FasterTransformer
v5.3 release
注: FasterTransformer の開発は TensorRT-LLM に移行しました。すべての開発者は、TensorRT-LLM を活用して、LLM 推論の最新の改善を得ることが推奨されます。 NVIDIA/FasterTransformer リポジトリは存続しますが、それ以上の開発は行われません。
このリポジトリは、高度に最適化されたトランスフォーマー ベースのエンコーダーおよびデコーダー コンポーネントを実行するためのスクリプトとレシピを提供し、NVIDIA によってテストおよび保守されています。
NLP では、エンコーダーとデコーダーは 2 つの重要なコンポーネントであり、トランスフォーマー層は両方のコンポーネントで一般的なアーキテクチャになっています。 FasterTransformer は、推論用のエンコーダーとデコーダーの両方に対して高度に最適化されたトランスフォーマー層を実装します。 Volta、Turing、Ampere GPU では、データと重みの精度が FP16 の場合、Tensor コアの計算能力が自動的に使用されます。
FasterTransformer は、CUDA、cuBLAS、cuBLASLt、および C++ 上に構築されています。 TensorFlow、PyTorch、Triton バックエンドのフレームワークの API を少なくとも 1 つ提供します。ユーザーは FasterTransformer をこれらのフレームワークに直接統合できます。サポートするフレームワークについては、使用方法を示し、これらのフレームワークでのパフォーマンスを示すサンプル コードも提供します。
| モデル | フレームワーク | FP16 | INT8 (チューリング後) | スパーシティ (アンペア後) | テンソル並列 | パイプラインパラレル | FP8(ホッパー後) |
|---|---|---|---|---|---|---|---|
| バート | TensorFlow | はい | はい | - | - | - | - |
| バート | パイトーチ | はい | はい | はい | はい | はい | - |
| バート | トリトンバックエンド | はい | - | - | はい | はい | - |
| バート | C++ | はい | はい | - | - | - | はい |
| XLネット | C++ | はい | - | - | - | - | - |
| エンコーダ | TensorFlow | はい | はい | - | - | - | - |
| エンコーダ | パイトーチ | はい | はい | はい | - | - | - |
| デコーダ | TensorFlow | はい | - | - | - | - | - |
| デコーダ | パイトーチ | はい | - | - | - | - | - |
| デコード | TensorFlow | はい | - | - | - | - | - |
| デコード | パイトーチ | はい | - | - | - | - | - |
| GPT | TensorFlow | はい | - | - | - | - | - |
| GPT/OPT | パイトーチ | はい | - | - | はい | はい | はい |
| GPT/OPT | トリトンバックエンド | はい | - | - | はい | はい | - |
| GPT-MoE | パイトーチ | はい | - | - | はい | はい | - |
| 咲く | パイトーチ | はい | - | - | はい | はい | - |
| 咲く | トリトンバックエンド | はい | - | - | はい | はい | - |
| GPT-J | トリトンバックエンド | はい | - | - | はい | はい | - |
| ロングフォーマー | パイトーチ | はい | - | - | - | - | - |
| T5/UL2 | パイトーチ | はい | - | - | はい | はい | - |
| T5 | テンソルフロー 2 | はい | - | - | - | - | - |
| T5/UL2 | トリトンバックエンド | はい | - | - | はい | はい | - |
| T5 | TensorRT | はい | - | - | はい | はい | - |
| T5-MoE | パイトーチ | はい | - | - | はい | はい | - |
| スイングトランス | パイトーチ | はい | はい | - | - | - | - |
| スイングトランス | TensorRT | はい | はい | - | - | - | - |
| ViT | パイトーチ | はい | はい | - | - | - | - |
| ViT | TensorRT | はい | はい | - | - | - | - |
| GPT-NeoX | パイトーチ | はい | - | - | はい | はい | - |
| GPT-NeoX | トリトンバックエンド | はい | - | - | はい | はい | - |
| BART/mBART | パイトーチ | はい | - | - | はい | はい | - |
| ウィーネット | C++ | はい | - | - | - | - | - |
| デベルタ | テンソルフロー 2 | はい | - | - | 進行中 | 進行中 | - |
| デベルタ | パイトーチ | はい | - | - | 進行中 | 進行中 | - |
特定のモデルの詳細は、 docs/のxxx_guide.mdに記載されています。xxx xxxモデル名を意味します。いくつかの一般的な質問とそれぞれの回答はdocs/QAList.mdに記載されています。 Encoder と BERT のモデルは類似しているため、説明をbert_guide.mdにまとめています。
次のコードは、FasterTransformer のディレクトリ構造をリストします。
/src/fastertransformer: source code of FasterTransformer
|--/cutlass_extensions: Implementation of cutlass gemm/kernels.
