PatrickStar
v0.4.6

CHANGE_LOG.mdを参照してください。
事前トレーニング済みモデル (PTM) は、NLP 研究と産業応用の両方のホットスポットになりつつあります。ただし、PTM のトレーニングには膨大なハードウェア リソースが必要なため、AI コミュニティのごく一部の人しか利用できません。 PatrickStar は、PTM トレーニングを誰でも利用できるようにします。
メモリ不足エラー (OOM) は、PTM をトレーニングするすべてのエンジニアにとって悪夢です。このようなエラーを防ぐために、モデル パラメーターを保存するために、より多くの GPU を導入する必要があることがよくあります。 PatrickStar は、このような問題に対してより良い解決策を提供します。ヘテロジニアス トレーニング(DeepSpeed Zero Stage 3 も使用) を使用すると、PatrickStar は CPU と GPU メモリの両方を完全に使用できるため、より少ない GPU を使用してより大きなモデルをトレーニングできます。
パトリックさんのアイデアはこんな感じです。非モデル データ (主にアクティベーション) はトレーニング中に変化しますが、現在の異種トレーニング ソリューションでは、モデル データが CPU と GPU に静的に分割されています。 GPU をより効果的に使用するために、PatrickStar はチャンクベースのメモリ管理モジュールを利用した動的メモリ スケジューリングを提案しています。 PatrickStar のメモリ管理は、GPU を節約するために、モデルの現在のコンピューティング部分以外のすべてを CPU にオフロードすることをサポートしています。さらに、チャンクベースのメモリ管理は、複数の GPU に拡張する場合の集合的な通信に効率的です。 PatrickStar の背後にあるアイデアについては、論文とこのドキュメントを参照してください。
実験では、Patrickstar v0.4.3 は、WeChat データセンター ノードで 8xTesla V100 GPU と 240GB GPU メモリを備えた180 億(18B) パラメータ モデルをトレーニングできます。そのネットワーク トポロジは次のとおりです。 PatrickStar は DeepSpeed の 2 倍以上の大きさです。また、同じサイズのモデルでも PatrickStar のパフォーマンスが優れています。 pstar は PatrickStar v0.4.3 です。 Deeps は、デフォルトでアクティベーションの最適化が開いている公式サンプル DeepSpeed サンプル zero3 ステージを使用した DeepSpeed v0.4.3 のパフォーマンスを示します。

また、A100 SuperPod の単一ノードで PatrickStar v0.4.3 も評価しました。 1TB CPU メモリを搭載した 8xA100 で 68B モデルをトレーニングできます。これは、DeepSpeed v0.5.7 の 6 倍以上です。モデルのスケールに加えて、PatrickStar は DeepSpeed よりもはるかに効率的です。ベンチマークスクリプトはここにあります。

WeChat AI データセンターと NVIDIA SuperPod の詳細なベンチマーク結果は、この Google ドキュメントに掲載されています。
PatrickStar を SuperPod 上の複数のマシン (ノード) にスケールします。 32 GPU で GPT3-175B をトレーニングすることに成功しました。私たちが知る限り、これはこのような小さな GPU クラスター上で GPT3 を実行する最初の作品です。 Microsoft は GPT3 に関連するために 10,000 V100 を使用しました。 32 個の A100 GPU で微調整したり、独自のものを事前トレーニングしたりできるようになりました。これは素晴らしいことです。

