JoyVASA
1.0.0
曹徐陽1*王国信12*盛世 1*趙俊1楊堯1
ジンタオ・フェイ1ミンユ・ガオ1
1 JD Health International Inc. 2浙江大学
オーディオ主導のポートレート アニメーションは拡散ベースのモデルで大幅に進歩し、ビデオ品質とリップシンクの精度が向上しました。しかし、これらのモデルの複雑さの増大により、トレーニングと推論の非効率性が増し、ビデオの長さやフレーム間の連続性にも制約が生じています。この論文では、オーディオ駆動の顔アニメーションで顔のダイナミクスと頭の動きを生成するための拡散ベースの方法である JoyVASA を提案します。具体的には、最初の段階では、動的な顔の表情を静的な 3D の顔の表現から分離する、分離された顔の表現フレームワークを導入します。この分離により、システムは静的な 3D 顔表現を動的なモーション シーケンスと組み合わせて、より長いビデオを生成できるようになります。次に、第 2 段階では、キャラクターのアイデンティティとは無関係に、音声キューから直接モーション シーケンスを生成するように拡散トランスフォーマーがトレーニングされます。最後に、第 1 段階でトレーニングされたジェネレーターは、3D 顔表現と生成されたモーション シーケンスを入力として使用して、高品質のアニメーションをレンダリングします。 JoyVASA は、分離された顔の表現とアイデンティティに依存しないモーション生成プロセスにより、人間のポートレートを超えて動物の顔をシームレスにアニメーション化します。このモデルは、中国語のプライベート データと英語のパブリック データのハイブリッド データセットでトレーニングされ、多言語サポートが可能になります。実験結果により、私たちのアプローチの有効性が検証されました。今後の作業は、リアルタイム パフォーマンスの向上と表現制御の洗練に焦点を当て、ポートレート アニメーションにおけるフレームワークのアプリケーションをさらに拡大する予定です。
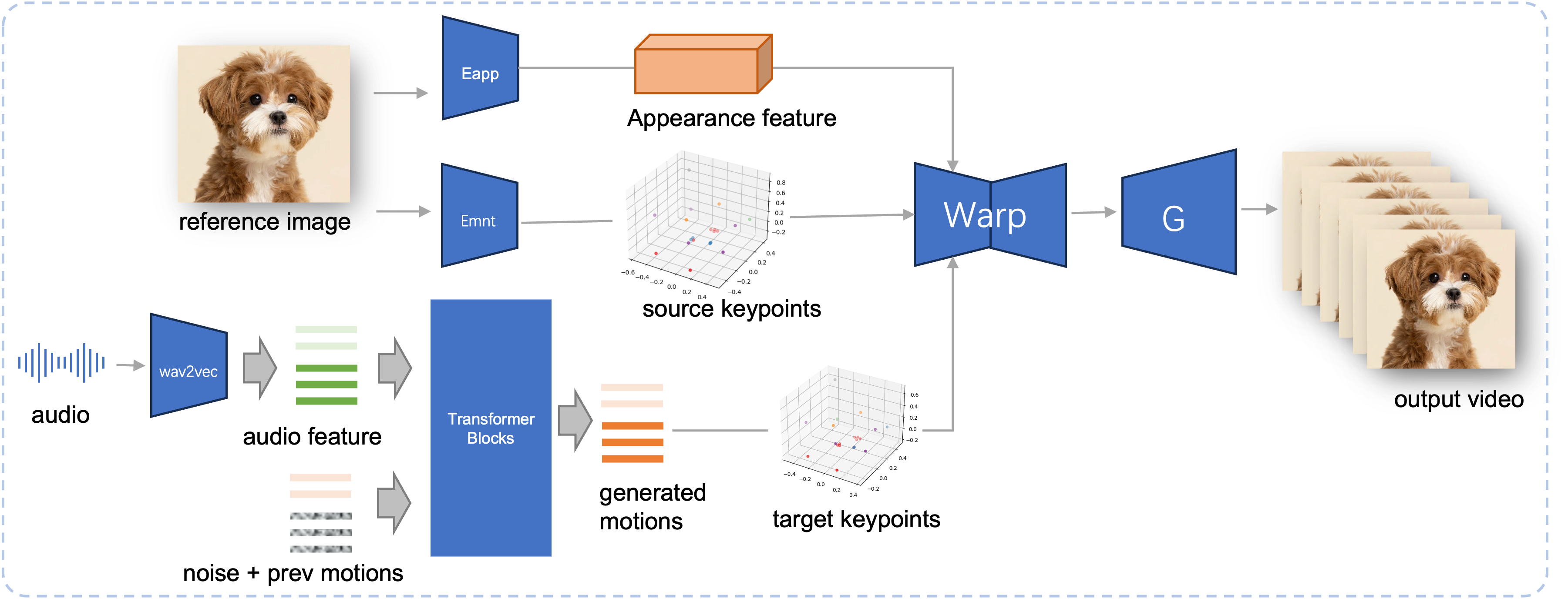
提案されている JoyVASA の推論パイプライン。参照画像が与えられると、最初に LivePortrait の外観エンコーダーを使用して 3D 顔の外観特徴を抽出し、さらにモーション エンコーダーを使用して一連の学習された 3D キーポイントを抽出します。入力音声の場合、最初に wav2vec2 エンコーダを使用してオーディオ特徴が抽出されます。次に、オーディオ主導のモーション シーケンスは、スライディング ウィンドウ方式で第 2 段階でトレーニングされた拡散モデルを使用してサンプリングされます。参照画像の 3D キーポイントとサンプリングされたターゲット モーション シーケンスを使用して、ターゲット キーポイントが計算されます。最後に、3D 顔の外観特徴がソース キーポイントとターゲット キーポイントに基づいてワープされ、ジェネレーターによってレンダリングされて、最終的な出力ビデオが生成されます。
システム要件:
Ubuntu:
Ubuntu 20.04、Cuda 11.3でテスト済み
テスト済みの GPU: A100
Windows:
Windows 11、CUDA 12.1でテスト済み
テスト済みの GPU: RTX 4060 ラップトップ 8GB VRAM GPU
環境を作成します。
# 1. 基本環境を作成するconda create -n Joyvasa python=3.10 -y conda はジョイヴァサを起動します # 2.requirementspip install -rrequirements.txtをインストールします# 3.ffmpegsudo apt-get updateをインストールします sudo apt-get install ffmpeg -y# 4. MultiScaleDeformableAttendancecd src/utils/dependency/XPose/models/UniPose/ops をインストールします。 python setup.py build installcd - # cd ../../../../../../../と等しい
git-lfs がインストールされていることを確認し、次のチェックポイントをすべてpretrained_weightsにダウンロードします。
git lfs インストール git clone https://huggingface.co/jdh-algo/JoyVASA
wav2vec2-base と Hubert-chinese を含む 2 種類のオーディオ エンコーダをサポートしています。
次のコマンドを実行して、hubert-chinese の事前トレーニング済み重みをダウンロードします。
git lfs インストール git clone https://huggingface.co/TencentGameMate/chinese-hubert-base
wav2vec2-base の事前トレーニングされた重みを取得するには、次のコマンドを実行します。
git lfs インストール git clone https://huggingface.co/facebook/wav2vec2-base-960h
注記
wav2vec2 エンコーダを使用したモーション生成モデルは今後サポートされる予定です。