|--/kernels: CUDA kernels for different models/layers and operations, like addBiasResiual.
|--/layers: Implementation of layer modules, like attention layer, ffn layer.
|--/models: Implementation of different models, like BERT, GPT.
|--/tensorrt_plugin: encapluate FasterTransformer into TensorRT plugin.
|--/tf_op: custom Tensorflow OP implementation
|--/th_op: custom PyTorch OP implementation
|--/triton_backend: custom triton backend implementation
|--/utils: Contains common cuda utils, like cublasMMWrapper, memory_utils
/examples: C++, tensorflow and pytorch interface examples
|--/cpp: C++ interface examples
|--/pytorch: PyTorch OP examples
|--/tensorflow: TensorFlow OP examples
|--/tensorrt: TensorRT examples
/docs: Documents to explain the details of implementation of different models, and show the benchmark
/benchmark: Contains the scripts to run the benchmarks of different models
/tests: Unit tests
/templates: Documents to explain how to add a new model/example into FasterTransformer repo
多くのフォルダーには、異なるモデルを分割するための多くのサブフォルダーが含まれていることに注意してください。量子化ツールは、 examples/tensorflow/bert/bert-quantization/やexamples/pytorch/bert/bert-quantization-sparsity/などのexamplesに移動しました。
FasterTransformer は、デバッグとテストに便利な環境変数をいくつか提供します。
FT_LOG_LEVEL : この環境は、デバッグ メッセージのログ レベルを制御します。詳細については、 src/fastertransformer/utils/logger.hを参照してください。レベルがDEBUGより低い場合、プログラムは大量のメッセージを出力し、プログラムが非常に遅くなることに注意してください。