ComfyUI N Nodes
1.0.0
整数、文字列、浮動小数点変数ノード、GPT ノード、ビデオ ノードを含む ComfyUI 用のカスタム ノードのスイート。
重要
これらのノードは主に Windows で、ComfyUI によって提供されるデフォルト環境と、特に cyberes/gradient-base-py3.10:latest docker イメージを使用してペーパースペース用のノートブックによって作成された環境でテストされました。他の環境はテストされていません。
リポジトリのクローンを作成します: git clone https://github.com/Nuked88/ComfyUI-N-Nodes.git
ComfyUIのcustom_nodesディレクトリへ
重要: GPU 上に GPT ノードが必要な場合は、 install_dependency Bat files を実行する必要があります。古い ggmlv3 モデル用のinstall_dependency_ggml_models.batと、すべての新しいモデル (GGUF) 用のinstall_dependency_gguf_models.batの 2 つのバージョンがあります。一度に使用できるのは 1 つだけです。 llama-cpp-python はGPU を使用できるようにするためにソース コードからコンパイルする必要があるため、コンパイルするにはまず CUDA と Visual Studio 2019 または 2022 (私のバットの場合) をインストールする必要があります。詳細と完全なガイドについては、こちらをご覧ください。
Moondream モデルで GPTLoaderSimple を使用する場合は、「install_extra.bat」スクリプトを実行する必要があります。これにより、トランスフォーマー バージョン 4.36.2 がインストールされます。
ComfyUI を再起動する
(他のノードとの互換性がないため) これらの変更を元に戻す必要がある場合は、「remove_extra.bat」スクリプトを利用できます。
ComfyUI は起動時にすべてのカスタム スクリプトとノードを自動的に読み込みます。
注記
llama-cpp-python のインストールはスクリプトによって自動的に行われます。 NVIDIA GPU を使用している場合は、jllllll リポジトリのおかげで、CUDA ビルドは必要ありません。また、注目すべきすべてのモデルはすでに GGUF の最新バージョンに切り替わっているはずなので、GGMLv3 モデルへのサポートも中止しました。
注記
