langchain opensearch ラグ
1.0.0
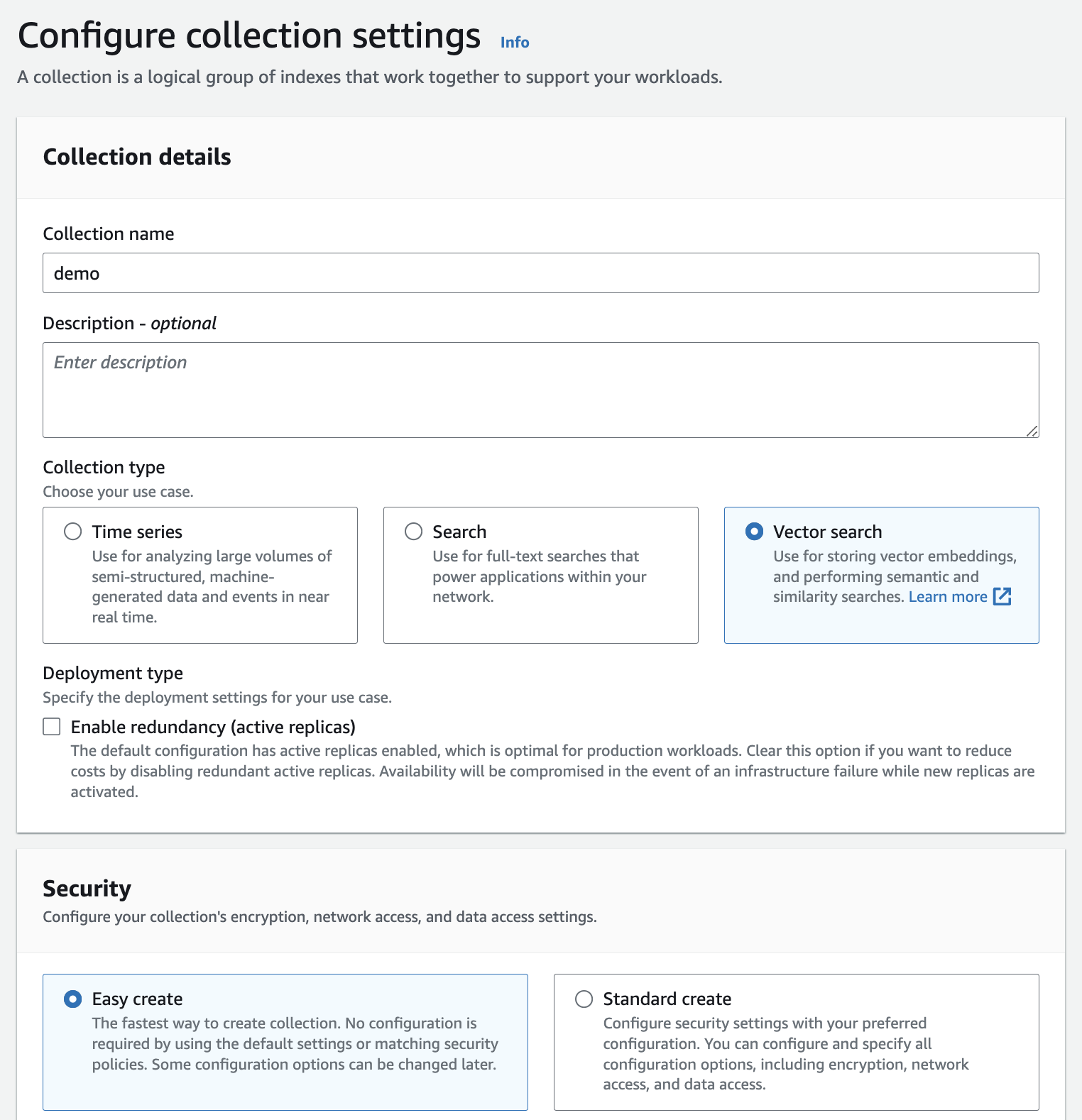
Amazon OpenSearch サーバーレス コレクションを作成する ( 「Vector search」と入力し、 [Easy create]オプションを選択します) - ドキュメント。
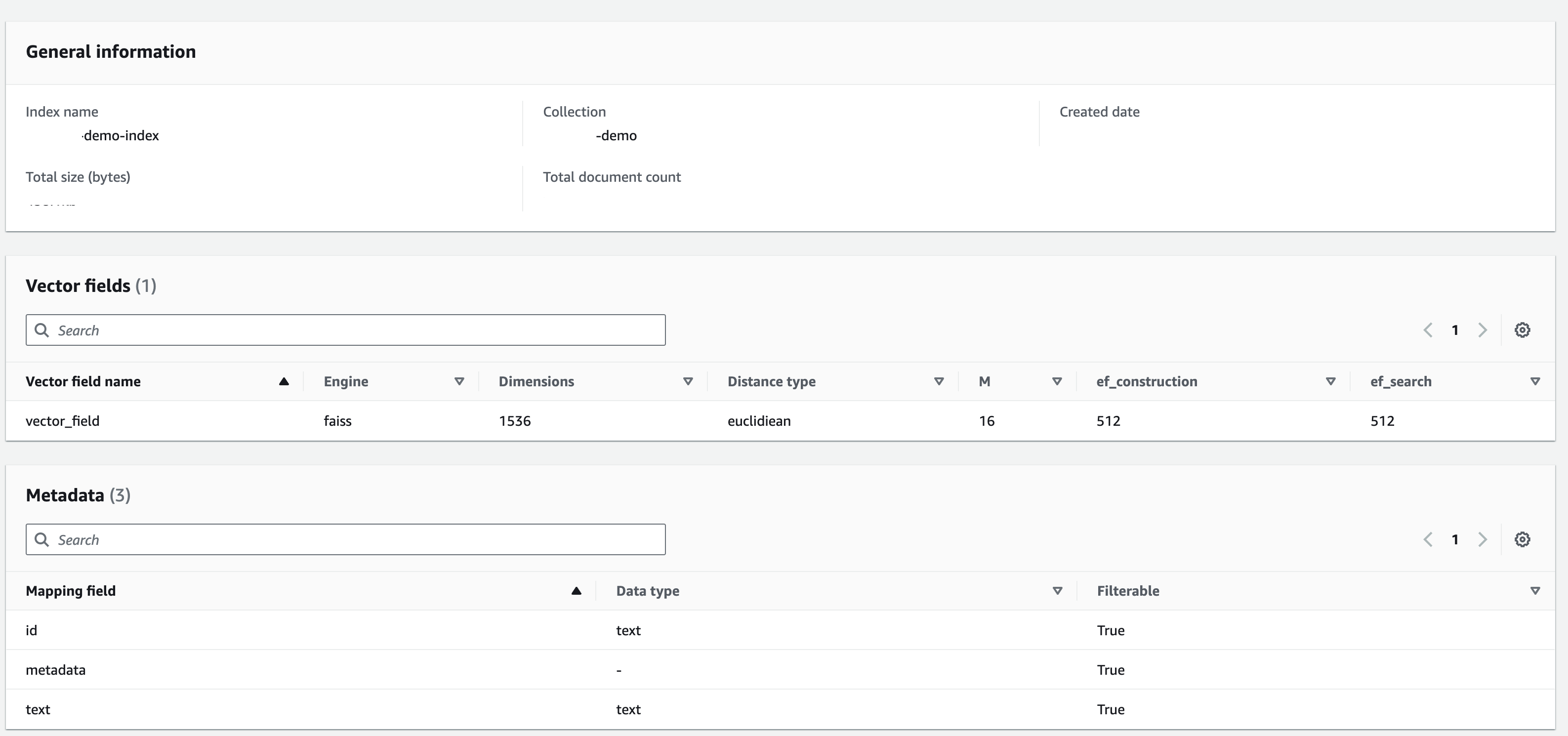
以下の構成でインデックスを作成します。
Amazon 2022 株主宛レターをダウンロードし、同じディレクトリに置きます。
.envファイルを作成し、Amazon OpenSearch セットアップに関する次の情報を指定します。
opensearch_index_name= ' '
opensearch_url= ' '
engine= ' faiss '
vector_field= ' vector_field '
text_field= ' text '
metadata_field= ' metadata 'ローカルマシンからアクセスできるように Amazon Bedrock が設定されていることを確認してください。また、Amazon Bedrock のamazon.titan-embed-text-v1埋め込みモデルとanthropic.claude-v2モデルにアクセスする必要があります。詳細については、次の手順に従ってください。
PDF データをロードします。
python3 -m venv myenv
source myenv/bin/activate
pip3 install -r requirements.txt
python3 load.pyOpenSearch コレクション内のデータを検証する
streamlit run app_semantic_search.py --server.port 8080次のような質問をすることができます。
What is Amazon ' s doing in the field of generative AI?
What were the key challenges Amazon faced in 2022?
What were some of the important investments and initiatives mentioned in the letter? 
別の端末で:
source myenv/bin/activate
streamlit run app_rag.py --server.port 8081次のような質問をすることができます。
What is Amazon ' s doing in the field of generative AI?
What were the key challenges Amazon faced in 2022?
What were some of the important investments and initiatives mentioned in the letter?