FT_NVTX : FT_NVTX=ON ./bin/gpt_exampleのようにONに設定されている場合、プログラムはプログラムのプロファイリングを支援するために nvtx のタグを挿入します。FT_DEBUG_LEVEL : DEBUGに設定されている場合、プログラムはすべてのカーネルの後にcudaDeviceSynchronize()を実行します。それ以外の場合、カーネルはデフォルトで非同期に実行されます。デバッグ中にエラー箇所を特定するのに役立ちます。ただし、このフラグはプログラムのパフォーマンスに大きな影響を与えます。したがって、これはデバッグのみに使用する必要があります。 ハードウェア設定:
次のベンチマークを実行するには、unix コンピューティング ツール「bc」をインストールする必要があります。
apt-get install bcTensorFlow の FP16 の結果は、 benchmarks/bert/tf_benchmark.sh実行することで取得されました。
TensorFlow の INT8 の結果は、 benchmarks/bert/tf_int8_benchmark.sh実行することで取得されました。
PyTorch の FP16 の結果はbenchmarks/bert/pyt_benchmark.sh実行することで取得されました。
PyTorch の INT8 の結果はbenchmarks/bert/pyt_int8_benchmark.sh実行することで取得されました。
その他のベンチマークはdocs/bert_guide.mdにあります。
次の図は、T4 の FP16 での FasterTransformer と FasterTransformer のさまざまな機能のパフォーマンスを比較しています。
バッチ サイズとシーケンス長が大きい場合、EFF-FT と FT-INT8-v2 の両方で約 2 倍の速度向上が得られます。効果的な FasterTransformer と int8v2 を同時に使用すると、大規模な場合には FasterTransformer FP16 と比較して約 3.5 倍の高速化が可能です。
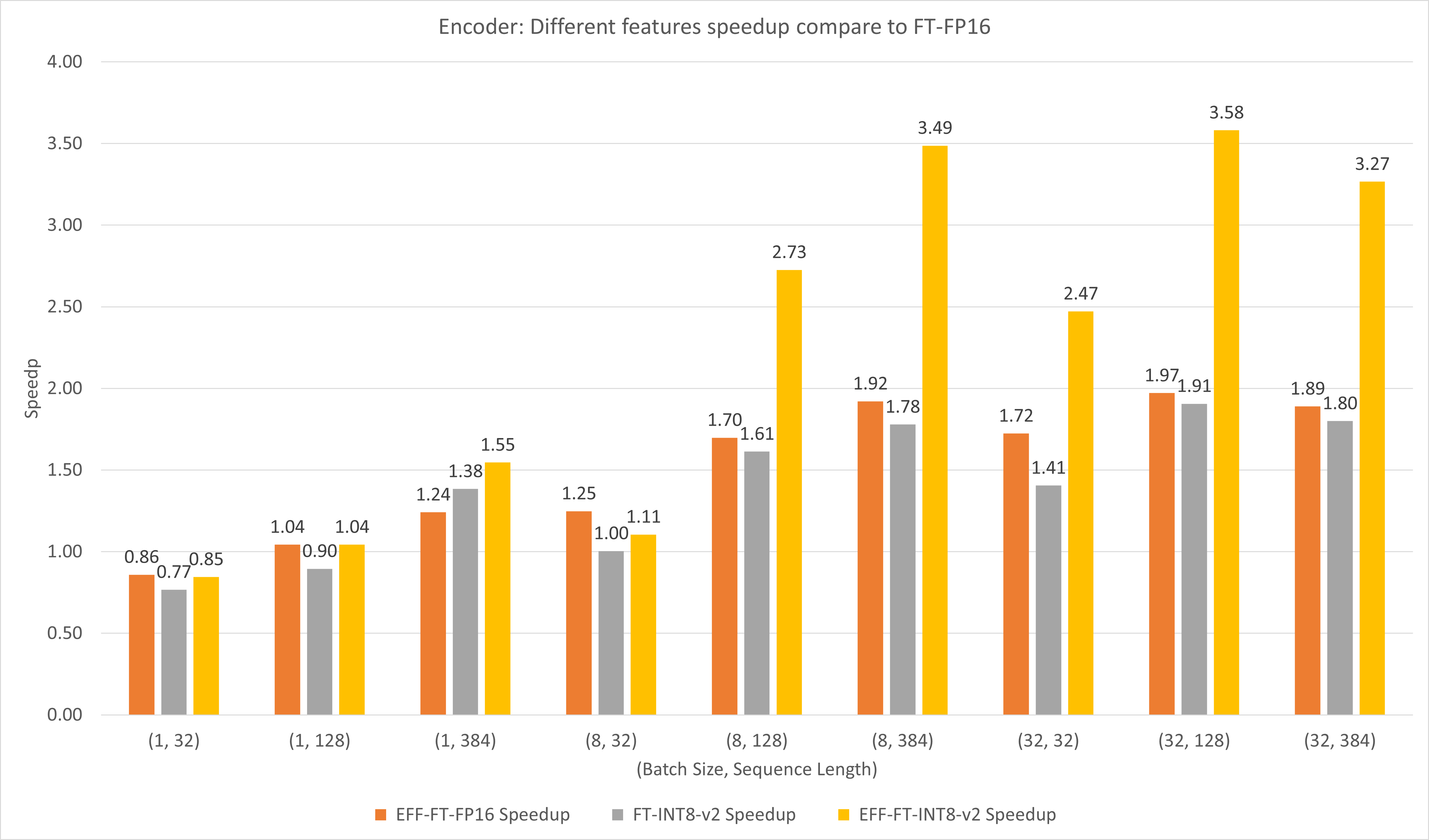
次の図は、T4 の FP16 での FasterTransformer と TensorFlow XLA のさまざまな機能のパフォーマンスを比較しています。
バッチ サイズとシーケンスの長さが小さい場合、FasterTransformer を使用すると約 3 倍の速度向上が得られます。
バッチ サイズとシーケンス長が大きい場合は、Effective FasterTransformer と INT8-v2 量子化を使用すると、約 5 倍の速度向上が得られます。
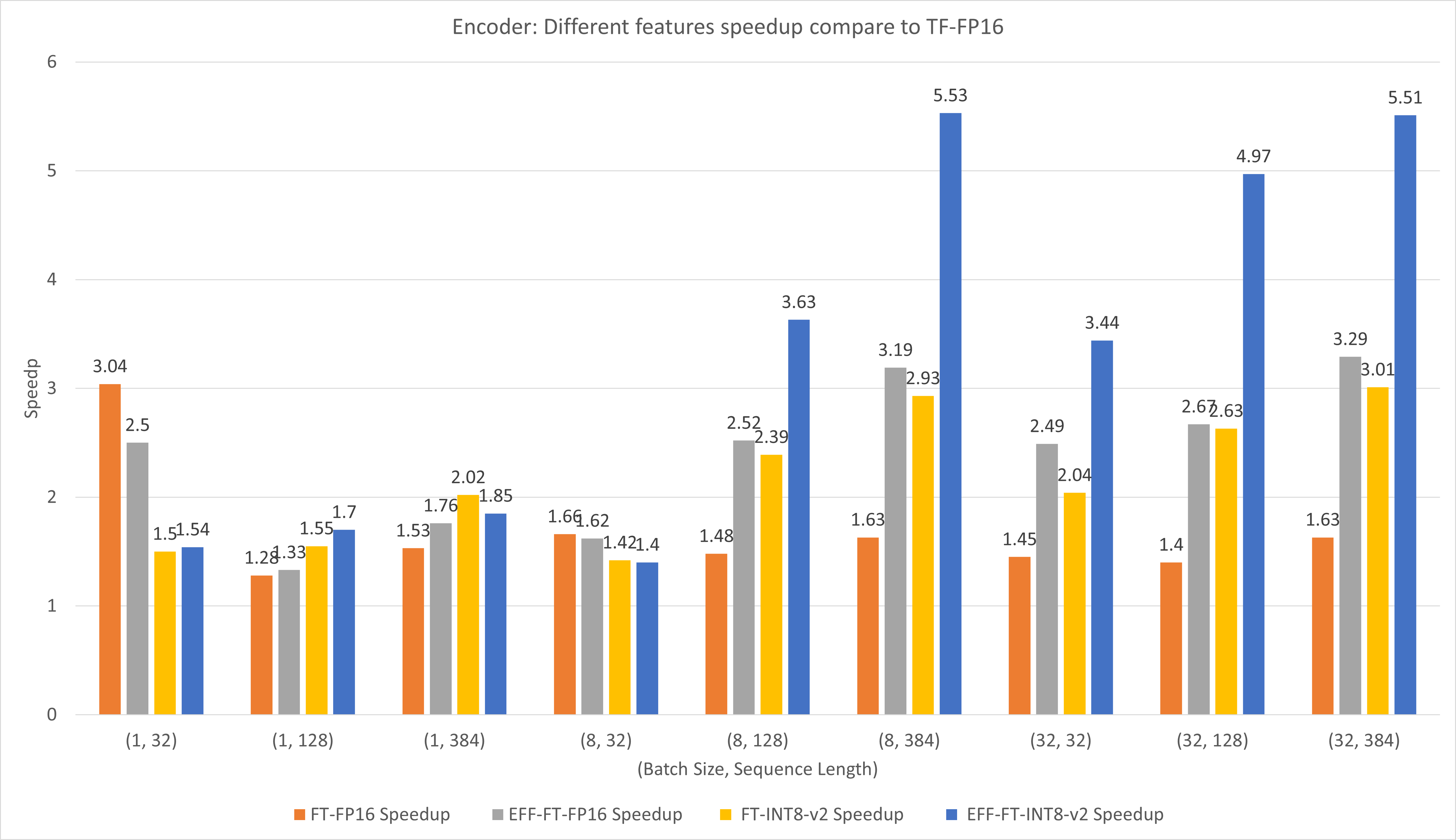
次の図は、T4 の FP16 での FasterTransformer と PyTorch TorachScript のさまざまな機能のパフォーマンスを比較しています。
