M | 200 | 3.39 | 205.96 |
*: VAR は分類子を使用しないガイダンスでトレーニングされますが、他のすべてのモデルはそうではありません。
K-Means npy ファイルとモデル チェックポイントは、次からダウンロードできます。
| モデル | リンク |
|---|---|
| HFの重み? | ハグフェイス |
ベースモデルには DINOv2-base を、大規模モデルには DINOv2-large を使用します。使用する VQGAN は MAGE と同じです。
DiGIT
└── data/
├── ILSVRC2012
├── dinov2_base_short_224_l3
├── km_8k.npy
├── dinov2_large_short_224_l3
├── km_16k.npy
└── outputs/
├── base_8k_stage1
├── ...
└── models/
├── vqgan_jax_strongaug.ckpt
├── dinov2_vitb14_reg4_pretrain.pth
├── dinov2_vitl14_reg4_pretrain.pth
git clone https://github.com/DAMO-NLP-SG/DiGIT.git
cd DiGITpip install fairseq fairseqを使用して、fairseq をインストールします。ImageNet データセットをダウンロードし、データセット ディレクトリ$PATH_TO_YOUR_WORKSPACE/dataset/ILSVRC2012に配置します。
SSL 機能を抽出し、.npy ファイルとして保存します。 faiss で K-Means アルゴリズムを使用して重心を計算します。 Huggingface で入手可能な事前トレーニング済みの重心を利用することもできます。
bash preprocess/run.shステップ1
識別トークナイザーを使用して GPT モデルをトレーニングします。トレーニング スクリプトはscripts/train_stage1_ar.shにあり、ハイパーパラメータはconfig/stage1/dino_base.yamlにあります。クラスの条件付き生成の構成については、 scripts/train_stage1_classcond.shを参照してください。
ステップ2
識別トークンを条件としたピクセル デコーダー (AR モデルまたは NAR モデルのいずれか) をトレーニングします。自己回帰トレーニング スクリプトはscripts/train_stage2_ar.shに、NAR トレーニング スクリプトはscripts/train_stage2_nar.shにあります。
チェックポイントを保存するために、 outputs/EXP_NAME/checkpointsという名前のフォルダーが作成されます。 TensorBoard ログ ファイルは、 outputs/EXP_NAME/tbに保存されます。ログはoutputs/EXP_NAME/train.logに記録されます。
tensorboard --logdir=outputs/EXP_NAME/tb使用してトレーニング プロセスを監視できます。
scripts/infer_stage1_ar.shを使用して最初に識別トークンをサンプリングします。基本モデル サイズの場合は、topk=200 を設定し、大きなモデル サイズの場合は、topk=400 を使用することをお勧めします。
次に、 scripts/infer_stage2_ar.shを実行して、以前にサンプリングされた識別トークンに基づいて VQ トークンをサンプリングします。
生成されたトークンと合成されたイメージは、 outputs/EXP_NAME/resultsという名前のディレクトリに保存されます。
FID 評価用に ImageNet 検証セットを準備します。
python prepare_imgnet_val.py --data_path $PATH_TO_YOUR_WORKSPACE /dataset/ILSVRC2012 --output_dir imagenet-val pip install torch-fidelity実行して評価ツールをインストールします。
次のコマンドを実行して FID を評価します。
python fairseq_user/eval_fid.py --results-path $IMG_SAVE_DIR --subset $GEN_SUBSETbash scripts/train_stage1_linearprobe.shこのプロジェクトは MIT ライセンスに基づいてライセンスされています。詳細については、LICENSE ファイルを参照してください。
私たちのプロジェクトが役立つと思われる場合は、私たちのリポジトリにスターを付けて、次のように私たちの成果を引用していただければ幸いです。
@misc { zhu2024stabilize ,
title = { Stabilize the Latent Space for Image Autoregressive Modeling: A Unified Perspective } ,
author = { Yongxin Zhu and Bocheng Li and Hang Zhang and Xin Li and Linli Xu and Lidong Bing } ,
year = { 2024 } ,
eprint = { 2410.12490 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}