2024 年 2 月 14 日以降、ノードは大規模な書き換えを受け、将来的に他の拡張機能との競合を避けるために、すべてのノード名も変更されました (少なくとも私はそう願っています)。その結果、古いワークフローには互換性がなくなり、各ノードを手動で交換する必要があります。これを回避するために、自動置換を可能にするツールを作成しました。 Windows では、*.json ワークフローを (custom_nodes/ComfyUI-N-Nodes) にある merge.bat ファイルにドラッグするだけで、接尾辞 _maigled が付いた別のワークフローが現在のワークフローと同じフォルダーに作成されます。 Linux では、スクリプトを次の方法で使用できます: python libs/merge.py path/to/original/workflow/。セキュリティ上の理由から、元のワークフローは削除されません。」 Comfyui-N-Suite から変更される前に、このリポジトリの最後のバージョンをインストールするには、 git checkout 29b2e43baba81ee556b2930b0ca0a9c978c47083を実行してください。
custom_nodes内のComfyUI-N-Nodesフォルダーを削除します。ComfyUIwebextensionsのcomfyui-n-nodesフォルダーを削除します。ComfyUIstylesにあるn-styles.csvおよびn-styles.csv.backupファイルを削除します。ComfyUImodelsのGPTcheckpointsフォルダーを削除します。custom_nodes/ComfyUI-N-Nodes 。git pull
LoadVideoAdvanced ノードを使用すると、ビデオ ファイルをロードし、そこからフレームを抽出できます。 LoadVideo animeiff ノードとの競合を避けるために、名前がLoadVideoからLoadVideoAdvancedに変更されました。
video : ロードするビデオ ファイルを選択します。framerate : 元のフレームレートを維持するか、半分または 4 分の 1 の速度に下げるかを選択します。resize_by : フレームのサイズを変更する方法を「なし」、「高さ」、または「幅」から選択します。size : 高さまたは幅によってサイズ変更する場合のターゲット サイズ。images_limit : 抽出するフレーム数を制限します。batch_size : フレームをエンコードするためのバッチ サイズ。starting_frame : どのフレームから開始するかを選択します。autoplay : ビデオを自動再生するかどうかを選択します。use_ram : ビデオ フレームの解凍にディスクの代わりに RAM を使用します。 IMAGES : PyTorch tensor として抽出されたフレーム画像。LATENT : 空の潜在ベクトル。METADATA : ビデオのメタデータ - FPS とフレーム数。WIDTH:フレームの幅。HEIGHT : フレームの高さ。META_FPS : フレームレート。META_N_FRAMES : フレーム数。ノードは、指定されたフレームレートで入力ビデオからフレームを抽出します。選択されている場合はフレームのサイズを変更し、潜在ベクトル、メタデータ、フレーム寸法とともに PyTorch 画像テンソルのバッチとして返します。