バッチ サイズとシーケンスの長さが小さい場合、FasterTransformer CustomExt を使用すると、約 4 倍から 6 倍の速度向上が得られます。
バッチ サイズとシーケンス長が大きい場合は、Effective FasterTransformer と INT8-v2 量子化を使用すると、約 5 倍の速度向上が得られます。
TensorFlow の結果はbenchmarks/decoding/tf_decoding_beamsearch_benchmark.shおよびbenchmarks/decoding/tf_decoding_sampling_benchmark.shを実行して取得されました。
PyTorch の結果はbenchmarks/decoding/pyt_decoding_beamsearch_benchmark.sh実行することで取得されました。
デコードの実験では、次のパラメータを更新しました。
その他のベンチマークはdocs/decoder_guide.mdにあります。
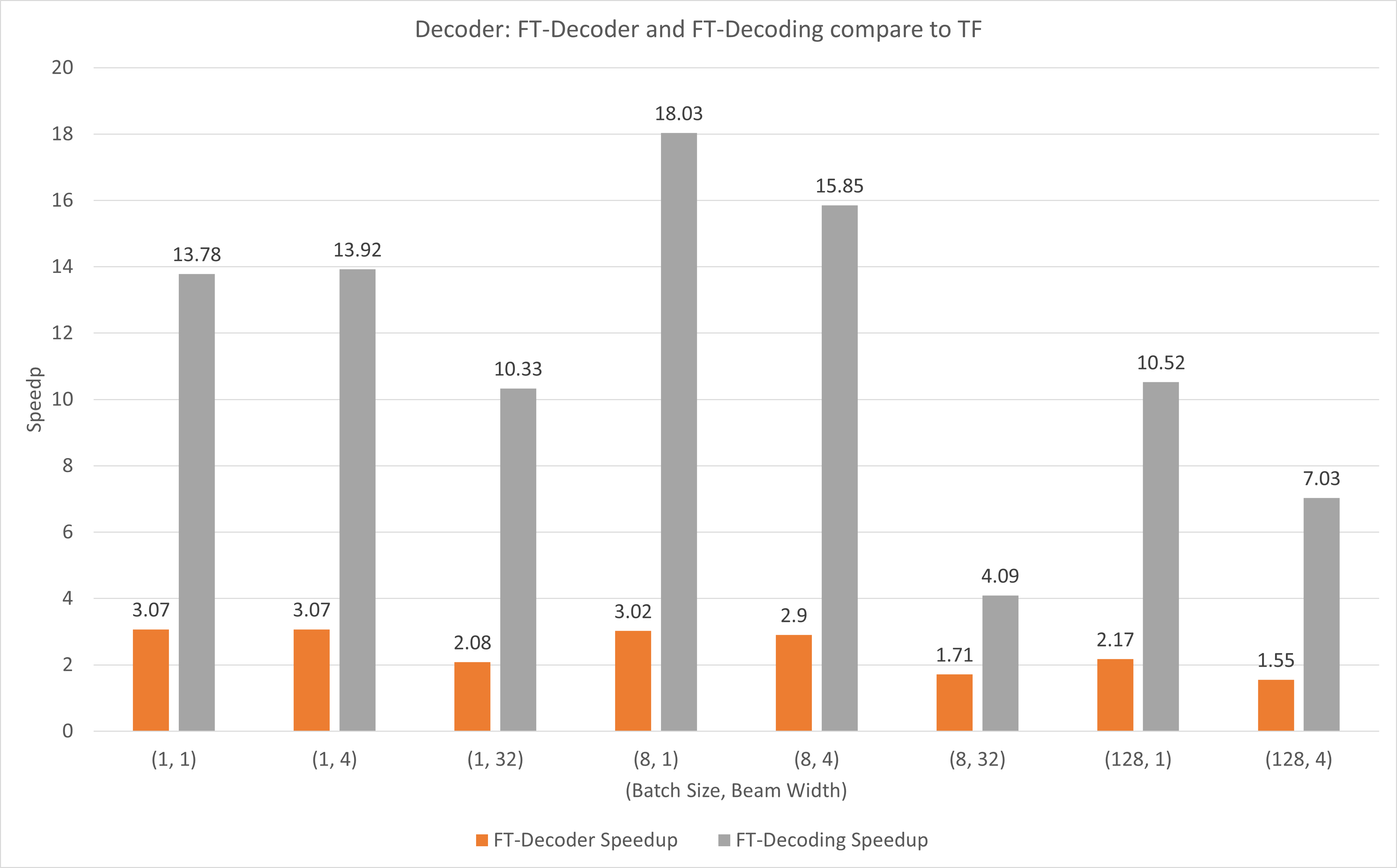
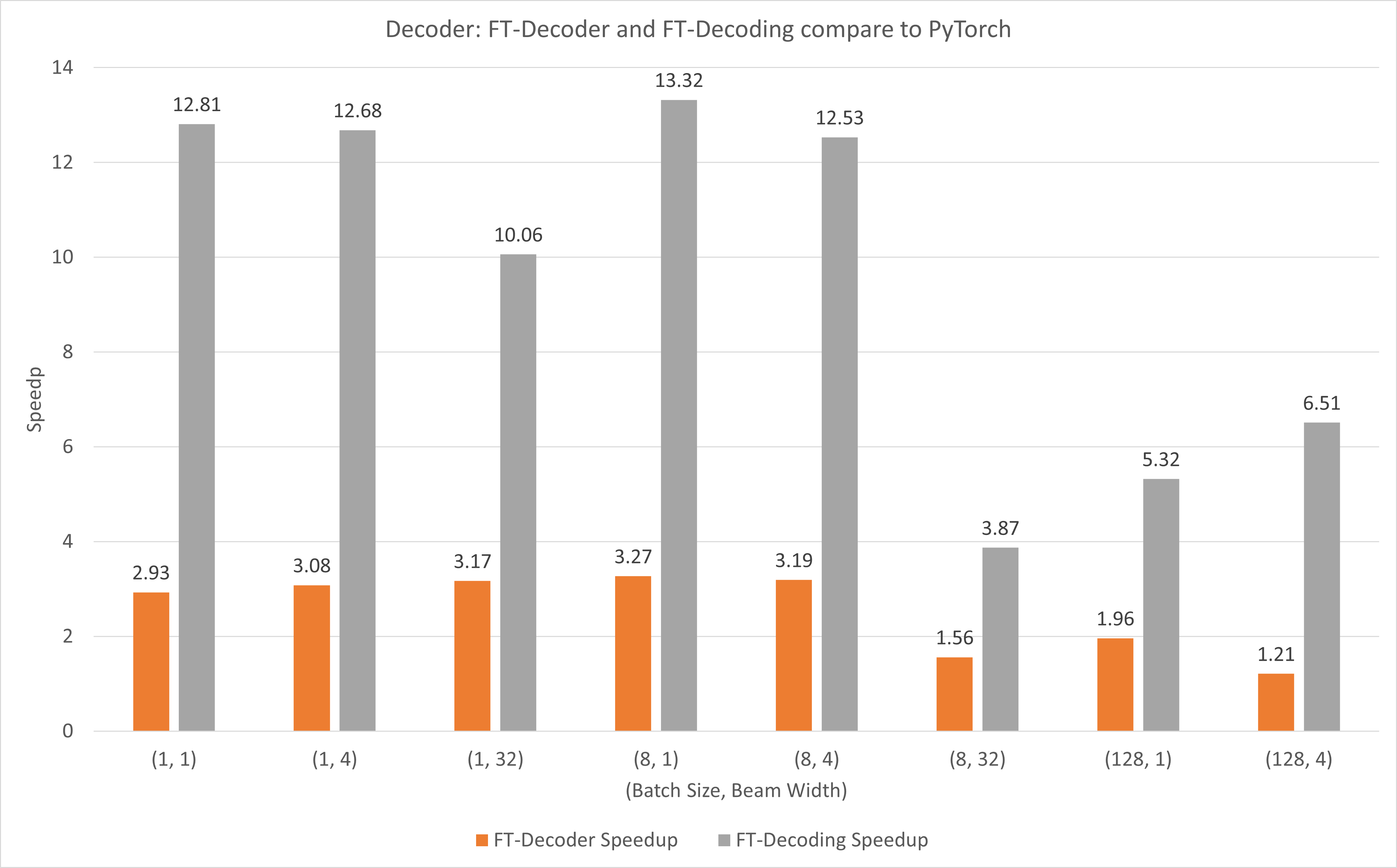
次の図は、T4 を使用した FP16 での TensorFlow と比較した FT-Decoder 演算と FT-Decoding 演算の高速化を示しています。ここでは、各メソッドの合計トークンが異なることを防ぐために、テスト セットの変換のスループットを使用します。 TensorFlow と比較して、FT-Decoder は 1.5 倍から 3 倍の高速化を実現します。一方、FT デコードでは 4 倍から 18 倍の高速化が実現します。