# !pip install -U "huggingface_hub[cli]"huggingface-cli download KwaiVGI/LivePortrait --local-dir pretrained_weights --exclude "*.git*" "README.md" "docs"
その他のダウンロード方法については、ライブポートレートを参照してください。
pretrained_weights内容最終的なpretrained_weightsディレクトリは次のようになります。
./pretrained_weights/
├── insightface
│ └── models
│ └── buffalo_l
│ ├── 2d106det.onnx
│ └── det_10g.onnx
├── JoyVASA
│ ├── motion_generator
│ │ └── iter_0020000.pt
│ └── motion_template
│ └── motion_template.pkl
├── liveportrait
│ ├── base_models
│ │ ├── appearance_feature_extractor.pth
│ │ ├── motion_extractor.pth
│ │ ├── spade_generator.pth
│ │ └── warping_module.pth
│ ├── landmark.onnx
│ └── retargeting_models
│ └── stitching_retargeting_module.pth
├── liveportrait_animals
│ ├── base_models
│ │ ├── appearance_feature_extractor.pth
│ │ ├── motion_extractor.pth
│ │ ├── spade_generator.pth
│ │ └── warping_module.pth
│ ├── retargeting_models
│ │ └── stitching_retargeting_module.pth
│ └── xpose.pth
├── TencentGameMate:chinese-hubert-base
│ ├── chinese-hubert-base-fairseq-ckpt.pt
│ ├── config.json
│ ├── gitattributes
│ ├── preprocessor_config.json
│ ├── pytorch_model.bin
│ └── README.md
└── wav2vec2-base-960h
├── config.json
├── feature_extractor_config.json
├── model.safetensors
├── preprocessor_config.json
├── pytorch_model.bin
├── README.md
├── special_tokens_map.json
├── tf_model.h5
├── tokenizer_config.json
└── vocab.json注記
Windows のTencentGameMate:chinese-hubert-baseフォルダーの名前はchinese-hubert-baseに変更する必要があります。
動物:
python inference.py -r 資産/examples/imgs/joyvasa_001.png -a 資産/examples/audios/joyvasa_001.wav --animation_mode 動物 --cfg_scale 2.0
人間:
python inference.py -r 資産/examples/imgs/joyvasa_003.png -a 資産/examples/audios/joyvasa_003.wav --animation_mode human --cfg_scale 2.0
cfg_scale を変更すると、さまざまな表情やポーズの結果が得られます。
注記
アニメーション モードと参照イメージが一致しないと、不正確な結果が生じる可能性があります。
次のコマンドを使用して Web デモを開始します。
Python app.py
デモは http://127.0.0.1:7862 で作成されます。
私たちの取り組みが役立つと思われる場合は、私たちを引用することを検討してください。
@misc{cao2024joyvasaportraitanimalimage,
title={JoyVASA: Portrait and Animal Image Animation with Diffusion-Based Audio-Driven Facial Dynamics and Head Motion Generation},
author={Xuyang Cao and Guoxin Wang and Sheng Shi and Jun Zhao and Yang Yao and Jintao Fei and Minyu Gao},
year={2024},
eprint={2411.09209},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2411.09209},
}LivePortrait、Open Facevid2vid、InsightFace、X-Pose、DiffPoseTalk、Hallo、wav2vec 2.0、 Chinese Speech Pretrain、Q-Align、Syncnet、および VBench リポジトリへのオープンな研究と並外れた取り組みに感謝します。