SaveVideo ノードは抽出されたフレームを取り込み、ビデオ ファイルとして保存し直します。 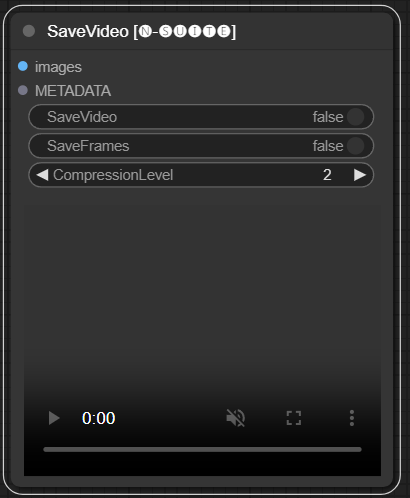
images : 画像をテンソルとしてフレーム化します。METADATA : LoadVideo ノードからのメタデータ。SaveVideo : 出力ビデオ ファイルの保存を切り替えます。SaveFrames : フレームをフォルダーに保存するかどうかを切り替えます。CompressionLevel : フレームを保存するための PNG 圧縮レベル。 出力ビデオ ファイルや抽出されたフレームを保存します。
ノードは抽出されたフレームとメタデータを取得し、それらを新しいビデオ ファイルや個別のフレーム画像として保存できます。ビデオ圧縮とフレーム PNG 圧縮を設定できます。注: フレームのソースとしてLoadVideo を使用している場合、元のファイルのオーディオは維持されますが、 images_limitとstarting_frameがゼロに等しい場合に限ります。
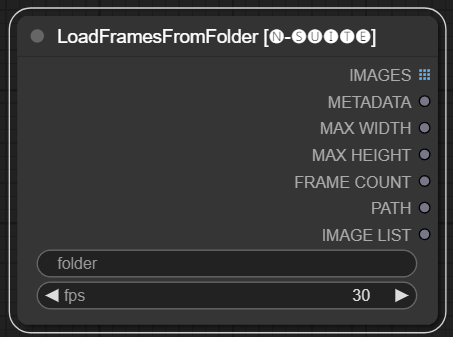
LoadFramesFromFolder ノードを使用すると、フォルダーから画像フレームをロードし、バッチとして返すことができます。
folder : フレーム画像を含むフォルダーへのパス。番号を付けた名前の png 形式である必要があります (例: 1.png または 0001.png)。画像は順番にロードされます。fps : ロードされたフレームに割り当てる 1 秒あたりのフレーム数。 IMAGES : PyTorch テンソルとしてロードされたフレーム イメージのバッチ。METADATA : 設定された FPS 値を含むメタデータ。MAX_WIDTH : 最大フレーム幅。MAX_HEIGHT : フレームの最大高さ。FRAME COUNT : フォルダー内のフレーム数。PATH : フレーム画像が含まれるフォルダーへのパス。IMAGE LIST : フォルダー内のフレーム画像のリスト (実際のリストではなく、文字列を n で割ったものです)。このノードは、指定されたフォルダーからすべての画像ファイルをロードし、それらを PyTorch テンソルに変換し、設定された FPS 値を含む単純なメタデータとともにバッチ化されたテンソルとして返します。