次の図は、T4 を使用した FP16 での PyTorch と比較した FT-Decoder 演算と FT-Decoding 演算の高速化を示しています。ここでは、各メソッドの合計トークンが異なることを防ぐために、テスト セットの変換のスループットを使用します。 PyTorch と比較して、FT-Decoder は 1.2 倍から 3 倍の高速化を実現します。一方、FT デコードでは 3.8 倍から 13 倍の速度向上が得られます。
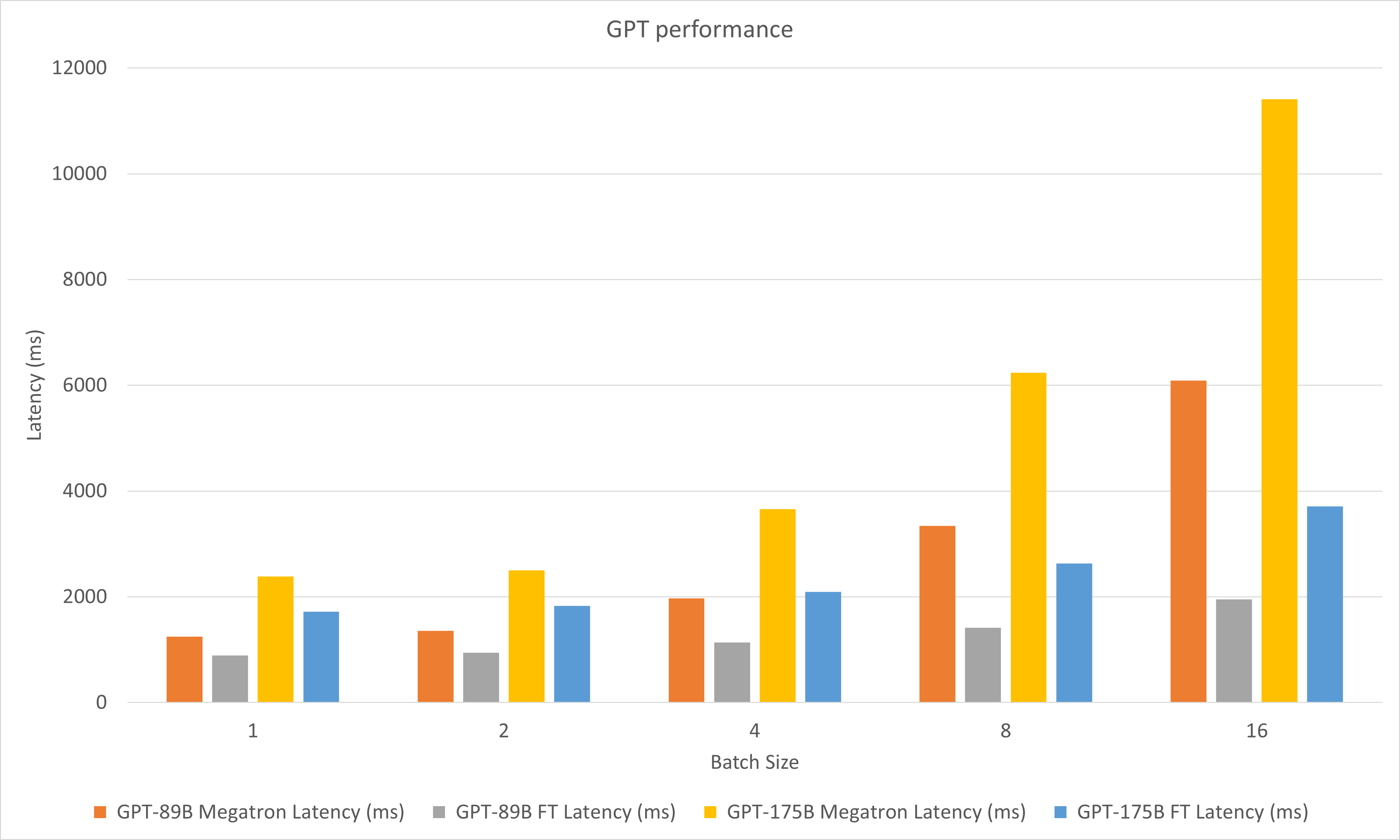
次の図は、A100 の FP16 での Megatron と FasterTransformer のパフォーマンスを比較しています。
デコードの実験では、次のパラメータを更新しました。
2023年5月
2023年1月
2022 年 12 月
2022 年 11 月
2022 年 10 月
2022 年 9 月
2022 年 8 月
2022年7月
2022年6月
2022年5月
2022年4月
2022年3月
stop_idsとban_bad_idsサポートします。start_idとend_idサポートします。2022年2月
2021年12月
2021年11月
2021年8月
layer_para名前をpipeline_paraに変更します。size_per_head 96、160、192、224、256 をサポートします。2021年6月
2021年4月
2020年12月
2020年11月
2020年9月
2020年8月
2020年6月
2020年5月
translate_sample.pyでのモデルの読み込み方法を変更します。2020年4月
decoding_opennmt.h名前をdecoding_beamsearch.hに変更します。decoding_sampling.hにあります。bert_transformer_op.h 、 bert_transformer_op.cu.cc bert_transformer_op.ccにマージします。decoder.h 、 decoder.cu.ccをdecoder.ccにマージします。decoding_beamsearch.h 、 decoding_beamsearch.cu.ccをdecoding_beamsearch.ccにマージします。bleu_score.py utilsに追加します。 BLEU スコアには Python3 が必要であることに注意してください。2020年3月
translate_sample.pyを追加します。2020年2月
2019年7月
import torchください。これが行われた場合は、C++ ABI に互換性がないことが原因です。コンパイルと実行中に使用される PyTorch が同じであることを確認する必要がある場合や、PyTorch がどのようにコンパイルされるか、GCC のバージョンなどを確認する必要がある場合があります。