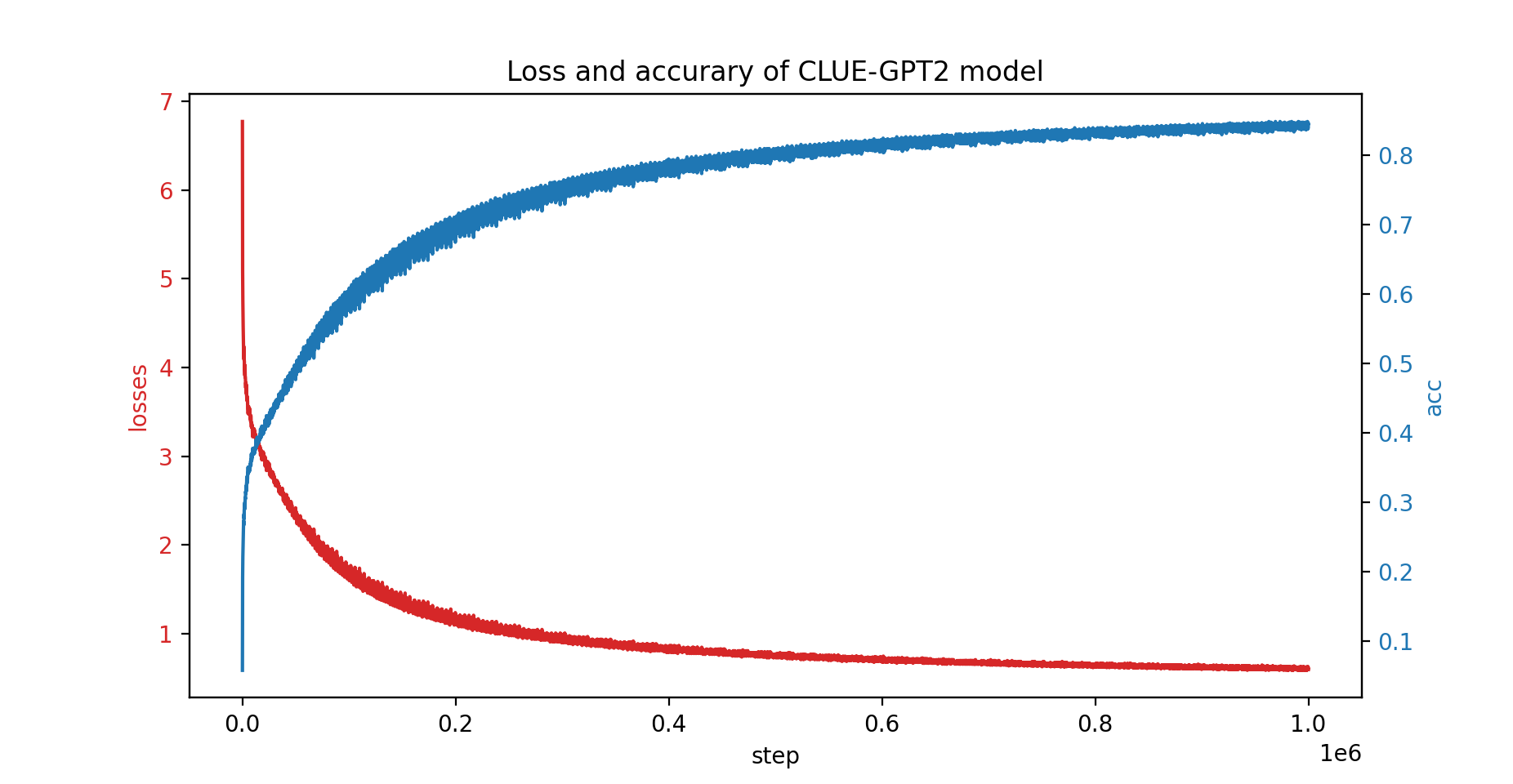
CLUE-GPT2 モデルも PatrickStar でトレーニングしました。損失と精度の曲線を以下に示します。
pip install .PatrickStar にはバージョン 7 以降の gcc が必要であることに注意してください。 NVIDIA NGC イメージを使用することもできます。次のイメージがテストされています。
docker pull nvcr.io/nvidia/pytorch:21.06-py3PatrickStar は PyTorch に基づいているため、pytorch プロジェクトの移行が簡単になります。 PatrickStar の例を次に示します。
from patrickstar . runtime import initialize_engine
config = {
"optimizer" : {
"type" : "Adam" ,
"params" : {
"lr" : 0.001 ,
"betas" : ( 0.9 , 0.999 ),
"eps" : 1e-6 ,
"weight_decay" : 0 ,
"use_hybrid_adam" : True ,
},
},
"fp16" : { # loss scaler params
"enabled" : True ,
"loss_scale" : 0 ,
"initial_scale_power" : 2 ** 3 ,
"loss_scale_window" : 1000 ,
"hysteresis" : 2 ,
"min_loss_scale" : 1 ,
},
"default_chunk_size" : 64 * 1024 * 1024 ,
"release_after_init" : True ,
"use_cpu_embedding" : False ,
"client" : {
"mem_tracer" : {
"use_async_mem_monitor" : args . with_async_mem_monitor ,
}
},
}
def model_func ():
# MyModel is a derived class for torch.nn.Module
return MyModel (...)
model , optimizer = initialize_engine ( model_func = model_func , local_rank = 0 , config = config )
...
for data in dataloader :
optimizer . zero_grad ()
loss = model ( data )
model . backward ( loss )
optimizer . step () DeepSpeed 構成 JSON と同じconfig形式を使用します。これには、主にオプティマイザー、ロス スケーラー、およびいくつかの PatrickStar 固有の構成のパラメーターが含まれます。
上記の例の詳細な説明については、ここのガイドを確認してください。
その他の例については、こちらをご覧ください。
クイックスタート ベンチマーク スクリプトはここにあります。ランダムに生成されたデータを使用して実行されます。したがって、実際のデータを準備する必要はありません。また、patrickstar のすべての最適化テクニックも実証しました。ベンチマークを実行するためのその他の最適化テクニックについては、「最適化オプション」を参照してください。
BSD 3 条項ライセンス
@article{fang2021patrickstar,
title={PatrickStar: Parallel Training of Pre-trained Models via a Chunk-based Memory Management},
author={Fang, Jiarui and Yu, Yang and Zhu, Zilin and Li, Shenggui and You, Yang and Zhou, Jie},
journal={arXiv preprint arXiv:2108.05818},
year={2021}
}
@article{fang2022parallel,
title={Parallel Training of Pre-Trained Models via Chunk-Based Dynamic Memory Management},
author={Fang, Jiarui and Zhu, Zilin and Li, Shenggui and Su, Hui and Yu, Yang and Zhou, Jie and You, Yang},
journal={IEEE Transactions on Parallel and Distributed Systems},
volume={34},
number={1},
pages={304--315},
year={2022},
publisher={IEEE}
}
{jiaruifang、zilinzhu、josephyu}@tencent.com
WeChat AI チーム、Tencent NLP Oチームが提供します。


