Adding Private Data to LLMs
1.0.0
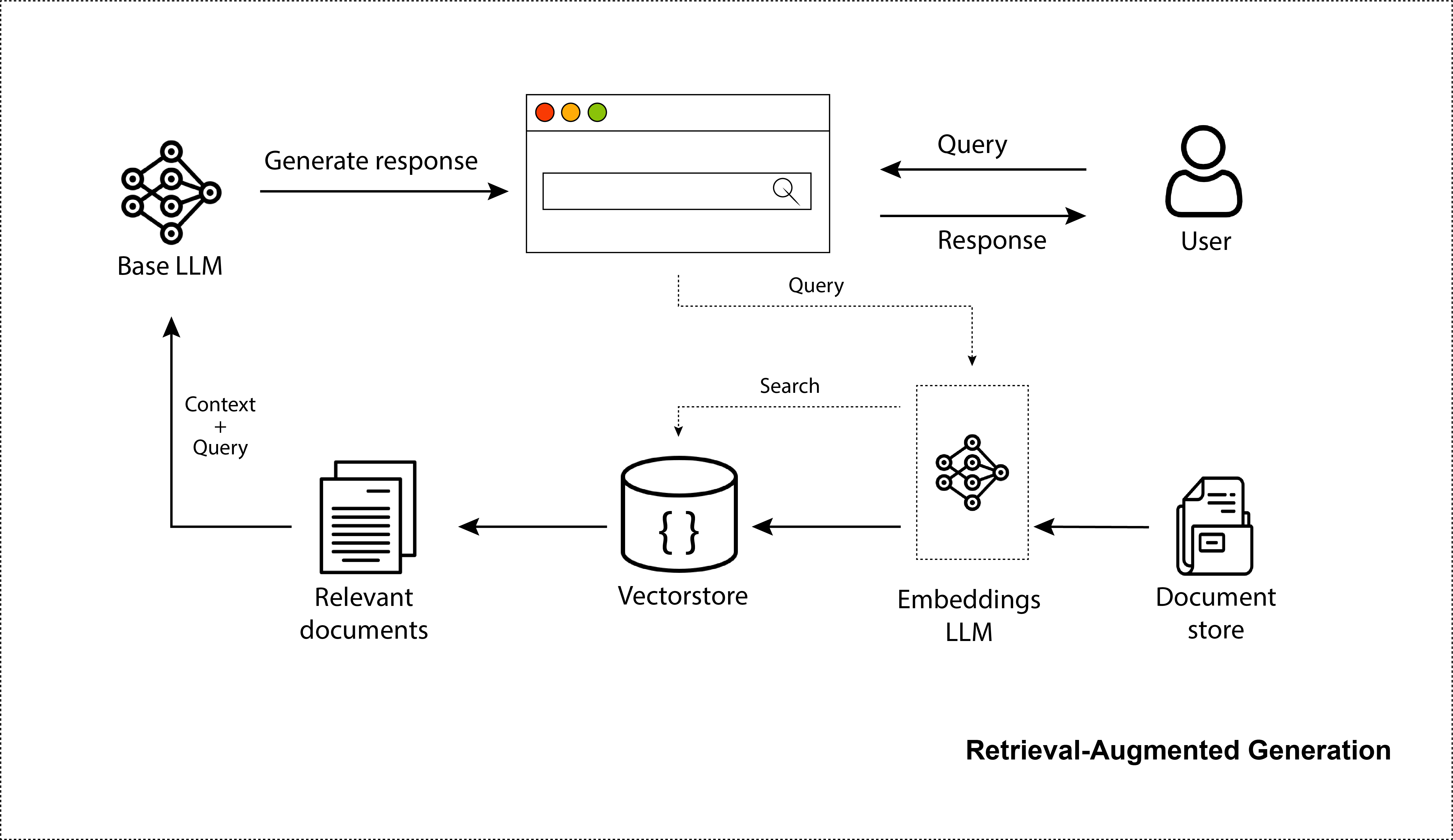
LLM は、リアルな画像、コード、対話を作成する能力で世界を驚かせてきました。 ChatGPT が世界を席巻したことは間違いありません。何百万もの人がそれを使用しています。ただし、汎用的な知識には優れていますが、認識できるのはトレーニングに基づいた情報、つまり 2021 年より前の一般に入手可能なインターネット データのみです。ユーザーの個人データに対する認識が欠如しており、最近のデータ ソースについての情報が得られないままです。したがって、その点で顧客を改善するために、検索ステップから取得した情報を顧客に提供できます。これにより、モデルがより事実に近くなり、これらの大規模なモデルを再トレーニングすることなく、モデルに最新の情報を提供できるようになります。これはまさに、検索拡張 LLM または検索拡張生成 (RAG) システムです。実際、このリポジトリでは、RAG システムの作成の概要が正確に説明され、関連する最適化手順が説明されます。
ラグ
技術スタック
インストール
役立つリンク
接触
ラングチェーン
ラマインデックス
Azure OpenAI
グラディオ
Github リポジトリのクローンを作成する
git clone https://github.com/zekaouinoureddine/Adding-Private-Data-to-LLMs.git
要件 プロジェクト ディレクトリに Cd し、Python 3 が必要な依存関係とともにインストールされていることを確認します。
cd LLM へのプライベート データの追加 pip install -r 要件.txt
Gradioアプリを実行する
Python rag.py
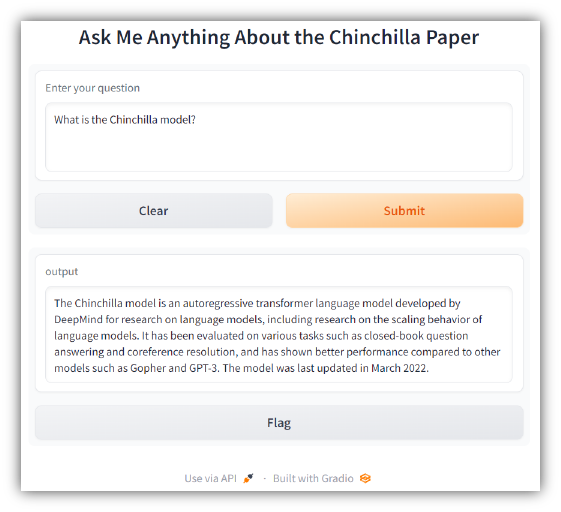
マシン上で http://127.0.0.1:7860 にアクセスして、アプリをテストします。次のようなものが表示されるはずです。
| ブログ | プレートフォーム | 言語 | ノート |
|---|---|---|---|
| 自分自身のデータに問いかける | ハイベラスのブログ | ES | |
| 自分自身のデータに問いかける | 中くらい | JP | |
| Web ページに質問する | ハイベラスのブログ | ES | |
| Web ページに質問する | 中くらい | JP |
気に入ったら、 を付けて、フォローしてください:
LinkedIn: ヌール・エディン・ゼカウイ
Twitter: @NZekaoui
トップに戻る