これにより、以前に抽出して保存した一連のフレームを簡単にロードして、たとえば再ロードして再度処理することができます。 FPS 値を設定することにより、フレームをビデオ シーケンスとして適切に解釈できます。
SetMetadataForSaveVideo ノードを使用すると、SaveVideo ノードのメタデータを設定できます。
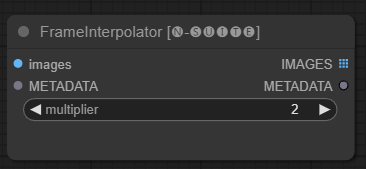
FrameInterpolator ノードを使用すると、抽出されたビデオ フレーム間を補間して、フレーム レートとスムーズなモーションを向上させることができます。
images : テンソルとして抽出されたフレーム画像。METADATA : ビデオからのメタデータ - FPS とフレーム数。multiplier : フレーム レートを増加させる係数。 IMAGES : 画像テンソルとして補間されたフレーム。METADATA : 新しいフレームレートでメタデータを更新しました。ノードは、抽出されたフレームとメタデータを入力として受け取ります。補間モデル (RIFE) を使用して、より高いフレーム レートで追加の中間フレームを生成します。
メタデータ内の元のフレーム レートにmultiplier数値を乗算して、新しい補間フレーム レートを取得します。
補間されたフレームは、新しいフレーム レートを含む更新されたメタデータとともに、イメージ テンソルのバッチとして返されます。
これにより、既存のビデオのフレーム レートを上げて、よりスムーズな動きとより遅い再生を実現できます。補間モデルは、既存のフレームを単に複製するのではなく、ギャップを埋めるために新しい現実的なフレームを作成します。
元のコードはここから取得されました
プリミティブ ノードにはリンクの制限があるため (たとえば、私が書いている時点では、別の ksampler の「start_at_step」と「steps」を一緒にリンクすることはできません)、この制限を回避するためにこれらの単純なノード変数を作成することにしました。変数は次のとおりです。
これらのカスタム ノードは、GGUF GPT モデルを使用したテキスト生成を有効にすることで、ConfyUI フレームワークの機能を強化するように設計されています。この README では、2 つのカスタム ノードと、ConfyUI 内でのそれらの使用法の概要を説明します。
次の方法で、モデル GGUF が存在するパスをextra_model_paths.yamlに追加できます (例)。
other_ui: base_path: I:\text-generation-webui GPTcheckpoints: models/
それ以外の場合は、ComfyUI のモデル フォルダーに GPTcheckpoints フォルダーが作成され、そこに .gguf モデルを配置できます。
LLava モデルの「GPTcheckpoints」フォルダー内の「Llava」ディレクトリ内に 2 つのフォルダーも作成されています。
clips : このフォルダーは、LLava モデルのクリップ (通常はリポジトリ内のmmで始まるファイル) を保存するために指定されています。 models : このフォルダーは、LLava モデルを保存するために指定されています。
このノードは実際に 4 つの異なるモデルをサポートしています。
GGUF モデルは、Huggingface Hub からダウンロードできます。
ここに、borcuapab による GGUF モデルの使用例のビデオがあります。
このノードでサポートされているモデルの小さなリストを次に示します。
Llava 1.5 7B Llava 1.5 13B Llava 1.6 ミストラル 7B BakLLaVa ヌース ヘルメス 2 ビジョン
####Llava モデルの例: 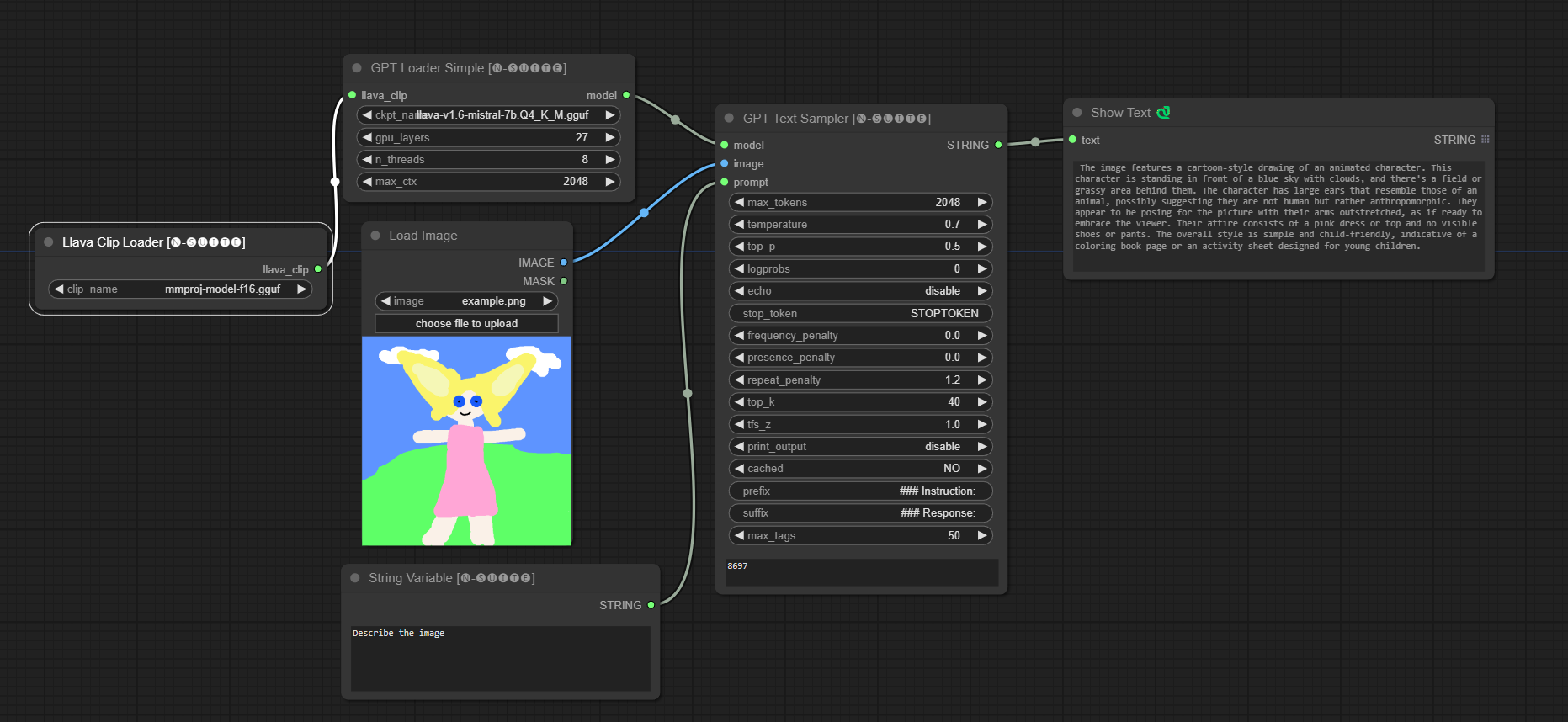
モデルは初回実行時に自動的にダウンロードされます。とにかく、ここから入手できます このリポジトリから取得したコード
####Moondream モデルの例: 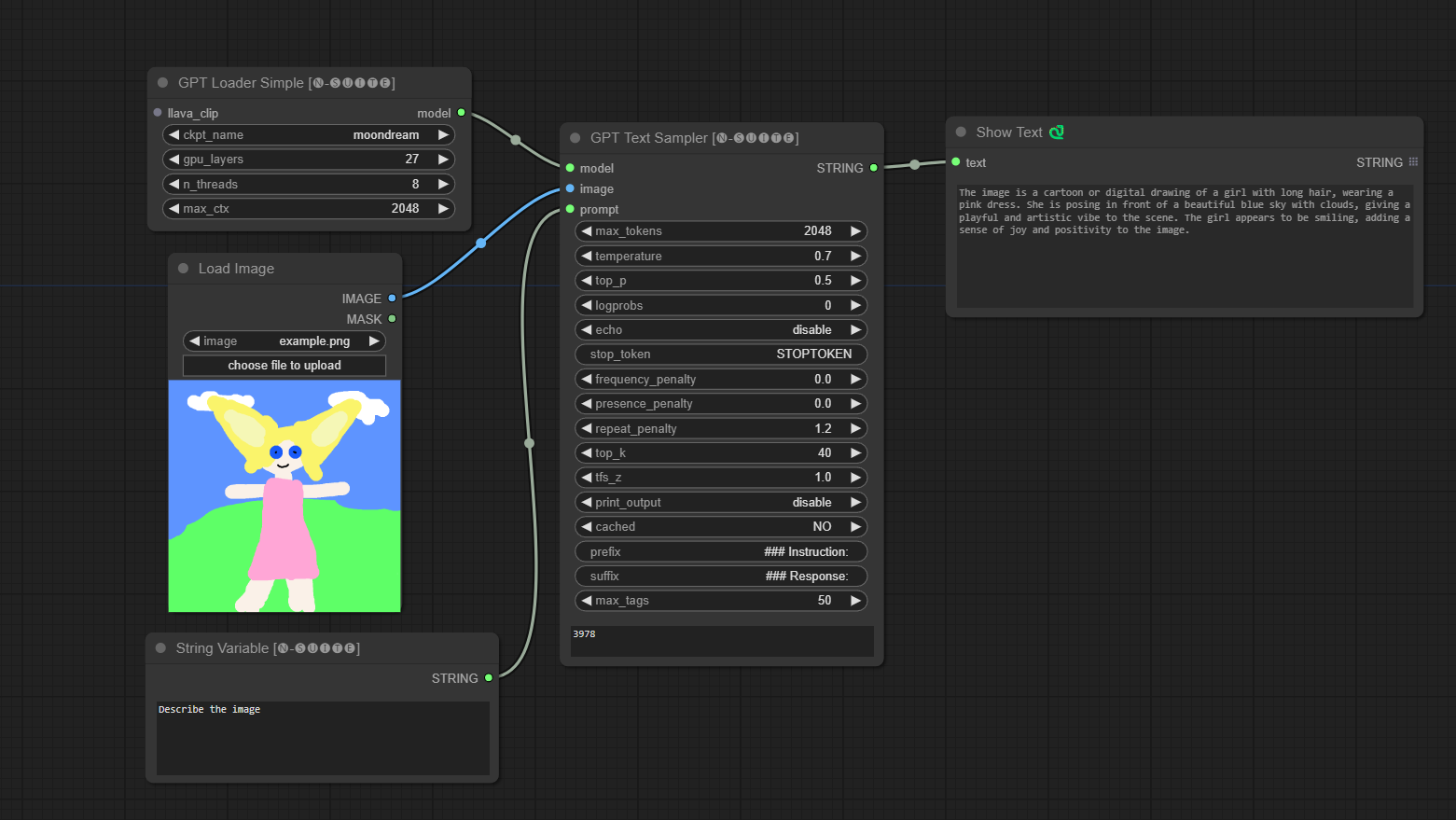
モデルは初回実行時に自動的にダウンロードされます。とにかく、ここから入手できます このリポジトリから取得したコード
####ジョイタグ モデルの例: 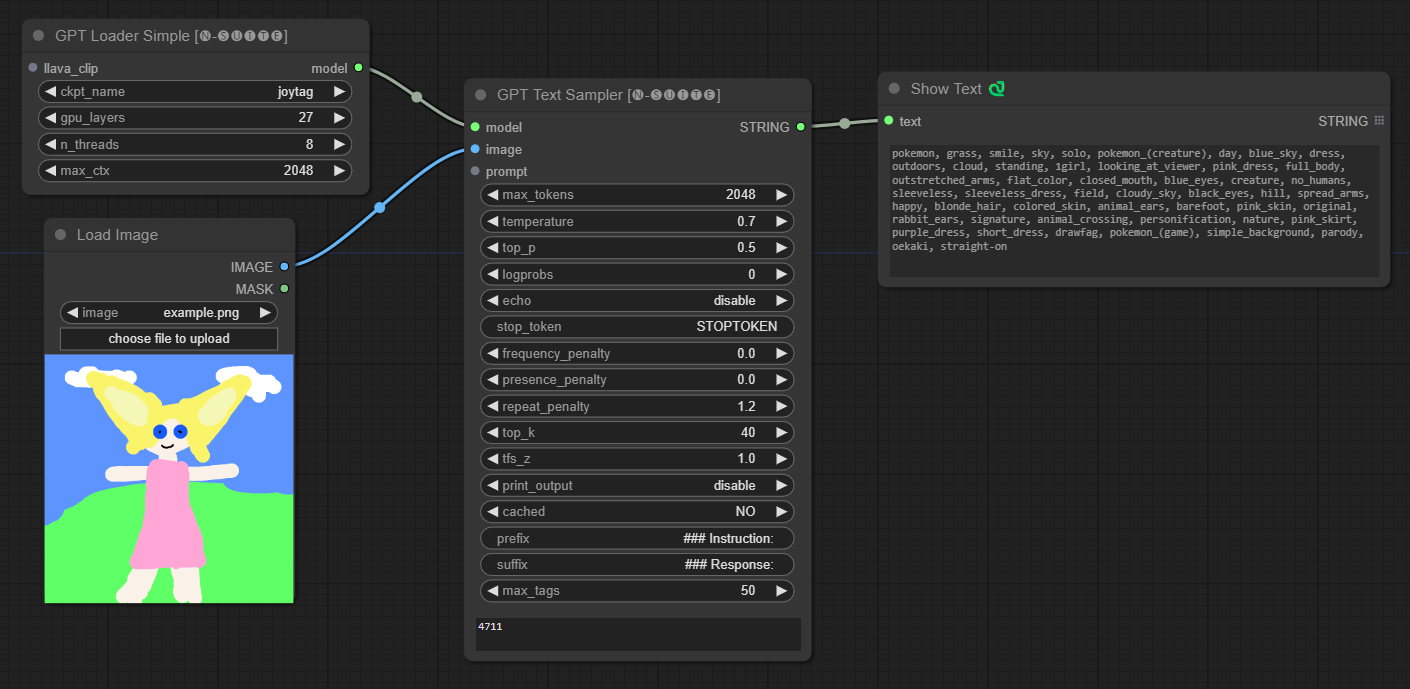
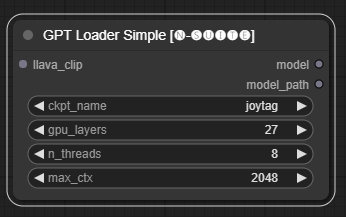
GPTLoaderSimpleノードは、GPT モデル チェックポイントをロードし、テキスト生成用の Llama ライブラリのインスタンスを作成する役割を果たします。 GPU レイヤー、スレッド数、テキスト生成の最大コンテキストを設定するためのインターフェイスを提供します。
ckpt_name : 利用可能なオプションから GPT チェックポイント名を選択します (ジョイタグとムーンドリームは初回使用時に自動的にダウンロードされます)。gpu_layers : 使用する GPU レイヤーの数を指定します (デフォルト: 27)。n_threads : テキスト生成のスレッド数を指定します (デフォルト: 8)。max_ctx : テキスト生成の最大コンテキスト長を指定します (デフォルト: 2048)。 ノードは、Llama ライブラリのインスタンス (MODEL) とロードされたチェックポイントへのパス (STRING) を返します。
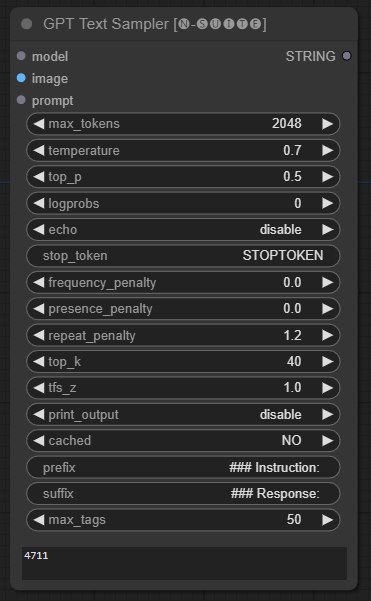
GPTSamplerノードは、入力プロンプトとさまざまな生成パラメーターに基づいて GPT モデルを使用してテキスト生成を容易にします。これにより、温度、上位サンプリング、ペナルティなどの側面を制御できます。
prompt : テキスト生成のための入力プロンプトを入力します。image : Joytag、moondream、llava モデルの画像入力。model : テキスト生成に使用する GPT モデルを選択します。max_tokens : 生成されるテキスト内のトークンの最大数を設定します (デフォルト: 128)。temperature : ランダム性の温度パラメータを設定します (デフォルト: 0.7)。top_p : 核サンプリングの上位 p 確率を設定します (デフォルト: 0.5)。logprobs : 出力するログ確率の数を指定します (デフォルト: 0)。echo : 生成されたテキストと一緒に入力プロンプトを印刷することを有効または無効にします。stop_token : テキスト生成を停止するトークンを指定します。frequency_penalty 、 presence_penalty 、 repeat_penalty : 制御ワード生成ペナルティ。top_k : 生成時に考慮する上位 k 個のトークンを設定します (デフォルト: 40)。tfs_z : 頻度の高いサンプルの温度スケーリング係数を設定します (デフォルト: 1.0)。print_output : 生成されたテキストのコンソールへの出力を有効または無効にします。cached : キャッシュされた生成を使用するかどうかを選択します (デフォルト: NO)。prefix 、 suffix : プロンプトの前後に追加するテキストを指定します。max_tags : これは、joydag によって生成されるタグの最大数にのみ影響します。 このノードは、生成されたテキストを UI に適した表現とともに返します。
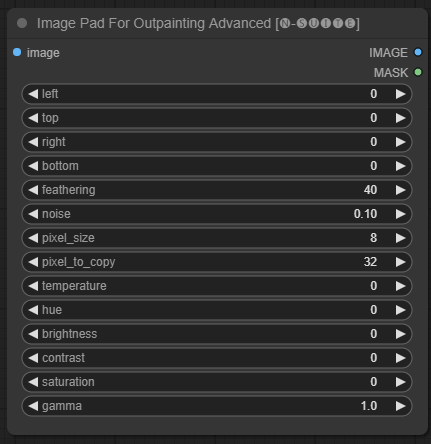
ImagePadForOutpaintingAdvancedノードは、このビデオで見られる技術をアウトペイント マスクの下に適用するImagePadForOutpaintingノードの代替です。色補正部分は、Sipherxyz のこのカスタム ノードから取得されました。
image : 画像入力。left : 左から拡張するピクセル、top : 上から拡張するピクセル、right : 右から拡張するピクセル、bottom : 下から拡張するピクセル。feathering : フェザリングの強さnoise : ノイズとコピーされた境界線の強度をブレンドします。pixel_size : ピクセル化されたエフェクトのピクセルの大きさpixel_to_copy : (両側から) コピーするピクセル数temperature : マスク部分にのみ適用される色補正設定。hue : マスク部分のみに適用される色補正設定。brightness : マスク部分にのみ適用される色補正設定。contrast : マスク部分にのみ適用される色補正設定。saturation : マスク部分にのみ適用される色補正設定。gamma : マスク部分のみに適用される色補正設定。 ノードは処理された画像とマスクを返します。

DynamicPromptノードは、固定プロンプトと変数プロンプトからランダムに選択されたタグを組み合わせてプロンプトを生成します。これにより、さまざまなユースケースに合わせて柔軟かつ動的なプロンプト生成が可能になります。
variable_prompt : タグ選択用の変数プロンプトを入力します。cached : 生成されたプロンプトをキャッシュするかどうかを選択します (デフォルト: NO)。number_of_random_tag : 含めるランダムなタグの数を「固定」または「ランダム」から選択します。fixed_number_of_random_tag : 「固定」の場合、 number_of_random_tag含めるランダムなタグの数を指定します (デフォルト: 1)。fixed_prompt (オプション): 最終プロンプトを生成するための固定プロンプトを入力します。 ノードは、固定プロンプトと選択されたランダム タグの組み合わせである、生成されたプロンプトを返します。
variable_promptフィールドにカンマ区切りのタグを入力するだけですfixed_promptはオプションです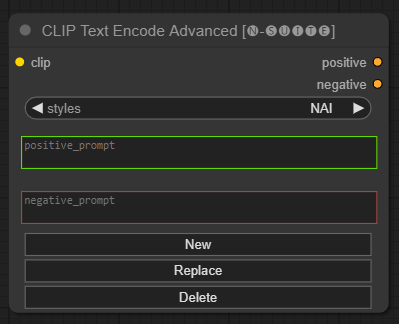
CLIP Text Encode Advancedノードは、標準のCLIP Text Encodeノードの代替です。追加/置換/削除スタイルのサポートを提供し、単一ノード内に肯定的なプロンプトと否定的なプロンプトの両方を含めることができます。
基本スタイル ファイルはn-styles.csvと呼ばれ、 ComfyUIstylesフォルダーにあります。スタイル ファイルは、A1111 で使用されている現在のstyles.csvファイルと同じ形式に従います (執筆時点)。
注: このメモは実験的なものであり、まだ多くのバグがあります。
clip : クリップ入力style : 選択したスタイルに基づいて、肯定的なプロンプトと否定的なプロンプトを自動的に入力します。 positive : ポジティブな条件negative : ネガティブな条件問題を報告したり、改善を提案したりして、お気軽にこのプロジェクトに貢献してください。 GitHub リポジトリで問題を開くか、プル リクエストを送信します。
このプロジェクトは MIT ライセンスに基づいてライセンスされています。詳細については、LICENSE ファイルを参照してください。


